Query được xử lý như thế nào?
Mở đầu
Hằng ngày, hàng triệu cuộc trò chuyện diễn ra trên thế giới — mỗi ngôn ngữ đều có quy tắc riêng để người nghe hiểu được ý người nói. Database cũng vậy. Nó có một "ngôn ngữ" riêng để giao tiếp với chúng ta: Query.
Và cũng có thể một ngày đẹp trời, câu query vẫn chạy tốt bỗng dưng chậm đi gấp 10 lần — và bạn không biết tại sao.
Vậy khi bạn gửi một câu query, Database xử lý nó như thế nào?
👋 Hi các bạn!
Mình là Luân a.k.a Jarzt — Software Engineer. Ngoài việc code, cày game và chơi bóng rổ, mình còn thích viết lách — chia sẻ những thứ hay ho mà mình học được. Theo dõi mình tại LinkedIn nhé!
Database đọc hiểu Query thế nào?
Để Database hiểu được câu query, nó sẽ trải qua 4 bước chính:
- Parsing — Đọc hiểu câu query
- Binding — Liên kết với dữ liệu thực
- Optimizer — Tìm cách thực thi tối ưu
- Execution — Thực thi và trả kết quả
Trước khi đi vào chi tiết, mình sẽ setup sẵn dữ liệu và câu query trên nền Postgresql để các bạn có thể chạy thử.
-
Chuẩn bị dữ liệu
- Bạn có thể chạy demo tại: onecompiler.com/postgresql
- sql:
-- 1. Create Table users CREATE TABLE users ( id SERIAL PRIMARY KEY, name VARCHAR(100), age INT ); -- 2. Insert 1000 rows -- 100 users with age from 20-30 (10%) -- 900 users with age from 10-19 (90%) -- Group 1: 100 adults (age 20-30) INSERT INTO users (name, age) SELECT 'Adult_' || i, 20 + (i % 11) -- age: 20, 21, 22... 30 FROM generate_series(1, 100) AS i; -- Group 2: 900 teenagers (age 10-19) INSERT INTO users (name, age) SELECT 'Teen_' || i, 10 + (i % 10) -- age: 10, 11, 12... 19 FROM generate_series(1, 900) AS i; -
Câu query mẫu
Xuyên suốt bài viết, mình sẽ dùng câu query này để minh họa:
SELECT name FROM users WHERE age > 25 and age < 30;
Câu query này có nghĩa là
Cho tôi biết tên những khách hàng có độ tuổi từ 26 đến 29.
Ta có thể hiểu là:
SELECT name = Cho tôi biết tên FROM users = Những khách hàng WHERE age > 25 and age < 30 = Có độ tuổi từ 26 đến 29
Okay, ta sẽ đi vào chi tiết các database hoạt động
1. Parsing
Đây là bước Database "đọc hiểu" câu query của bạn.
1.1. Tokenization — Phân tách thành từng "từ”
Giống như khi bạn đọc một câu văn, bạn cần tách câu thành từng từ riêng biệt để hiểu nghĩa. Database cũng vậy.
Bước này sẽ tách câu query thành các token — những đơn vị nhỏ nhất có nghĩa.
Với câu query:
SELECT name FROM users WHERE age > 25 AND age < 30;
Database sẽ tách thành:
flowchart TB
Query["SELECT name FROM users WHERE age > 25 AND age < 30"]
Query --> SELECT
Query --> name
Query --> FROM
Query --> users
Query --> WHERE
Query --> age1["age"]
Query --> op1[">"]
Query --> val1["25"]
Query --> AND
Query --> age2["age"]
Query --> op2["<"]
Query --> val2["30"]
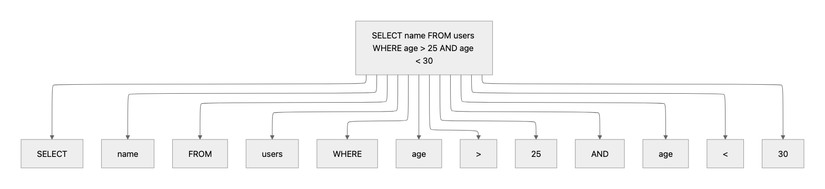
Sau khi tách xong, Database sẽ chuyển các tokens này sang bước tiếp theo.
1.2. Syntax Analysis — Kiểm tra ngữ pháp
Ở bước này, Database sẽ kiểm tra xem câu query của bạn có viết đúng "ngữ pháp" không.
Vậy Database kiểm tra gì?
1. Chính tả các từ khóa
Các từ khóa như SELECT, FROM, WHERE có được viết đúng không?
SELECThaySELCT?WHEREhayWHRE?
