RAG (Retrieval Augmented Generation) là gì? Cách hoạt động và ứng dụng thực tế
RAG (Retrieval Augmented Generation) là kỹ thuật tăng cường khả năng của các model ngôn ngữ lớn bằng cách tích hợp với nguồn dữ liệu bên ngoài, giải quyết ba vấn đề lớn: kiến thức lỗi thời, tạo thông tin sai và phản hồi chung chung. Bài viết giải thích RAG hoạt động như thế nào qua 5 bước cụ thể, từ thu thập dữ liệu đến tạo phản hồi, cùng ứng dụng thực tế và thách thức triển khai.
Tóm tắt các điểm chính
- RAG kết hợp khả năng tạo nội dung của LLM với cơ chế truy xuất thông tin chính xác từ nguồn dữ liệu bên ngoài như database, tài liệu và API
- Giải quyết ba giới hạn lớn của LLM: kiến thức hạn chế/lỗi thời (chỉ dựa vào dữ liệu huấn luyện), hallucinations (tạo thông tin nghe có vẻ đúng nhưng sai), và phản hồi chung chung thiếu ngữ cảnh cụ thể
- Năm bước hoạt động: thu thập dữ liệu, chia nhỏ thành chunks, chuyển thành vector embeddings, xử lý câu hỏi người dùng và tạo phản hồi với LLM
- Ứng dụng quan trọng: chatbot hỗ trợ khách hàng, tóm tắt báo cáo dài, đề xuất sản phẩm cá nhân hóa, và phân tích xu hướng thị trường tự động
- Ba thách thức chính: độ phức tạp tích hợp nhiều nguồn dữ liệu khác format, khả năng mở rộng khi dữ liệu tăng, và phụ thuộc nặng vào chất lượng dữ liệu đầu vào
RAG là gì?
Retrieval Augmented Generation (RAG) là kỹ thuật tăng cường các model ngôn ngữ lớn (LLM) bằng cách tích hợp chúng với nguồn dữ liệu bên ngoài. Bằng cách kết hợp khả năng tạo nội dung của các model như GPT-4 với cơ chế truy xuất thông tin chính xác, RAG cho phép các hệ thống AI tạo ra phản hồi chính xác và phù hợp ngữ cảnh hơn.
LLM rất mạnh mẽ nhưng đi kèm với những giới hạn vốn có:
Kiến thức hạn chế: LLM chỉ có thể tạo phản hồi dựa trên dữ liệu huấn luyện của chúng, có thể đã lỗi thời hoặc thiếu thông tin chuyên môn cụ thể.
Hallucinations: Các model này đôi khi tạo ra thông tin nghe có vẻ hợp lý nhưng không chính xác.
Phản hồi chung chung: Không có quyền truy cập vào nguồn bên ngoài, LLM có thể cung cấp câu trả lời mơ hồ hoặc không chính xác.
RAG giải quyết các vấn đề này bằng cách cho phép model truy xuất thông tin cập nhật và chuyên môn cụ thể từ các nguồn dữ liệu có cấu trúc và không có cấu trúc, chẳng hạn như cơ sở dữ liệu, tài liệu và API.
Tại sao sử dụng RAG để cải thiện LLM? Một ví dụ
Để minh họa rõ hơn RAG là gì và kỹ thuật này hoạt động như thế nào, hãy xem xét một tình huống mà nhiều doanh nghiệp ngày nay đối mặt.
Hãy tưởng tượng bạn là giám đốc điều hành của một công ty điện tử bán các thiết bị như điện thoại thông minh và laptop. Bạn muốn tạo chatbot hỗ trợ khách hàng cho công ty của mình để trả lời các câu hỏi của người dùng liên quan đến thông số kỹ thuật sản phẩm, khắc phục sự cố, thông tin bảo hành và nhiều hơn nữa.
Bạn muốn sử dụng khả năng của các LLM như GPT-3 hoặc GPT-4 để cung cấp sức mạnh cho chatbot của mình.
Tuy nhiên, các model ngôn ngữ lớn có những giới hạn sau, dẫn đến trải nghiệm khách hàng kém hiệu quả:
Thiếu thông tin cụ thể
Các model ngôn ngữ bị giới hạn trong việc cung cấp câu trả lời chung chung dựa trên dữ liệu huấn luyện của chúng. Nếu người dùng hỏi các câu hỏi cụ thể về phần mềm bạn bán, hoặc nếu họ có thắc mắc về cách thực hiện khắc phục sự cố sâu, một LLM truyền thống có thể không cung cấp câu trả lời chính xác.
