Qwen 3.5 Architecture vs Qwen 3
https://arxiv.org/pdf/2505.09388
https://www.sci-tech-today.com/news/alibaba-qwen3-5-397b-open-weight-ai/?utm_source=chatgpt.com
https://github.com/QwenLM/Qwen3.5
1. Overview
Qwen3.5 là thế hệ Large Language Model (LLM) mới do Alibaba Cloud phát triển, được thiết kế như một foundation model có thể được fine-tune hoặc instruction-tune cho nhiều tác vụ AI khác nhau, bao gồm reasoning, coding, agentic tasks và multimodal understanding.
So với các thế hệ trước trong dòng Qwen, Qwen3.5 không chỉ mở rộng quy mô tham số mà còn thay đổi đáng kể kiến trúc lõi, tập trung vào ba mục tiêu chính:
- High performance – đạt hiệu năng cao trên các benchmark reasoning, coding và multimodal tasks
- Compute efficiency – giảm chi phí suy luận thông qua kiến trúc sparse và attention hiệu quả
- Scalable context modeling – hỗ trợ ngữ cảnh cực dài lên tới hàng trăm nghìn đến hàng triệu token
Điểm đặc biệt của Qwen3.5 là việc kết hợp nhiều cơ chế kiến trúc mới như Gated Delta Networks (linear attention) và Sparse Mixture-of-Experts (MoE) quy mô rất lớn. Nhờ đó, mô hình có thể đạt năng lực suy luận ở cấp độ hàng trăm tỷ tham số nhưng với chi phí suy luận gần tương đương với mô hình nhỏ hơn nhiều.
Ngoài ra, Qwen3.5 được huấn luyện với multimodal data (text, image, video) và hỗ trợ hơn 200 ngôn ngữ, hướng tới việc trở thành nền tảng cho các hệ thống AI agents và reasoning systems trong các ứng dụng thực tế.
2. Qwen3 Architecture
Kiến trúc Qwen3 được xây dựng trên nền tảng decoder-only Transformer (link Transformer: https://web.stanford.edu/~jurafsky/slp3/8.pdf), kế thừa trực tiếp các nguyên lý thiết kế cốt lõi của dòng Qwen trước đây và các LLM hiện đại. Tuy nhiên, thay vì chỉ mở rộng theo hướng parameter scaling, Qwen3 được tái cấu trúc theo hướng reasoning-first architecture, trong đó khả năng suy luận, xử lý ngữ cảnh dài và kiểm soát chi phí suy luận được xem là mục tiêu thiết kế trung tâm. Trên nền Transformer chuẩn, Qwen3 mở rộng sang hai nhánh triển khai chính: Dense Transformer và Mixture-of-Experts (MoE), tạo nền tảng cho khả năng mở rộng linh hoạt và tối ưu tài nguyên. Qwen3 có các cải tiến kiến trúc quan trọng và ý nghĩa: Grouped Query Attention (GQA) , Rotary Positional Embedding (RoPE) mở rộng, RMSNorm thay cho LayerNorm, Feed-Forward Network với SwiGLU
(ảnh tham khảo: https://magazine.sebastianraschka.com/p/qwen3-from-scratch)
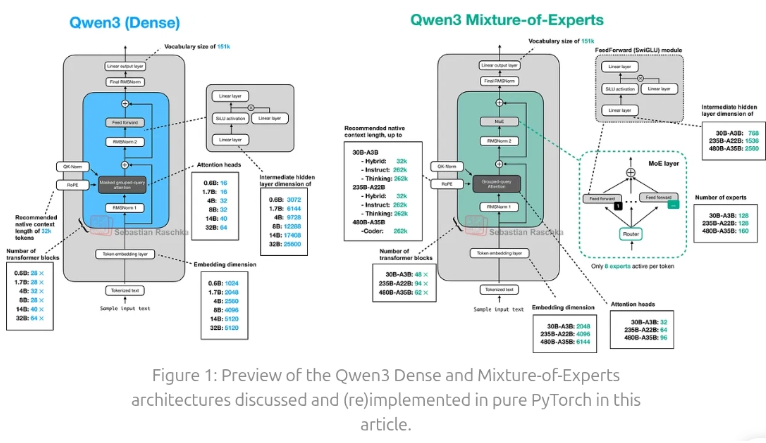
Qwen 3 có release 6 dense models : 0.6B, 1.7B, 4B, 8B, 14B, 32B, và 2 MoE (Mixture of Experts) models: 30B-A3B và 235B-A22B.
2.1 Embedding và Tokenizer
Lớp Embedding và Tokenizer của Qwen3 đóng vai trò then chốt trong việc xử lý đa ngôn ngữ và biểu diễn ngữ nghĩa của dữ liệu đầu vào.
Qwen3 tiếp tục sử dụng bộ mã hóa Byte-level Byte-Pair Encoding (BBPE) với từ vựng khổng lồ lên đến 151.669 token.