2. Thứ tự các phần
-
Query có quy tắc thứ tự cố định:
SELECT → columns → FROM → table → [WHERE → condition]
-
Ví dụ các query vi phạm:
-
FROMđứng trướcSELECT:FROM users SELECT name; -- Error: syntax error at or near "FROM" -
Thiếu columns giữa
SELECTvàFROM:SELECT FROM users; -- Error: syntax error at or near "FROM"
-
Sau khi, Database đã kiểm tra xong ngữ pháp, Database sẽ chuyển sang bước tiếp theo
1.3. Parse Tree — Chuyển thành cấu trúc dữ liệu
Sau khi kiểm tra ngữ pháp xong, Database sẽ chuyển câu query thành một dữ liệu có cấu trúc gọi là Tree (cây).
Tại sao lại là Tree? Vì nó giúp Database "nhìn" được mối quan hệ giữa các thành phần trong câu query.
Với câu query của chúng ta:
SELECT name FROM users WHERE age > 25 AND age < 30;
Database sẽ chuyển thành dạng giống như này
Query
│
├── SELECT
│ └── name
│
├── FROM
│ └── users
│
└── WHERE
├── age > 25
│
├── AND
│
└── age < 30
Hãy tưởng tượng Parse Tree như một sơ đồ tổ chức công ty:
- Cấp cao nhất là các "phòng ban" chính:
SELECT,FROM,WHERE - Cấp thấp hơn là "nhân viên" thuộc từng phòng ban:
namethuộcSELECT,usersthuộcFROM
Database sẽ đọc cây này từ trên xuống. Tới mỗi nhánh, nó xử lý nhánh đó trước, rồi đi sâu vào các nhánh con bên trong. Cứ thế cho đến khi duyệt hết toàn bộ cây.
Cấu trúc này giúp Database "nhìn" được mối quan hệ giữa các thành phần — biết name là cột cần lấy, users là bảng cần truy vấn, và age > 25 AND age < 30 là điều kiện lọc.
Vậy là xong bước 1. Tiếp theo, Database sẽ bước sang giai đoạn thứ 2: Binding.
2. Binding
Ở bước này, Database sẽ bắt đầu "ảo thuật" — liên kết các thành phần trong "cây" sang một thứ có nghĩa hơn bên trong Database.
Nếu Parsing là bước "đọc chữ", thì Binding là bước "hiểu nghĩa".
Database sẽ tra cứu System Catalog (cuốn sổ ghi chép tất cả thông tin về tables, columns, data types...) để xác minh những gì bạn viết có thực sự tồn tại hay không.
2.1. Name resolution - Giải mã tên
Database sẽ kiểm tra xem name, users, age có thực sự tồn tại không.
1. Database kiểm tra bảng users có tồn tại trong hệ thống không?
2. Bảng users có cột name không?
3. Tương tự với cột age trong mệnh đề WHERE.
2.2. Datatype Check — Kiểm tra kiểu dữ liệu
Database sẽ kiểm tra xem các phép so sánh có "hợp lý" về mặt kiểu dữ liệu không. Quay lại ví dụ:
WHERE age > 25 and age < 30
Database sẽ hỏi:
- Cột
agecó kiểu gì? →INTEGER - Giá trị
25,30có kiểu gì? →INTEGER - Phép so sánh
INTEGER > INTEGERvàINTEGER < INTEGERhợp lệ không? → Hợp lệ
Ví dụ các trường hợp vi phạm:
-- So sánh không hợp lệ
WHERE name > 100
-- Error: Cannot compare VARCHAR with INTEGER
-- Phép tính không hợp lệ
SELECT name + 10 FROM users
-- Error: Cannot add VARCHAR and INTEGER
-- Gán sai kiểu
INSERT INTO users (age) VALUES ('hai mươi lăm')
-- Error: Invalid input syntax for INTEGER
2.3. Alias Resolution — Ghi nhớ biệt danh
Khi bạn đặt alias (biệt danh) cho table hoặc column, Database cần "ghi nhớ" để hiểu đúng ý bạn.
Ví dụ:
SELECT name AS "Tên khách hàng"
FROM users AS u
WHERE u.age > 25 AND u.age < 30;
Câu Query trên có nghĩa là: Cho tôi biết ‘Tên khách hàng’ của những u có tuổi từ 26 đến 29.
Database sẽ ghi nhớ:
ulà alias (nickname) của bảngusers→ Database gặpu.agesẽ hiểu làusers.age"Tên khách hàng"là alias của cộtname→ Database hiển thị trong kết quả trả về làTên khách hàngthay vìname
Kết quả từ query trên sau khi đặt ‘nick name’:
Tên khách hàng
----------------
Young_6
Young_7
Young_8
Young_9
Young_17
Young_18
Young_19
Young_20
Vậy là xong bước 2. Tiếp theo, Database sẽ bước sang giai đoạn thứ 3: Optimizer.