Điều này là do chúng chưa được huấn luyện trên dữ liệu cụ thể cho tổ chức của bạn. Hơn nữa, dữ liệu huấn luyện của các model này có ngày cắt, hạn chế khả năng cung cấp phản hồi cập nhật của chúng.
Hallucinations
LLM có thể "hallucinate", có nghĩa là chúng có xu hướng tự tin tạo ra phản hồi sai dựa trên các sự kiện tưởng tượng. Các thuật toán này cũng có thể cung cấp phản hồi ngoài chủ đề nếu chúng không có câu trả lời chính xác cho câu hỏi của người dùng, dẫn đến trải nghiệm khách hàng tồi.
Phản hồi chung chung
Các model ngôn ngữ thường cung cấp phản hồi chung chung không được điều chỉnh theo ngữ cảnh cụ thể. Đây có thể là nhược điểm lớn trong tình huống hỗ trợ khách hàng vì sở thích người dùng cá nhân thường được yêu cầu để tạo điều kiện cho trải nghiệm khách hàng cá nhân hóa.
RAG lấp đầy những khoảng trống này một cách hiệu quả bằng cách cung cấp cho bạn cách tích hợp cơ sở kiến thức chung của LLM với khả năng truy cập thông tin cụ thể, chẳng hạn như dữ liệu có trong cơ sở dữ liệu sản phẩm và hướng dẫn sử dụng của bạn. Phương pháp này cho phép các phản hồi chính xác và đáng tin cậy cao được điều chỉnh theo nhu cầu của tổ chức bạn.
RAG hoạt động như thế nào?
Bây giờ bạn đã hiểu RAG là gì, hãy xem các bước liên quan đến việc thiết lập framework này:
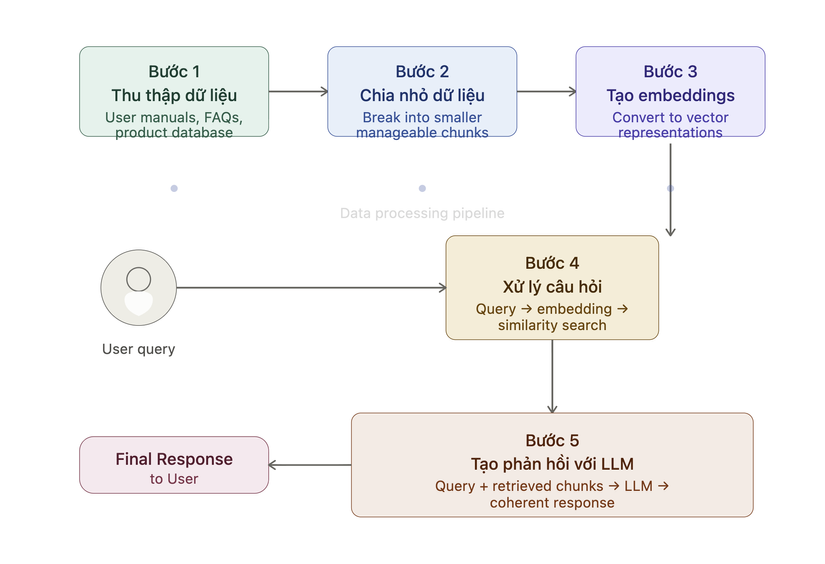
Bước 1: Thu thập dữ liệu
Trước tiên, bạn phải thu thập tất cả dữ liệu cần thiết cho ứng dụng của mình. Trong trường hợp chatbot hỗ trợ khách hàng cho công ty điện tử, điều này có thể bao gồm hướng dẫn sử dụng, cơ sở dữ liệu sản phẩm và danh sách câu hỏi thường gặp.
Bước 2: Chia nhỏ dữ liệu (data chunking)
Chia nhỏ dữ liệu là quá trình chia dữ liệu của bạn thành các phần nhỏ hơn, dễ quản lý hơn. Ví dụ, nếu bạn có hướng dẫn sử dụng dài 100 trang, bạn có thể chia nó thành các phần khác nhau, mỗi phần có khả năng trả lời các câu hỏi khác nhau của khách hàng.
Bằng cách này, mỗi phần dữ liệu tập trung vào một chủ đề cụ thể. Khi một phần thông tin được truy xuất từ bộ dữ liệu nguồn, nó có nhiều khả năng áp dụng trực tiếp cho câu hỏi của người dùng, vì chúng ta tránh bao gồm thông tin không liên quan từ toàn bộ tài liệu.