Điểm cải tiến vượt bậc của hệ thống này so với thế hệ tiền nhiệm (Qwen2.5) là việc mở rộng hỗ trợ từ 29 ngôn ngữ lên đến 119 ngôn ngữ và phương ngữ khác nhau, giúp tăng cường đáng kể khả năng hiểu và tạo văn bản đa văn hóa.
Về mặt kiến trúc, các mô hình có quy mô nhỏ (như 0.6B, 1.7B và 4B) được thiết kế theo cơ chế Tie Embedding (chia sẻ trọng số giữa lớp embedding đầu vào và đầu ra), trong khi các phiên bản lớn hơn từ 8B trở lên sử dụng các trọng số độc lập. Tùy thuộc vào kích thước mô hình, chiều của không gian embedding (embedding dimension) được cấu hình linh hoạt từ 1024 (đối với bản 0.6B) cho đến 5120 (đối với bản 14B và 32B), đảm bảo khả năng nén và trích xuất đặc trưng tối ưu cho từng mức ngân sách tính toán.
2.2 RMSNorm - Root Mean Square Normalization.
RMSNorm là một biến thể cải tiến của Layer Normalization (LayerNorm), được giới thiệu để tối ưu hóa tốc độ tính toán và sự ổn định của các mạng nơ-ron cực sâu như Transformer.
Các giá trị đầu vào (vector x) có thể thay đổi biên độ rất lớn (Internal Covariate Shift). Để mô hình học được, chúng ta cần đưa các giá trị này về một phân phối chuẩn.

2.3 Masked Grouped-Query Attention.
Theo sơ đồ kiến trúc của Qwen3, QK-Norm được đặt bên trong khối Masked Grouped-query Attention. Quy trình cụ thể là:
- Dữ liệu đi qua lớp RMSNorm 1 (Pre-normalization).
- Sau đó, tiến vào Attention Layer.
- Tại đây, vector Q và K được nhúng vị trí quay (RoPE) và ngay sau đó là lớp QK-Norm để chuẩn hóa biên độ trước khi tính toán ma trận chú ý
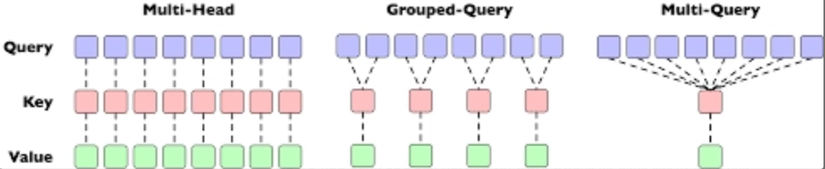
2.3.1 Attention Layer - Grouped Query Attention (GQA)
Qwen thay thế attention truyền thống bằng Grouped Query Attention, trong đó nhiều head truy vấn (query) dùng chung key–value
 💡
💡
Với Transformer Multi-Head có (Query head) sẽ đi kèm với một đầu khóa (Key head) và một đầu giá trị (Value head) riêng biệt → gây áp lực lên bộ nhớ khi mô hình mở rộng quy mô, đặt biệt là KV Cache (lưu trữ các vector Key và Value của các token trước đó để tăng tốc độ suy luận)
- Hỗ trợ ngữ cảnh cực dài: Kết hợp với GQA, Qwen3 sử dụng các kỹ thuật như YARN và Dual Chunk Attention (DCA) để mở rộng khả năng xử lý từ 32K token mặc định lên đến 1 triệu token.
- Tăng tốc độ suy luận (Inference Speed): Nhờ giảm lượng dữ liệu cần truy xuất từ bộ nhớ cho các đầu KV, tốc độ đọc/ghi được cải thiện, giúp mô hình phản hồi nhanh hơn.
- Giảm dấu chân bộ nhớ (Memory Footprint): Việc chia sẻ các đầu KV giúp giảm đáng kể kích thước của KV Cache. Điều này cực kỳ quan trọng khi xử lý các đầu vào dài, vì KV Cache thường là nút thắt cổ chai về bộ nhớ GPU.
Lợi ích của GQA trong Qwen3
- Cấu hình trong Qwen3: Qwen3 sử dụng kích thước mỗi đầu (head dimension) là 128. Ví dụ, phiên bản Qwen3-32B có 64 đầu Query nhưng chỉ được chia thành 8 nhóm, nghĩa là cứ 8 đầu Query sẽ dùng chung 1 bộ KV (tổng cộng có 8 đầu Key và 8 đầu Value). Phiên bản flagship Qwen3-235B thậm chí còn tinh gọn hơn với 64 đầu Query nhưng chỉ có 4 đầu KV.
- Chia sẻ bộ KV: Tất cả các Query trong cùng một nhóm sẽ dùng chung một đầu Key và một đầu Value duy nhất.
- Phân nhóm các Query: Thay vì mỗi Query có một bộ KV riêng, GQA chia các đầu Query thành nhiều nhóm.