3. Optimizer — Tìm đường đi ngắn nhất
Sau khi đã "hiểu" câu query, Database sẽ bước vào giai đoạn quan trọng nhất — tìm cách thực thi nhanh nhất. Hãy tưởng tượng bạn muốn đi từ nhà đến công ty. Có nhiều con đường: đi đường chính thì xa hơn nhưng ít đèn đỏ, đi đường tắt thì gần hơn nhưng hay kẹt xe.
Optimizer chính là "Google Maps" của Database — Google map sẽ tạo ra nhiều cách đi, sau đó tính toán và chọn ra cách đi tối ưu nhất.
Để biết được Database đã dùng kế hoạch là gì, mời bạn đọc phần tiếp theo.
3.1. EXPLAIN — Xem "kế hoạch" của Database
Khi bạn chạy một câu query này:
SELECT name FROM users WHERE age > 25 AND age < 30;
Bạn sẽ nhận được kết quả:
name
--------
Adult_6
Adult_7
(2 rows)
Nhưng Database đã làm gì để ra kết quả này? Để xem cách database làm việc, ta dùng từ khóa EXPLAIN:
EXPLAIN SELECT name FROM users WHERE age > 25 AND age < 30;
Kết quả lúc này sẽ là:
QUERY PLAN
--------------------------------------------------------
Seq Scan on users (cost=0.00..14.80 rows=2 width=218)
Filter: ((age > 25) AND (age < 30))
Bonus: EXPLAIN ANALYZE
EXPLAIN chỉ cho bạn ước tính — Database đoán query sẽ chạy như thế nào.
Cho nên để xem số liệu thực tế? Ta cần phải thêm keyword ANALYZE:
EXPLAIN ANALYZE SELECT name FROM users WHERE age > 25 AND age < 30;
Khi đó, Database sẽ chạy thật câu query và trả về thời gian thực tế. Lưu ý: nếu query chậm thì EXPLAIN ANALYZE cũng sẽ chậm theo.
Trong phạm vi bài viết này, mình sẽ không đi sâu vào ANALYZE.
3.2. Đọc hiểu bản ‘kế hoạch’ của Query
Query Plan trông có vẻ phức tạp, nhưng thực ra khá đơn giản:
Một bước xử lý - Operator
│
┌─────────────────────────┴────────────────────────────┐
Seq Scan on users (cost=0.00..14.80 rows=2 width=218)
────┬─── ───┬─── ─────────┬─────────
│ │ │
│ │ └── Chi phí thực thi
│ └── Thực thi trên bảng nào
└── Thuật toán được sử dụng
Giải thích chi tiết:
-
Seq Scan: Thuật toán Database sử dụng -
on users: Thực thi trên bảngusers -
cost=0.00..14.80: Chi phí cần để database chạy câu query của bạn, nó không có đơn vị nhất định, chỉ là một con số sau khi được tính toán bởi nhiều phần (I/O, CPU, etc.). Tìm hiểu tại đây.- Cost có dạng
cost=a..b- a: Chi phí để lấy row đầu tiên. Với ví dụ, thì cần 0.00 để hoàn thành
- b: Chi phí để hoàn thành toàn bộ — tức là lấy hết tất cả các row. Với ví dụ trên, cần 14.80 để hoàn thành.
Để đánh giá một bước có nhanh hay không, bạn chỉ cần nhìn vào b. Giá trị b càng lớn, bước đó càng tốn thời gian xử lý.
- Cost có dạng
Trong phạm vi bài viết này, mình sẽ không đề cập tới rows, và width.
Từ ví dụ trên, ta có thể thấy: khi bạn viết một câu query, Database sẽ chuyển các thao tác trong đó thành các thuật toán tương ứng để thực thi.
Hiểu được thuật toán hoạt động ra sao, bạn sẽ hiểu được query chạy như thế nào — và quan trọng hơn, chậm ở đâu.
Tóm lại:
Query là ngôn ngữ mà chúng ta dùng để nói chuyện với Database. Nhưng thực chất Database sẽ chuyển query sang thuật toán thì mới hiểu được.
3.3. Thuật toán
Ở ví dụ trên, ta thấy Database đang dùng thuật toán Seq Scan để lấy dữ liệu.
Seq Scan — Quét tuần tự <Chỉnh lại ví dụ>
Hãy tưởng tượng bạn là HR, cần tìm tất cả nhân viên có độ tuổi từ 26-29 trong công ty.
Bạn chỉ có một cách: đi từng phòng ban, hỏi từng người một — không bỏ qua ai.
- Phòng A → Minh - 24 tuổi → ❌ Bỏ qua
- Phòng A → Lan - 27 tuổi → ✅ Ghi tên
- Phòng B → Hùng - 32 tuổi → ❌ Bỏ qua
- Phòng B → Trang - 28 tuổi → ✅ Ghi tên
- ... cứ thế cho đến người cuối cùng
Database cũng hoạt động y như vậy. Với thuật toán Seq Scan, nó sẽ vào bảng users, đọc từng dòng một, kiểm tra xem có thỏa điều kiện age > 25 AND age < 30 không — nếu có thì lấy, không thì bỏ qua.