Điều này cũng cải thiện hiệu suất, vì hệ thống có thể nhanh chóng lấy các phần thông tin liên quan nhất thay vì xử lý toàn bộ tài liệu.
Bước 3: Tạo document embeddings
Bây giờ dữ liệu nguồn đã được chia nhỏ thành các phần nhỏ hơn, nó cần được chuyển đổi thành biểu diễn vector. Điều này liên quan đến việc chuyển đổi dữ liệu văn bản thành embeddings, là các biểu diễn số nắm bắt ý nghĩa ngữ nghĩa đằng sau văn bản.
Nói đơn giản, document embeddings cho phép hệ thống hiểu câu hỏi của người dùng và khớp chúng với thông tin liên quan trong bộ dữ liệu nguồn dựa trên ý nghĩa của văn bản, thay vì so sánh từ đơn giản từ-với-từ. Phương pháp này đảm bảo rằng các phản hồi có liên quan và phù hợp với câu hỏi của người dùng.
Bước 4: Xử lý câu hỏi người dùng
Khi câu hỏi của người dùng nhập vào hệ thống, nó cũng phải được chuyển đổi thành embedding hoặc biểu diễn vector. Cùng một model phải được sử dụng cho cả document và query embedding để đảm bảo tính đồng nhất giữa hai.
Khi câu hỏi được chuyển đổi thành embedding, hệ thống so sánh query embedding với document embeddings. Nó xác định và truy xuất các chunks có embeddings giống nhất với query embedding, sử dụng các phép đo như cosine similarity (độ tương đồng cosin) và Euclidean distance (khoảng cách Euclide).
Các chunks này được coi là phù hợp nhất với câu hỏi của người dùng.
Bước 5: Tạo phản hồi với LLM
Các text chunks được truy xuất, cùng với câu hỏi ban đầu của người dùng, được đưa vào model ngôn ngữ. Thuật toán sẽ sử dụng thông tin này để tạo phản hồi mạch lạc cho câu hỏi của người dùng thông qua giao diện chat.
Đây là sơ đồ đơn giản tóm tắt cách RAG hoạt động:
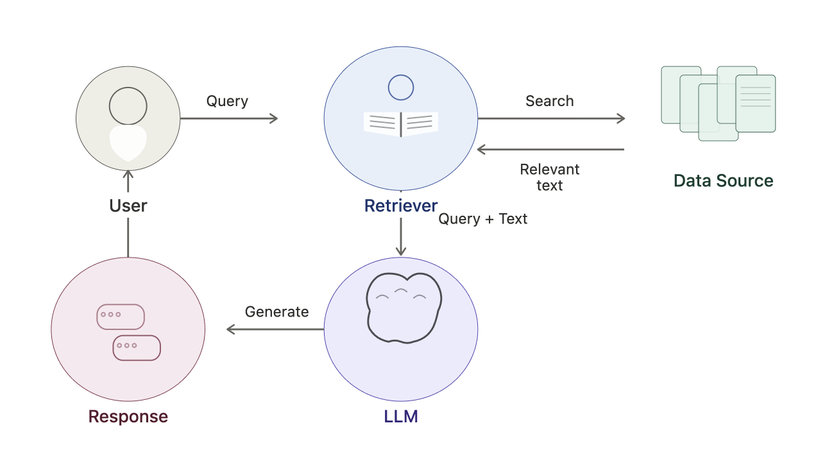
Để hoàn thành một cách liền mạch các bước cần thiết để tạo phản hồi với LLM, bạn có thể sử dụng framework dữ liệu như LlamaIndex.
Giải pháp này cho phép bạn phát triển ứng dụng LLM của riêng mình bằng cách quản lý hiệu quả luồng thông tin từ nguồn dữ liệu bên ngoài đến các model ngôn ngữ như GPT-3.