Grouped-Query giải quyết vấn đề này bằng cách:
</aside> <aside> ☝Ví dụ đơn giản để hình dung phương pháp
Hãy tưởng tượng bạn đang điều hành một văn phòng tư vấn luật gồm 8 luật sư (tương ứng với 8 đầu Query):
- Multi-Head Attention (MHA): Mỗi luật sư có 1 thư ký riêng để tra cứu tài liệu (Key) và ghi chú (Value). → Vấn đề: Tốn quá nhiều tiền thuê chỗ ngồi (bộ nhớ GPU) cho 8 thư ký.
- Multi-Query Attention (MQA): Tất cả 8 luật sư dùng chung duy nhất 1 thư ký. → Vấn đề: Thư ký duy nhất này bị quá tải, thông tin cung cấp cho các luật sư bị trộn lẫn hoặc thiếu chi tiết (giảm độ chính xác của mô hình).
- Grouped Query Attention (GQA - Cách Qwen3 làm): Bạn chia 8 luật sư thành 2 nhóm (mỗi nhóm 4 người). Mỗi nhóm sẽ dùng chung 1 thư ký chuyên trách. →Kết quả: Bạn chỉ cần thuê 2 thư ký thay vì 8 (tiết kiệm bộ nhớ), nhưng chất lượng hỗ trợ vẫn tốt hơn nhiều so với việc chỉ có 1 thư ký cho tất cả (duy trì hiệu suất suy luận cao).
2.3.2. QK-Norm (Query-Key Normalization)
<aside> 💡QK-Norm là kỹ thuật áp dụng một lớp chuẩn hóa (thường là RMSNorm hoặc LayerNorm) trực tiếp lên các vector Query (Q) và Key (K) ngay trước khi thực hiện phép tính tích vô hướng (dot-product) trong cơ chế Attention.
Trong kiến trúc Transformer, AI tìm mối liên hệ giữa các từ bằng cách nhân hai giá trị Q (Câu hỏi) và K (Câu trả lời) với nhau.
- Cách làm cũ: Để Q và K tự do nhân với nhau. Số càng lớn, kết quả nhân ra càng "khủng khiếp", dễ gây lỗi.
- Cơ chế QK-Norm: Trước khi cho Q và K "gặp nhau" để nhân, QK-Norm đóng vai trò như một màng lọc chuẩn hóa. Nó ép các con số này quay về một khung chuẩn mực, nhỏ gọn và ổn định.
</aside>Ví dụ dễ hiểu: QK-Norm giống như một chiếc Ổn áp. Dù dòng điện đầu vào có trồi sụt hay tăng vọt thế nào, nó luôn điều chỉnh về đúng 220V ổn định trước khi đưa vào thiết bị điện.
2.3.3. RoPE(Rotary Positional Embeddings)
Fig 5 Rotary Positional Embeddings RoPE Source
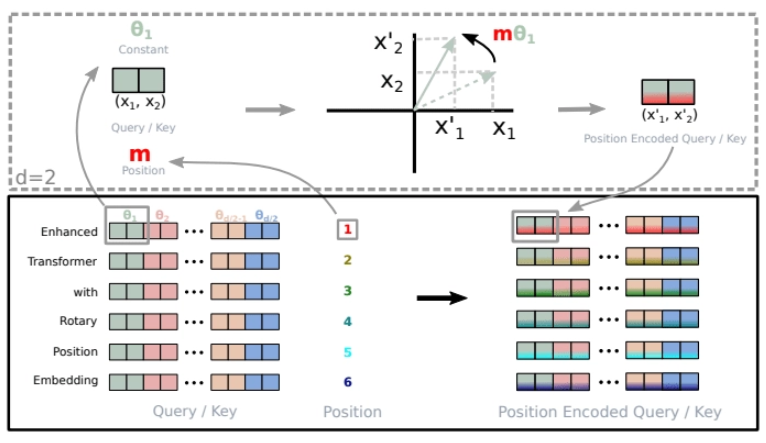
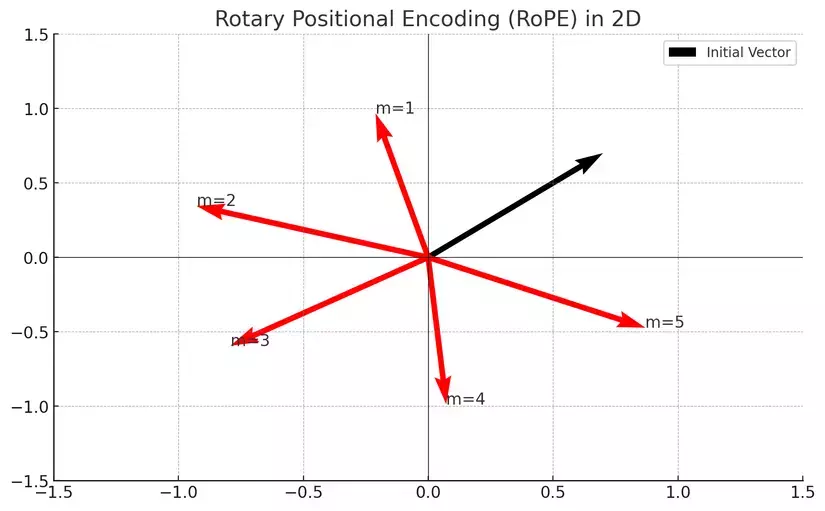
Trong kiến trúc của Qwen3, RoPE (Rotary Positional Embeddings) đóng vai trò là cơ chế mã hóa vị trí cốt lõi, giúp mô hình xác định thứ tự và khoảng cách giữa các token trong một chuỗi văn bản. Thay vì sử dụng các nhúng vị trí tuyệt đối truyền thống, RoPE nhúng thông tin vị trí bằng cách xoay các vector Query (Q) và Key (K) trong không gian vector trước khi tính toán ma trận chú ý
</aside>2.4. MoE (Mixture-of-Experts)
<aside> 💡Kiến trúc MoE là một dạng kích hoạt thưa (Sparse Activation). Thay vì bắt toàn bộ các nơ-ron trong mô hình phải làm việc với mọi từ ngữ, MoE chia nhỏ lớp Feed-forward (FFN) thành nhiều "chuyên gia" nhỏ hơn.