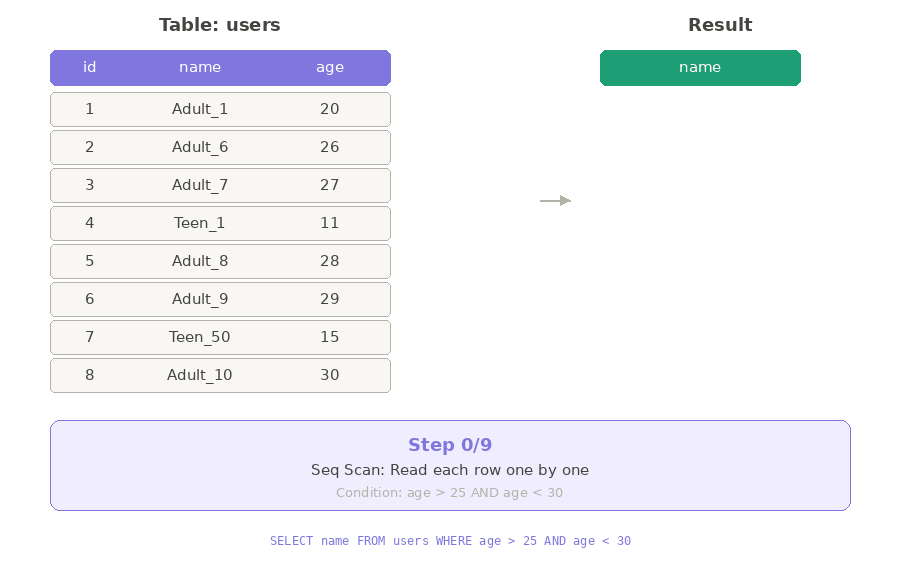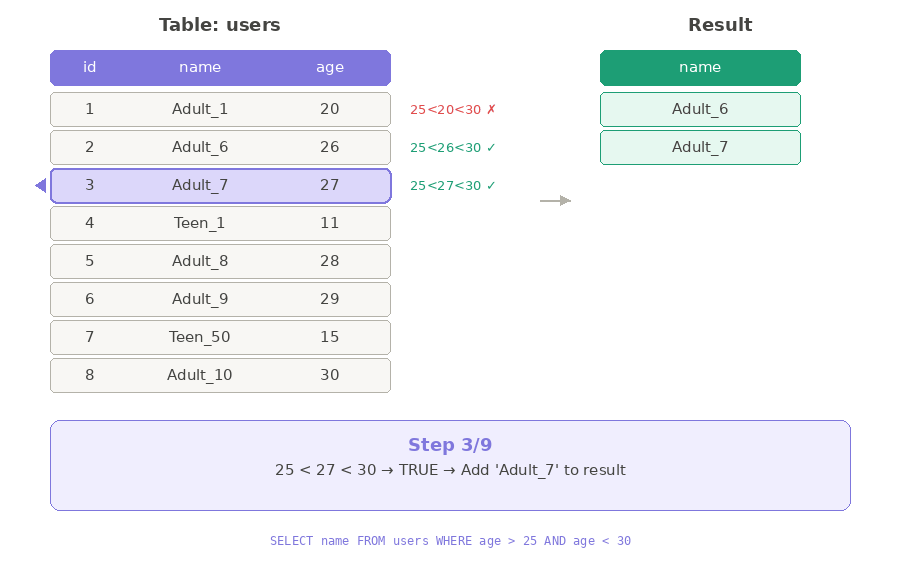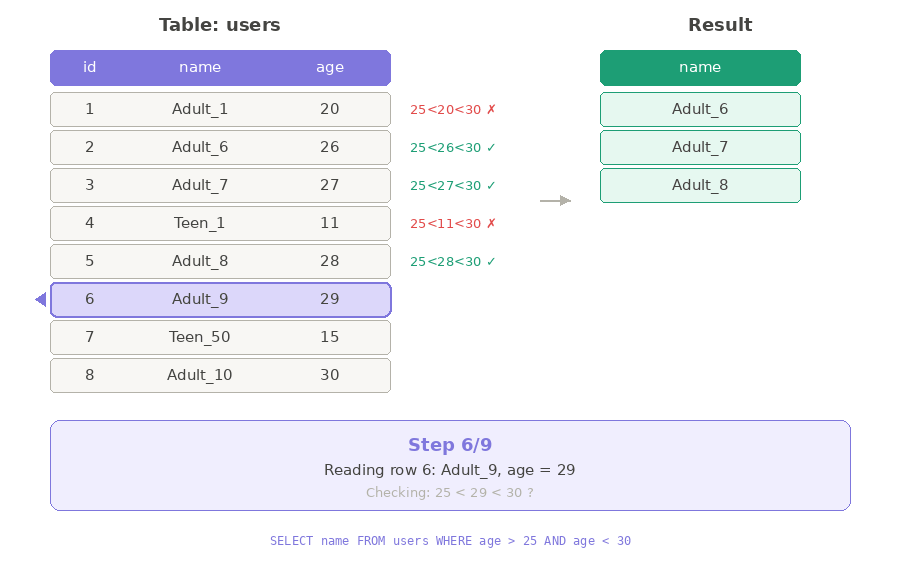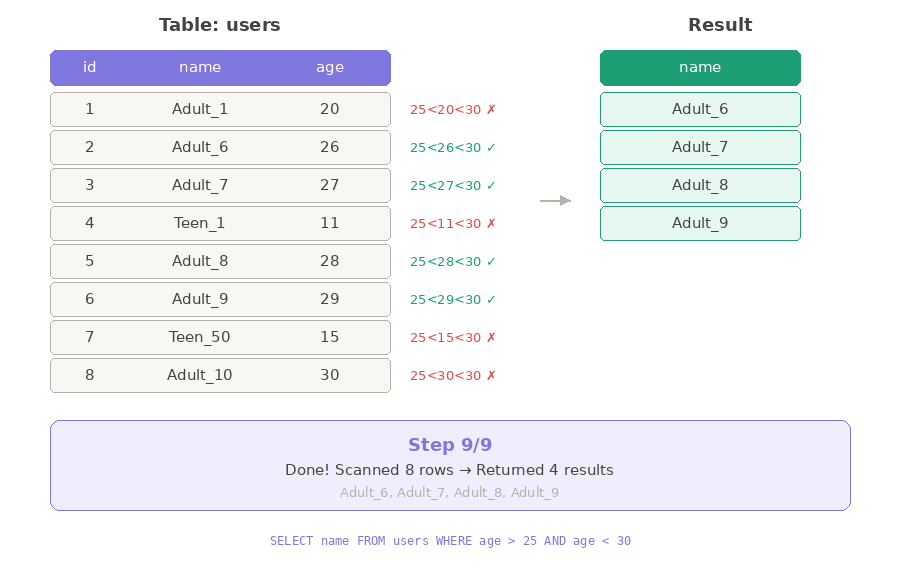
Với số lượng ít thì việc hỏi từng người như vậy không sao. Nhưng nếu công ty có 100,000 nhân viên thì sao?
Mỗi lần sếp hỏi "cho tôi danh sách người tuổi 26-29" hoặc “40-50”, bạn lại phải đi từng phòng, hỏi từng người một. Quá mệt!
Vậy có cách nào nhanh hơn không?
Bitmap Index Scan — Đánh dấu trước, lấy sau
Quay lại ví dụ trên, nếu công ty có thêm một danh sách nhân viên được sắp xếp theo tuổi:
- 26 tuổi: Lan (Phòng A), Hoa (Phòng C)
- 27 tuổi: Nam (Phòng B), Trang (Phòng A)
- 28 tuổi: Minh (Phòng D), Hùng (Phòng B)
- 29 tuổi: Mai (Phòng A), Dũng (Phòng C)
- ...
Giờ bạn không cần đi hỏi từng người nữa! Chỉ cần 2 bước:
Bước 1: Bitmap Index Scan - Tra danh sách theo tuổi → Đánh dấu phòng nào cần đến
- Từ danh sách trên, ta có thể tạo ra một tờ giấy note những ai tuổi 26-29 và gom theo phòng:
- Phòng A: Lan, Trang, Mai
- Phòng B: Nam, Hùng
- Phòng C: Hoa, Dũng
- Phòng D: Minh
Bước 2: Bitmap Heap Scan — Cầm giấy note, đi lấy tên
- Giờ bạn chỉ cần đi đến từng phòng đã ghi trong giấy note và lấy tên nhân viên. Xong!
Database hoạt động y như vậy:
- Index chính là "danh sách theo tuổi" — mỗi tuổi sẽ lưu vị trí các dòng tương ứng trong bảng
users - Bitmap chính là "tờ giấy note" — Database đánh dấu những dòng nào cần lấy
- Heap chính là bảng
usersgốc — nơi lưu trữ dữ liệu thực
Thay vì đọc 100,000 dòng, Database chỉ cần tra Index, viết Bitmap, rồi đi thẳng đến những dòng cần lấy!