Ứng dụng thực tế của RAG
Bây giờ chúng ta biết rằng RAG cho phép LLM tạo phản hồi mạch lạc dựa trên thông tin ngoài dữ liệu huấn luyện của chúng. Một hệ thống như thế này có nhiều trường hợp sử dụng kinh doanh sẽ cải thiện hiệu suất tổ chức và trải nghiệm người dùng. Ngoài ví dụ chatbot khách hàng mà chúng ta đã thấy trước đó trong bài viết, đây là một số ứng dụng thực tế của RAG:
Tóm tắt văn bản
RAG có thể sử dụng nội dung từ các nguồn bên ngoài để tạo ra bản tóm tắt chính xác, dẫn đến tiết kiệm thời gian đáng kể. Ví dụ, các nhà quản lý và giám đốc điều hành cấp cao là những người bận rộn không có thời gian sàng lọc qua các báo cáo mở rộng.
Với một ứng dụng được hỗ trợ RAG, họ có thể nhanh chóng khai thác các phát hiện quan trọng nhất từ dữ liệu văn bản và đưa ra quyết định hiệu quả hơn thay vì phải đọc qua các tài liệu dài.
Đề xuất cá nhân hóa
Hệ thống RAG có thể được sử dụng để phân tích dữ liệu khách hàng, chẳng hạn như mua hàng trong quá khứ và đánh giá, để tạo đề xuất sản phẩm. Điều này sẽ tăng trải nghiệm tổng thể của người dùng và cuối cùng tạo ra nhiều doanh thu hơn cho tổ chức.
Ví dụ, các ứng dụng RAG có thể được sử dụng để đề xuất phim hay hơn trên các nền tảng streaming dựa trên lịch sử xem và xếp hạng của người dùng. Chúng cũng có thể được sử dụng để phân tích các đánh giá viết trên nền tảng thương mại điện tử.
Vì LLM xuất sắc trong việc hiểu ngữ nghĩa đằng sau dữ liệu văn bản, các hệ thống RAG có thể cung cấp cho người dùng các đề xuất cá nhân hóa có nhiều sắc thái hơn so với hệ thống đề xuất truyền thống.
Phân tích kinh doanh
Các tổ chức thường đưa ra quyết định kinh doanh bằng cách theo dõi hành vi đối thủ cạnh tranh và phân tích xu hướng thị trường. Điều này được thực hiện bằng cách phân tích tỉ mỉ dữ liệu có trong các báo cáo kinh doanh, báo cáo tài chính và tài liệu nghiên cứu thị trường.
Với một ứng dụng RAG, các tổ chức không còn phải phân tích và xác định xu hướng trong các tài liệu này theo cách thủ công. Thay vào đó, một LLM có thể được sử dụng để rút ra thông tin chi tiết có ý nghĩa một cách hiệu quả và cải thiện quá trình nghiên cứu thị trường.
Thách thức và thực hành tốt nhất khi triển khai hệ thống RAG
Mặc dù các ứng dụng RAG cho phép chúng ta lấp đầy khoảng trống giữa truy xuất thông tin và xử lý ngôn ngữ tự nhiên, việc triển khai chúng đặt ra một vài thách thức độc đáo. Trong phần này, chúng ta sẽ xem xét các độ phức tạp phải đối mặt khi xây dựng các ứng dụng RAG và thảo luận cách chúng có thể được giảm thiểu.
Độ phức tạp tích hợp
Có thể khó khăn để tích hợp hệ thống truy xuất với một LLM. Độ phức tạp này tăng lên khi có nhiều nguồn dữ liệu bên ngoài ở các định dạng khác nhau. Dữ liệu được đưa vào hệ thống RAG phải nhất quán, và các embeddings được tạo cần đồng nhất trên tất cả các nguồn dữ liệu.
Để vượt qua thách thức này, các module riêng biệt có thể được thiết kế để xử lý các nguồn dữ liệu khác nhau một cách độc lập. Dữ liệu trong mỗi module sau đó có thể được tiền xử lý để đồng nhất, và một model tiêu chuẩn hóa có thể được sử dụng để đảm bảo rằng các embeddings có định dạng nhất quán.
Khả năng mở rộng
Khi lượng dữ liệu tăng, việc duy trì hiệu suất của hệ thống RAG trở nên khó khăn hơn. Nhiều hoạt động phức tạp cần được thực hiện - chẳng hạn như tạo embeddings, so sánh ý nghĩa giữa các phần văn bản khác nhau và truy xuất dữ liệu trong thời gian thực.
Các tác vụ này tốn nhiều tính toán và có thể làm chậm hệ thống khi kích thước dữ liệu nguồn tăng lên.
Để giải quyết thách thức này, bạn có thể phân phối tải tính toán trên các máy chủ khác nhau và đầu tư vào cơ sở hạ tầng phần cứng mạnh mẽ. Để cải thiện thời gian phản hồi, có thể cũng có lợi khi lưu cache các câu hỏi được hỏi thường xuyên.