Cấu tạo của một khối MoE:
-
Các chuyên gia (Experts): Thay vì một lớp mạng nơ-ron khổng lồ, chúng ta có mạng nơ-ron nhỏ (ví dụ 16, 32 hoặc 64 chuyên gia). Mỗi chuyên gia này sẽ dần dần "giỏi" về một mảng kiến thức nhất định (toán học, mã code, ngữ pháp...).
-
Bộ định tuyến (Router/Gateway Network): Đây là thành phần quan trọng nhất. Khi một token (từ ngữ) đi vào, Router sẽ tính toán xác suất và quyết định gửi từ đó đến cho 1 hoặc 2 chuyên gia phù hợp nhất để xử lý.
-
Hợp nhất kết quả: Kết quả từ các chuyên gia được chọn sẽ được tổng hợp lại để đưa ra đầu ra cuối cùng.
$y = ∑(i = 1 → k) G(x)_i · E_i(x)$
2.4.1. Router
<aside> 👉Router là một mạng nơ-ron tuyến tính siêu nhỏ (Linear Layer) đi kèm với một hàm kích hoạt Softmax.
Quy trình xác định gồm 3 bước toán học:
Bước 1: Tính toán "Độ phù hợp" (Logits calculation)
Khi một token x (một dãy số biểu diễn từ ngữ) đi vào lớp MoE, Router sẽ thực hiện phép nhân ma trận giữa x và một bộ trọng số của riêng nó :
Kết quả h là một danh sách các con số (logits), mỗi con số đại diện cho một chuyên gia. Ví dụ nếu có 16 chuyên gia, danh sách sẽ có 16 số.
Bước 2: Chuyển sang xác suất (Softmax)
Router áp dụng hàm Softmax để biến các con số trên thành tỉ lệ phần trăm (tổng bằng 100%):
Lúc này, Router nhìn thấy: Chuyên gia số 1 hợp 80%, Chuyên gia số 5 hợp 15%, các chuyên gia khác chỉ 1-2%.
Bước 3: Lựa chọn Top-K (Gating)
Mô hình thường cấu hình chọn Top-1 hoặc Top-2.
- Nếu là Top-2, Router sẽ mở cửa cho token x đi vào Chuyên gia số 1 và số 5.
- Dữ liệu sẽ được nhân với trọng số tương ứng (ví dụ: 0.8 cho chuyên gia 1 và 0.15 cho chuyên gia 5) để đảm bảo kết quả cuối cùng có sự đóng góp đúng mức.
Làm sao Router "biết" chuyên gia nào giỏi môn gì?
Đây là điểm thú vị nhất: Lúc mới đầu, Router chẳng biết gì cả!
- Trong quá trình huấn luyện (Training), Router được học thông qua cơ chế Lan truyền ngược (Backpropagation).
- Nếu Router gửi một bài toán đến "nhóm chuyên gia văn học" và kết quả trả về bị sai (loss cao), hệ thống sẽ phạt Router.
- Ngược lại, nếu gửi đúng người và kết quả đúng, Router được thưởng.
- Sau hàng tỷ lần thử và sai, Router tự hình thành một "bản đồ nội bộ" để nhận diện đặc trưng của dữ liệu và gửi đến đúng nơi.
2.4.2. FeedForward
Đa số các mô hình hiện đại như Llama hay Qwen-3 không dùng FFN truyền thống (chỉ có 2 lớp tuyến tính) mà dùng biến thể SwiGLU. Một khối SwiGLU gồm3 Linear layers:
- Lớp Cổng (Gate Layer): Sử dụng hàm kích hoạt SiLU (Swish) để quyết định thông tin nào quan trọng.