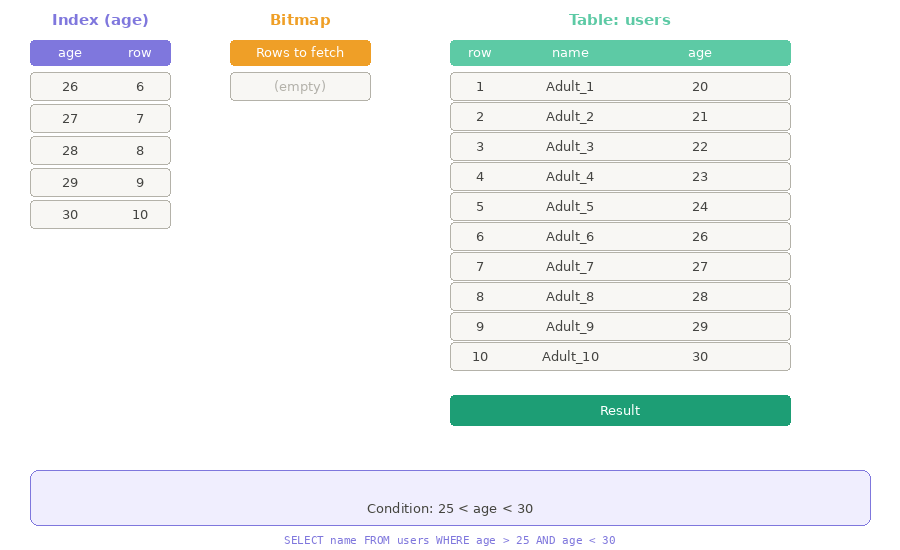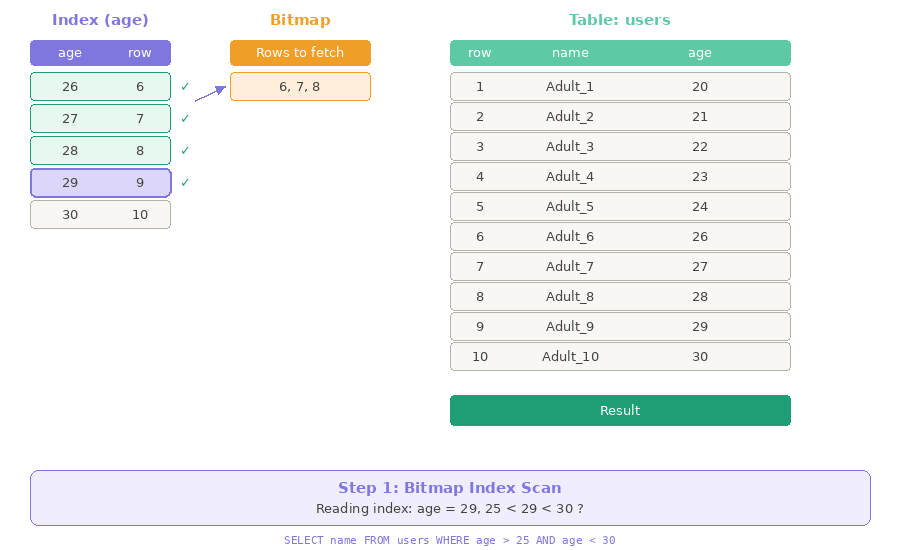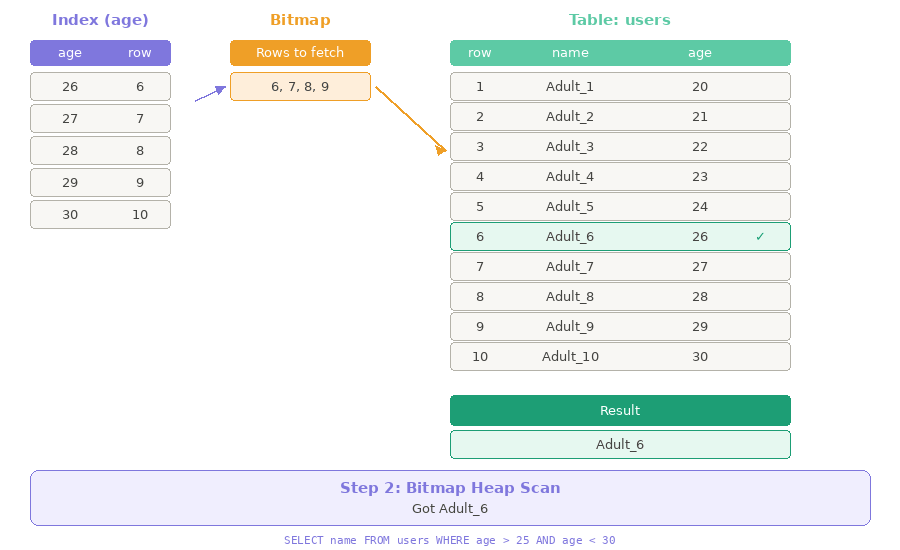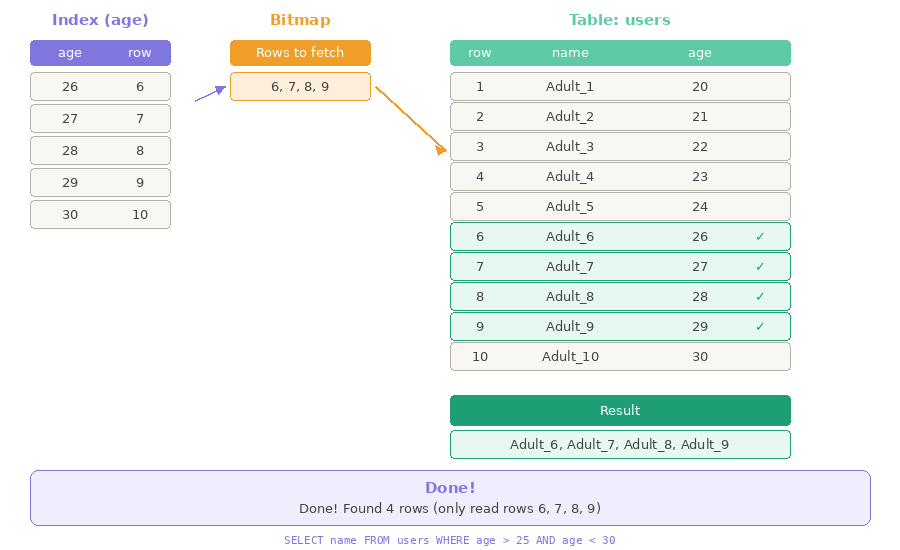
Ví dụ trên đã được đơn giản hóa để dễ hiểu. Nếu bạn muốn tìm hiểu sâu hơn, đọc thêm tại:
- https://pganalyze.com/docs/explain/scan-nodes/bitmap-heap-scan
- https://pganalyze.com/docs/explain/scan-nodes/bitmap-index-scan
Bây giờ, mỗi khi sếp hỏi "cho tôi danh sách nhân viên tuổi 26-29", bạn chỉ cần mở danh sách theo tuổi ra, viết note, rồi đi lấy tên. Nhanh gọn! 😃
Áp dụng vào Database
Để Database dùng được Bitmap Index Scan, ta cần tạo một ‘danh sách nhân viên được sắp xếp theo tuổi’ trước, tương ứng là Index trên cột age:
CREATE INDEX idx_users_age ON users(age);
Chạy lại EXPLAIN:
QUERY PLAN
----------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=4.17..9.51 rows=2 width=218)
Recheck Cond: ((age > 25) AND (age < 30))
-> Bitmap Index Scan on idx_users_age (cost=0.00..4.17 rows=2 width=0)
Index Cond: ((age > 25) AND (age < 30))
(4 rows)
Ta có thể thấy, Seq Scan đã được thay thế với thuật toán Bitmap Heap Scan, với cost đã giảm từ 14.80 xuống 9.51.
Chỉ với một dòng CREATE INDEX, query đã nhanh hơn 36%!
Trong bài viết này, mình chỉ dùng những câu query đơn giản, nên Query Plan cũng khá dễ đọc. Nhưng thực tế thì khác — các câu query thường phức tạp hơn nhiều: JOIN nhiều bảng, filter bằng WHERE, sắp xếp với ORDER BY, giới hạn bằng LIMIT, v.v.
Khi đó, Query Plan sẽ có nhiều bước lồng nhau, nhiều thuật toán chạy song song. Để đọc hiểu được, bạn cần nắm vững kiến thức cơ bản trong bài viết này, hiểu cách các thuật toán hoạt động, và biết bước nào chạy trước, bước nào chạy sau.