Việc triển khai cơ sở dữ liệu vector cũng có thể giảm thiểu thách thức khả năng mở rộng trong các hệ thống RAG. Các cơ sở dữ liệu này cho phép bạn xử lý embeddings dễ dàng và có thể nhanh chóng truy xuất các vector phù hợp nhất với mỗi câu hỏi.
Chất lượng dữ liệu
Hiệu quả của hệ thống RAG phụ thuộc rất nhiều vào chất lượng dữ liệu được đưa vào nó. Nếu nội dung nguồn được ứng dụng truy cập kém, các phản hồi được tạo ra sẽ không chính xác.
Các tổ chức phải đầu tư vào một quy trình tuyển chọn và tinh chỉnh nội dung siêng năng. Cần thiết phải tinh chỉnh các nguồn dữ liệu để nâng cao chất lượng của chúng. Đối với các ứng dụng thương mại, có thể có lợi khi có chuyên gia chủ đề xem xét và lấp đầy bất kỳ khoảng trống thông tin nào trước khi sử dụng bộ dữ liệu trong hệ thống RAG.
Kết luận
RAG hiện là kỹ thuật được biết đến nhiều nhất để tận dụng khả năng ngôn ngữ của LLM cùng với cơ sở dữ liệu chuyên biệt. Các hệ thống này giải quyết một số thách thức cấp bách nhất gặp phải khi làm việc với các model ngôn ngữ, và trình bày một giải pháp sáng tạo trong lĩnh vực xử lý ngôn ngữ tự nhiên.
Tuy nhiên, giống như bất kỳ công nghệ nào khác, các ứng dụng RAG có những giới hạn của chúng - đặc biệt là sự phụ thuộc của chúng vào chất lượng dữ liệu đầu vào. Để tận dụng tối đa các hệ thống RAG, điều quan trọng là phải bao gồm giám sát của con người trong quy trình.
Việc tuyển chọn tỉ mỉ các nguồn dữ liệu, cùng với kiến thức chuyên môn, là điều bắt buộc để đảm bảo độ tin cậy của các giải pháp này.
Câu hỏi thường gặp
RAG có thể truy xuất những loại dữ liệu nào?
RAG có thể truy xuất dữ liệu có cấu trúc và không có cấu trúc, bao gồm hướng dẫn sản phẩm, tài liệu hỗ trợ khách hàng, văn bản pháp lý và thông tin API thời gian thực.
RAG có thể được tích hợp với bất kỳ LLM nào không?
Có, RAG có thể được triển khai với nhiều model ngôn ngữ khác nhau, bao gồm các model GPT của OpenAI, các model dựa trên BERT và các kiến trúc transformer khác.
RAG có thể được sử dụng cho các ứng dụng thời gian thực không?
Có, RAG có thể được sử dụng trong các ứng dụng thời gian thực như chatbot dịch vụ khách hàng và trợ lý AI, nhưng hiệu suất phụ thuộc vào việc truy xuất và tạo phản hồi hiệu quả.
RAG so sánh như thế nào với việc tinh chỉnh một LLM?
RAG cung cấp cập nhật động mà không cần huấn luyện lại model, làm cho nó thích nghi hơn với thông tin mới, trong khi tinh chỉnh yêu cầu huấn luyện lại trên dữ liệu cụ thể.
RAG có yêu cầu loại cơ sở dữ liệu cụ thể để truy xuất không?
Không, RAG có thể làm việc với nhiều giải pháp lưu trữ dữ liệu khác nhau, bao gồm cơ sở dữ liệu SQL, cơ sở dữ liệu NoSQL và cơ sở dữ liệu vector như FAISS và Milvus.
Điều gì phân biệt RAG với công cụ tìm kiếm hoặc cơ sở dữ liệu truyền thống?
RAG kết hợp khả năng truy xuất của công cụ tìm kiếm với khả năng hiểu sắc thái và tạo phản hồi của các model ngôn ngữ, cung cấp câu trả lời nhận biết ngữ cảnh và chi tiết thay vì chỉ lấy tài liệu.
Nguồn: Infinity News — tạp chí trực tuyến đa chuyên mục tập trung vào khoa học, công nghệ, thị trường và đời sống, cung cấp tin tức cập nhật, phân tích chuyên sâu và bài viết hướng dẫn thực tiễn.
All rights reserved