- Lớp trung gian (Up-projection): Mở rộng số chiều dữ liệu lên rất lớn (thường gấp 3-4 lần Hidden size ban đầu). Đây là nơi mô hình "tiêu hóa" các đặc trưng phức tạp.
- Lớp đầu ra (Down-projection): Nén dữ liệu trở lại kích thước ban đầu để truyền sang lớp tiếp theo.
Tại sao Qwen-3 cần FeedForward?
- Lưu trữ tri thức (Knowledge Storage): Các nghiên cứu chỉ ra rằng phần lớn kiến thức về thế giới (sự thật, ngày tháng, khái niệm) được lưu trữ trong các trọng số của lớp FFN, chứ không phải ở lớp Attention.
- Tính phi tuyến tính (Non-linearity): Attention chỉ là các phép tính cộng/nhân trọng số. FFN thêm các hàm kích hoạt phi tuyến tính, giúp AI hiểu được các logic phức tạp và những mối quan hệ không thẳng hàng giữa các thông tin.
SwiGLU - Swish Gated Linear Unit.
Là một hàm kích hoạt phi tuyến được sử dụng trong các tầng feed-forward (FFN) của mô hình Transformer. Là sự cải tiến từ GLU - Gated Linear Unit, kết hợp với hàm swish để tăng khả năng biểu diễn phi tuyến và cải thiện hiệu suất mô hình. Đọc kỹ hơn về nó thì có thể đọc ở đây (Link)
3. Đột phá của Qwen 3.5
| Đặc điểm | Qwen3 | Qwen3.5 |
|---|---|---|
| Kiến trúc chính | Dense Transformer / Sparse MoE | **3:1 Hybrid Attention: |
3 × (Gated DeltaNet + MoE) 1 × (Gated Attention + MoE)** | | Cơ chế Attention | Grouped Query Attention (GQA) | Linear Attention (DeltaNet) | | Số lượng MoE | 128 | 512 | | Shared Expert | Không có | Có (1 Shared Expert) | | Loại hình mô hình | Ngôn ngữ (Hỗ trợ suy luận sâu) | Agent đa phương thức bản địa | | Hỗ trợ ngôn ngữ | 119 ngôn ngữ | 201+ ngôn ngữ |
Kiến trúc Hybrid đột phá Gated Delta Networks (DeltaNet)
Qwen3.5 thay thế cơ chế chú ý (attention) với độ phức tạp bình phương truyền thống bằng Attention tuyến tính (Linear Attention) thông qua DeltaNet. Điều này cho phép mô hình mở rộng độ dài ngữ cảnh với chi phí tính toán tăng theo cấp số tuyến tính thay vì lũy thừa, mang lại ưu thế tuyệt đối khi xử lý các tài liệu cực dài.
<aside> 👉Trong kiến trúc Transformer, cơ chế Self-Attention tính toán sự tương tác giữa mọi token với mọi token.
Giả sử chuỗi có độ dài n. Attention cần tính:
→ Ma trận: có kích thước: → ĐỘ PHỨC TẠP → KV cache rất lớn khi inference.
</aside> <aside> 👉Linear Attention giải quyết bằng cách factorize attention: → ĐỘ PHỨC TẠP
Linear attention có vấn đề:
1️⃣ memory representation yếu
2️⃣ khó xử lý retrieval tasks
3️⃣ context dài nhưng không nhớ chính xác token quan trọng
Do linear attention hoạt động giống: RNN state
</aside> <aside> 👉DeltaNet – Linear Attention cải tiến → giải quyết vấn đề Linear Attention
(DeltaNet được đề xuất trong paper: https://arxiv.org/abs/2406.06484)
Thay vì cập nhật memory state đơn giản:
DeltaNet dùng delta rule update:
Ý nghĩa:
S_t= memory statek_t= keyv_t= value
update: giống online learning
memory ← memory + correction
Gated Delta Networks (Gated DeltaNet)
Tham khảo: Gated Delta Networks: Improving Mamba2 with Delta Rule https://research.nvidia.com/publication/2025-04_gated-delta-networks-improving-mamba2-delta-rule?utm_source=chatgpt.com
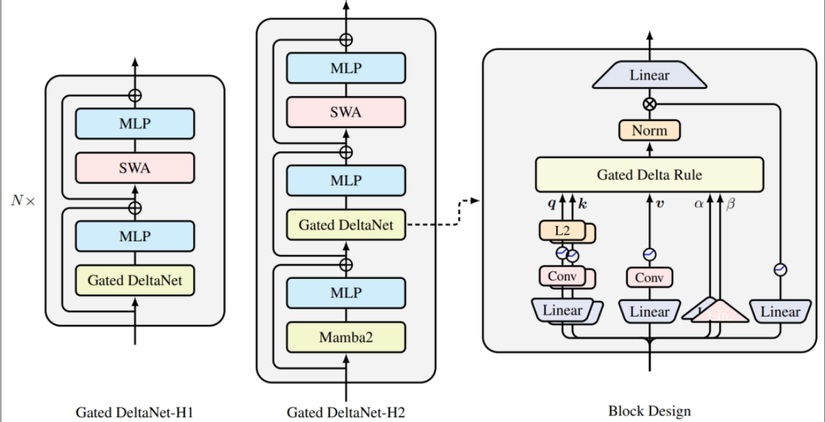
Hình thể hiện một hybrid architecture gồm nhiều loại layer:
| Module | Vai trò |
|---|---|
| Gated DeltaNet | linear attention memory layer |
| SWA | sliding window attention - attention chỉ tính trong window nhỏ → học local structure, bù cho weakness của linear attention. |
| Mamba2 | state-space sequence layer (State Space Model xuất phát từ control theory / dynamical systems.Nó mô tả một hệ thống có state (trạng thái) thay đổi theo thời gian.) Mamba2 là version cải tiến của Mamba giúp model dễ train như Transformer nhưng vẫn linear complexity . P*aper: https://arxiv.org/abs/2405.21060* |
| MLP | feed-forward layer |
Gated DeltaNet được thiết kế để giải quyết các hạn chế của mô hình Linear Transformer và Mamba2 trong việc truy xuất thông tin và xử lý ngữ cảnh dài. Nó kết hợp hai cơ chế bổ trợ cho nhau:
- Cơ chế Cổng (Gating): Cho phép kiểm soát bộ nhớ thích ứng, giúp mô hình có khả năng "xóa" bộ nhớ cũ một cách nhanh chóng khi không còn cần thiết.
- Quy tắc cập nhật Delta (Delta Rule): Cho phép thực hiện các thay đổi chính xác đối với bộ nhớ, giúp mô hình cập nhật thông tin mục tiêu một cách hiệu quả hơn.
- Chú ý tuyến tính (Linear Attention): Gated DeltaNet thay thế cơ chế chú ý có độ phức tạp bình phương (quadratic) truyền thống bằng cơ chế chú ý tuyến tính. Điều này giúp chi phí tính toán chỉ tăng theo tỷ lệ thuận với độ dài văn bản, thay vì tăng theo hàm mũ.
Sparse MoE (Mixture-of-Experts) quy mô lớn:
Trong khi Qwen3 (flagship 235B) sử dụng 128 chuyên gia, Qwen3.5 mở rộng lên tới 512 chuyên gia
| Model | Experts per layer | Active experts | Tổng params |
|---|---|---|---|
| Qwen3-235B | 128 | 8 | 235B |
| Qwen3.5-397B | 512 | 10 + 1 shared | 397B |
Cơ chế chuyên gia dùng chung (Shared Expert):
Khác với Qwen3 vốn loại bỏ hoàn toàn chuyên gia dùng chung, Qwen3.5 kích hoạt 11 chuyên gia mỗi token (gồm 10 chuyên gia được định tuyến và 1 chuyên gia dùng chung) để tăng cường khả năng lưu giữ kiến thức nền tảng
Code comparison Qwen3 vs Qwen3.5 model on a scoring conversation task
vllm serve Qwen/Qwen3-4B \
--port 8001 \
--gpu-memory-utilization 0.3 \
--max-model-len 32768 \
vllm serve Qwen/Qwen3.5-4B \
--port 8000 \
--gpu-memory-utilization 0.3 \
--max-model-len 32768 \
(GPU I USED : NVIDIA RTX PRO 6000 Blackwell
VRAM: 96 GB GDDR7 ECC)
PROMPT.md
Bạn là một chuyên gia Kiểm soát chất lượng (QA) tổng đài. Nhiệm vụ của bạn là đánh giá đoạn hội thoại giữa Nhân viên (NV) và Khách hàng (KH) dựa trên bộ tiêu chí được cung cấp.
(Khách hàng cúp máy trước)[BỘ TIÊU CHÍ CHẤM ĐIỂM]:
1. Nhóm Nghiệp Vụ (Max 40đ):
- accuracy (Max 15đ): Thông tin chính xác (Đúng/đủ: 15đ, Đủ cơ bản: 7đ, Thiếu: 0đ).
- customer_verification (Max 15đ): Gọi cho số khác phải hỏi CCCD (Đủ/nhanh: 15đ, Thiếu: 7đ, Không hỏi: 0đ).
- system_entry (Max 10đ): Nhập Ticket/BO (Có nhắc đến việc nhập: 10đ, Sai/thiếu: 0đ).
2. Nhóm Kỹ Năng (Max 10đ):
- greeting_closing (Max 2đ): Có chào đầu/chào kết và hỏi thêm yêu cầu (Có: 2đ, Không: 0đ).
- hold_process (Max 2đ): Xin phép giữ máy, hold <=30s, cảm ơn sau hold (Đầy đủ: 2đ, Lỗi 1 phần: 1đ, Lỗi nặng: 0đ).
- communication_quality (Max 6đ): Dùng kính ngữ "dạ/vâng/ạ", không nói lóng, phản hồi tốt (Tốt: 6đ, Vi phạm ít: 3đ, Vi phạm nhiều: 0đ).