Nghe có vẻ phức tạp? Đừng lo — bạn có thể dùng AI để hỗ trợ. Dưới đây là prompt mình hay dùng để nhờ AI giải thích Query Plan:
-
AI Prompt
Bạn là một Database Expert với 10 năm kinh nghiệm. Nhiệm vụ của bạn là giải thích Query Plan cho người mới học một cách dễ hiểu nhất, như đang giải thích cho một đứa trẻ 10 tuổi. Thông tin Query Database: [Tên database, ví dụ: PostgreSQL, MySQL, SQL Server] Câu query: sql [Paste câu query ở đây] Query Plan: [Paste query plan ở đây] Quy tắc giải thích 1. Cách đọc Query Plan Đọc từ trong ra ngoài, từ dưới lên trên Các bước thụt vào sâu hơn (có nhiều -> hơn) sẽ chạy trước Kết quả của bước con sẽ được truyền lên bước cha 2. Format giải thích từng bước Với mỗi bước trong Query Plan, giải thích theo cấu trúc: ### Bước X: [Tên thuật toán] **Query Plan:** [Copy dòng Query Plan tương ứng] **Giải thích:** | Thành phần | Ý nghĩa | |------------|---------| | Tên thuật toán | Nó là gì, hoạt động ra sao | | Input | Dữ liệu đầu vào từ đâu | | Output | Kết quả trả về là gì | | Cost | Chi phí bao nhiêu, nghĩa là gì | **Ví dụ thực tế:** [Dùng ví dụ đời thường để minh họa: HR tìm nhân viên, thư viện tìm sách, v.v.] 3. Output yêu cầu Sau khi giải thích từng bước, cung cấp thêm: Sơ đồ thứ tự thực thi — Vẽ bằng ASCII art, thể hiện flow từ dưới lên Bảng tổng kết — Liệt kê tất cả các bước, thuật toán, cost Nhận xét & Gợi ý tối ưu — Query này có vấn đề gì không? Có thể cải thiện bằng cách nào?
4. Execution
Sau tất cả các bước trên, việc còn lại của Database chỉ là chạy câu query theo kế hoạch đã chọn — và trả kết quả về cho bạn. Đơn giản vậy thôi! 🚀
Đôi vài dòng:
Thực tế, Database sẽ tự đưa ra kế hoạch tối ưu nhất để chạy câu query của bạn. Dựa vào số lượng dòng, kích thước dữ liệu, và nhiều yếu tố khác, Database sẽ tự đánh giá và lựa chọn thuật toán phù hợp.
Ví dụ, bạn đã đánh Index nhưng Database vẫn có thể chọn Seq Scan thay vì Bitmap Index Scan — nếu nó đánh giá rằng đọc tuần tự sẽ nhanh hơn trong trường hợp đó.
Ngoài Seq Scan và Bitmap Index Scan, Database còn có rất nhiều thuật toán khác như Index Scan, Index Only Scan, Parallel Seq Scan, ... Trong phạm vi bài viết này, mình chỉ giới thiệu hai thuật toán, và mỗi Database sẽ có thuật toán khác nhau.
Lời kết
Vậy là chúng ta đã đi qua hành trình của một câu query — từ lúc bạn gõ SELECT cho đến khi Database trả về kết quả. Bốn bước Parsing → Binding → Optimizer → Execution tưởng chừng phức tạp, nhưng thực ra cũng giống như cách chúng ta đọc hiểu một câu văn vậy.
Hiểu được Database "nghĩ" gì, bạn sẽ biết cách viết query tốt hơn, biết khi nào cần đánh Index, và quan trọng nhất — biết chậm ở đâu để tối ưu.
Database rất thông minh, nó sẽ luôn cố gắng đưa ra kế hoạch tốt nhất để lấy data cho bạn từ câu query bạn viết ra. Nhưng nếu câu query bạn viết quá phức tạp, thì Database cũng không thể tối ưu nó tốt nhất được. Cho nên hãy nhớ, bạn chính sẽ là người sẽ đặt giới hạn cho Database.
Với bài viết này, mình đã đơn giản hoá các việc mà Database làm, thực tế nó phức tạp hơn nhiều, và để tiếp cận nhiều đọc giả hơn, mình đã đơn giản đi rất nhiều, nếu các bạn hứng thú, xin mời đọc phần bên dưới
Sách tham khảo

Phần lớn kiến thức trong bài viết này mình học được từ cuốn "PostgreSQL Query Optimization" của Henrietta Dombrovskaya, Boris Novikov, và Anna Bailliekova. Cảm ơn các tác giả đã viết một cuốn sách quá chất lượng!
Trước đây, mình không hiểu cách query hoạt động — chỉ toàn dựa vào cảm tính để tối ưu. Nhưng sau khi đọc cuốn sách này, mình đã hiểu được Database xử lý câu query như thế nào, các dòng trong Query Plan nghĩa là gì, tại sao Database chọn thuật toán này thay vì thuật toán kia, và làm thế nào để "gợi ý" cho Database chạy nhanh hơn.
Nhờ vào đó, mình đã tối ưu được nhiều query chậm trong dự án thực tế — có những query giảm từ vài giây thay thậm chí vài phút khi data phình to ra xuống còn vài giây hoặc vài chục milliseconds. Nếu bạn muốn đào sâu hơn về Database Performance nói chung và PostgreSQL nói riêng, mình highly recommend cuốn sách này!
Shoutout anh @DucLe đã giới thiệu em cuốn sách này. 🙏
Nguồn tham khảo:
- Dombrovskaya, H., Novikov, B., & Bailliekova, A. (2021). PostgreSQL Query Optimization: The Ultimate Guide to Building Efficient Queries. Apress.
- PostgreSQL Global Development Group. (n.d.). Using EXPLAIN. PostgreSQL Documentation. https://www.postgresql.org/docs/current/using-explain.html
Bài viết gốc
All rights reserved