3. Nhóm Thái Độ (Max 50đ):
- service_attitude (Max 40đ): Thái độ tôn trọng, có đồng cảm, không cãi/đổ lỗi KH (Tốt: 40đ, Vi phạm: 0đ).
- professional_language (Max 5đ): Không chửi thề, đe dọa (Đạt: 5đ, Không: 0đ).
- no_early_hangup (Max 5đ): Không cúp máy trước KH (Đạt: 5đ, Không: 0đ).[ĐỊNH DẠNG ĐẦU RA YÊU CẦU (JSON)]:
Trast lại cấu trúc JSON sau, điền điểm số (score) và lý do chấm (reason) dựa trên phân tích hội thoại.
{
"evaluation_result": {
"business_knowledge": {
"accuracy": { "score": 0.0, "reason": "..." },
"customer_verification": { "score": 0.0, "reason": "..." },
"system_entry": { "score": 0.0, "reason": "..." }
},
"communication_skills": {
"greeting_closing": { "score": 0.0, "reason": "..." },
"hold_process": { "score": 0.0, "reason": "..." },
"communication_quality": { "score": 0.0, "reason": "..." }
},
"attitude_sentiment": {
"service_attitude": { "score": 0.0, "reason": "..." },
"professional_language": { "score": 0.0, "reason": "..." },
"no_early_hangup": { "score": 0.0, "reason": "..." }
},
"total_score": 0.0
}
}
import requests
import json
import time
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.messages import HumanMessage
# URL API của bạn (thay đổi port nếu cần)
API_URL_QWEN35 = "http://localhost:8000/v1/chat/completions"
API_URL_QWEN3 = "http://localhost:8001/v1/chat/completions"
# 1. Đoạn hội thoại mẫu giữa Nhân viên (NV) và Khách hàng (KH)
conversation = """
[00:02 : 00:03] Khách hàng: Alo.
[00:03 : 00:08] Khách hàng: Em hỏi chăm sóc khách hàng xin nhé.
[00:08 : 00:20] Khách hàng: Chị ơi cho em hỏi sao cái số điện thoại em đang gọi lên tổng đài ấy và em đăng ký ngày cần 56 ghi mà sao em không vào được mạng ạ?
[00:20 : 00:24] Khách hàng: Sao em không vào được mạng ạ.
[00:21 : 00:21] Nhân viên: Chị đang ở tỉnh nào đấy ạ?
[00:24 : 00:25] Khách hàng: Dạ, em ở Hưng Yên ạ.
[00:26 : 00:27] Nhân viên: Ở đấy có tiện không chị nhở?
[00:27 : 00:30] Khách hàng: Không nó tiện chị bình thường.
[00:30 : 00:30] Nhân viên: Dạ vâng.
[00:32 : 00:37] Nhân viên: Số đang gọi vậy cho em chút nhé, để em xem đã.
[00:37 : 00:38] Khách hàng: Dạ vâng.
[00:39 : 00:41] Khách hàng: Chẳng vào được mạng vào ngày 12 thi.
[01:00 : 01:01] Nhân viên: Alo ạ.
[01:01 : 01:02] Khách hàng: Dạ, alo ạ.
[01:02 : 01:05] Nhân viên: Số này của chị em lấy là vẫn đang bình thường.
[01:05 : 01:06] Nhân viên: Có tận 14 ghi trên ngày cơ.
[01:06 : 01:13] Nhân viên: Thì trên thông tin này của chị thì khi mà kết nối ạ thì điện thoại của chị có để chế độ tiết kiệm pin không?
[01:14 : 01:15] Khách hàng: Dạ em không ạ.
[01:18 : 01:20] Nhân viên: Chị có cài 1.1.1.1.1 trong máy không?
[01:21 : 01:21] Khách hàng: Không ạ.
[01:24 : 01:26] Khách hàng: Dạ em em không vào được mạng luôn á.
[01:47 : 01:51] Khách hàng: Chị kiểm tra giúp em xem nào sau em chẳng vào được ấy.
[01:51 : 01:52] Khách hàng: Vào wifi em vẫn vào bình thường.
[02:03 : 02:03] Khách hàng: Chị kiểm tra xem chưa ạ?
[02:10 : 02:11] Nhân viên: Chờ em một chút để em đi reset lại kết nối cho chị nhé.
[02:12 : 02:13] Khách hàng: Dạ, vâng, vâng.
"""
# 2. Tạo câu lệnh (Prompt) yêu cầu AI xử lý
with open("PROMPT.md", "r", encoding="utf-8") as f:
prompt = f.read()
payload_QWEN35 = {
"model": "Qwen/Qwen3.5-4B",
"messages":[
{
"role": "system",
"content": "Bạn là một chuyên gia quản lý chất lượng dịch vụ chăm sóc khách hàng (QA/QC). Answer directly and concisely. Do not explain your reasoning."
},
{
"role": "user",
"content": prompt + "hãy giúp tôi đánh giá cuộc hội thoại: " + conversation
}
],
"temperature": 0.5,
# "chat_template_kwargs": { "enable_thinking": False }
}
payload_QWEN3 = {
"model": "Qwen/Qwen3-4B-Instruct-2507",
"messages":[
{
"role": "system",
"content": "Bạn là một chuyên gia quản lý chất lượng dịch vụ chăm sóc khách hàng (QA/QC)."
},
{
"role": "user",
"content": prompt + "hãy giúp tôi đánh giá cuộc hội thoại: "+ conversation
}
],
"temperature": 0.5,
}
headers = {
"Content-Type": "application/json"
}
# 4. Gửi Request và in kết quả
print("Đang gửi yêu cầu tới model...")
start_time = time.time()
response_QWEN35 = requests.post(API_URL_QWEN35, headers=headers, json=payload_QWEN35)
end_time = time.time()
print(f"Thời gian phản hồi từ Qwen3.5: {end_time - start_time:.2f} giây")
start_time = time.time()
response_QWEN3 = requests.post(API_URL_QWEN3, headers=headers, json=payload_QWEN3)
end_time = time.time()
print(f"Thời gian phản hồi từ Qwen3: {end_time - start_time:.2f} giây")
if response_QWEN35.status_code == 200:
result = response_QWEN35.json()
ai_response = result["choices"][0]["message"]["content"]
print("\n========== ĐÁNH GIÁ TỪ AI QWEN35 ==========\n")
print(ai_response)
print("\n======================================")
if response_QWEN3.status_code == 200:
result = response_QWEN3.json()
ai_response = result["choices"][0]["message"]["content"]
print("\n========== ĐÁNH GIÁ TỪ AI QWEN3 ==========\n")
print(ai_response)
print("\n======================================")
else:
print(f"Lỗi kết nối (Mã lỗi: {response_QWEN3.status_code})")
print(response_QWEN3.text)
4. So sánh Qwen3-4b với Gemma3-4b
Link tham khảo:
https://arxiv.org/pdf/2505.09388
https://arxiv.org/abs/2503.19786
- Kiến trúc và Cơ chế vận hành
| Đặc điểm | Qwen3-4B | Gemma 3-4B |
|---|---|---|
| Loại mô hình | Ngôn ngữ thuần túy (Text-only LLM) | Đa phương thức bản địa (Native Multimodal) |
| Số tham số | 4,02 tỷ | 4,01 tỷ (gồm 3,2B tham số ngôn ngữ) |
| Cơ chế Attention | Grouped Query Attention (GQA) tiêu chuẩn | Interleaved Attention (Xen kẽ 5 lớp Local : 1 lớp Global) |
| Chế độ đặc biệt | Thinking Mode: Tích hợp suy luận (thinking) và phản hồi nhanh (non-thinking) trong cùng 1 mô hình | Vision Understanding: Hiểu hình ảnh trực tiếp thông qua SigLIP vision encoder tích hợp sẵn |
| Độ dài ngữ cảnh | 128K token (có thể mở rộng lên 1 triệu) | 128K token |
2. Hiệu năng qua các bài kiểm tra (Benchmarks)
Dựa trên kết quả so sánh các mô hình cơ sở (Base/PT), Qwen3-4B thể hiện ưu thế vượt trội về khả năng suy luận văn bản và toán học:
- Kiến thức tổng quát (MMLU): Qwen3-4B (72.99) cao hơn đáng kể so với Gemma 3-4B (59.51).
- Toán học (GSM8K & MATH):
- Trên GSM8K, Qwen3-4B đạt 87.79, vượt xa Gemma 3-4B (43.97).
- Trên MATH, Qwen3-4B đạt 54.10, trong khi Gemma 3-4B đạt 26.10.
- Lập trình (EvalPlus): Qwen3-4B (63.53) dẫn trước Gemma 3-4B (43.23).
- Đa ngôn ngữ (MGSM): Qwen3-4B (67.74) vượt trội so với Gemma 3-4B (33.11) trong các tác vụ toán đa ngôn ngữ.
3. Khả năng đa phương thức và Đa ngôn ngữ
- Đa phương thức: Gemma 3-4B có lợi thế tuyệt đối khi hỗ trợ đầu vào là hình ảnh (normalized 896x896) và tạo ra phân tích văn bản từ ảnh. Qwen3-4B là mô hình văn bản, dù quy trình huấn luyện của nó có sử dụng dữ liệu trích xuất từ PDF bởi mô hình VL khác.
- Đa ngôn ngữ:
- Qwen3-4B hỗ trợ 119 ngôn ngữ và phương ngữ, tập trung sâu vào khả năng suy luận và dịch thuật chéo ngôn ngữ.
- Gemma 3-4B được huấn luyện trên 140 ngôn ngữ và hỗ trợ tốt cho hơn 35 ngôn ngữ "out of the box" trong chế độ IT.
All Rights Reserved
