Puppeteer - Giải pháp trích xuất thông tin Web trong NodeJS [Phần 1]
Bài đăng này đã không được cập nhật trong 5 năm
Chào các bạn!  Chắc hẳn trong quá trình phát triển một tính năng phía Backend, bạn sẽ gặp những trường hợp cần phải truy cập một trang web và trích xuất thông tin từ chúng vì một mục đích nào đó. Nó gọi là kỹ thuật Crawl. Công việc chính của Crawl là thu thập dữ liệu từ một trang bất kỳ rồi tiến hành phân tích mã nguồn HTML để đọc dữ liệu. Sau đó, lọc ra theo yêu cầu người dùng hoặc dữ liệu mà Search Engine yêu cầu.
Npm trong NodeJS cung cấp cho chúng ta một thư viện vô cùng hữu ích để làm việc này, đó là Puppeteer.
Trước khi đi tìm hiểu về Puppeteer, chúng ta hãy cũng đến với một khái niệm rất quan trọng được gọi là Headless Browser.
Chắc hẳn trong quá trình phát triển một tính năng phía Backend, bạn sẽ gặp những trường hợp cần phải truy cập một trang web và trích xuất thông tin từ chúng vì một mục đích nào đó. Nó gọi là kỹ thuật Crawl. Công việc chính của Crawl là thu thập dữ liệu từ một trang bất kỳ rồi tiến hành phân tích mã nguồn HTML để đọc dữ liệu. Sau đó, lọc ra theo yêu cầu người dùng hoặc dữ liệu mà Search Engine yêu cầu.
Npm trong NodeJS cung cấp cho chúng ta một thư viện vô cùng hữu ích để làm việc này, đó là Puppeteer.
Trước khi đi tìm hiểu về Puppeteer, chúng ta hãy cũng đến với một khái niệm rất quan trọng được gọi là Headless Browser.
1. Headless Browser là gì?
Hiểu một cách ngắn gọn, Headless Brower là một trang web "không đầu" - một từ để chỉ web không có giao diện đồ họa người dùng (GUI). Có thể hiểu GUI bao gồm những thành phần trực tiếp tương tác với người dùng như: Nút bấm, input form, biểu tượng hoặc cửa sổ,.... Headless Browser chủ yếu được sử dụng bởi những lập trình viên phần mềm vì một trong những lợi ích lớn nhất mà Headless Browser mang lại, đó là khả năng chạy trực tiếp trên servers thông qua command line hoặc giao thức mạng.
Một số ứng dụng của Headless Brower có thể kể đến bao gồm:
- Crawl dữ liệu từ các trang web
- Chụp ảnh màn hình của một trang web
- Kiểm tra việc tự động hóa
- Đo hiệu năng của các tác vụ không yêu cầu GUI
Những Headless Browser khác nhau sẽ có hiệu suất khác nhau khi chạy trên những nền tảng khác nhau. Một số trình Headless Browser phổ biến có thể kể tới như: Google Chrome, Mozilla Firefox, HtmlUnit,....
Các bạn có thể tìm hiểu thêm về Headless Browser tại đây: https://en.wikipedia.org/wiki/Headless_browser
Vậy là chúng ta đã có một loại Brower có thể dùng để truy xuất dữ liệu từ phía server một cách nhanh chóng. Vậy chúng ta lấy gì để có thể gọi, điều khiển và giả lập những tương tác của người dùng lên chúng. Đó là lý do Puppeteer ra đời.
2. Puppeteer
2.1. Định nghĩa
Theo như nguyên văn, Puppeteer được định nghĩa như sau:
Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
Ta thể dịch một các dễ hiểu đó là:
Puppeteer là một thư viện của Node. Nó cung cấp một API cấp cao, dùng để điều khiển Headless Browser hoặc Chromium thông qua code. Nó cũng có thể được dùng để cấu hình để sử dụng một trang web Chrome hoặc Chromium hoàn chỉnh.
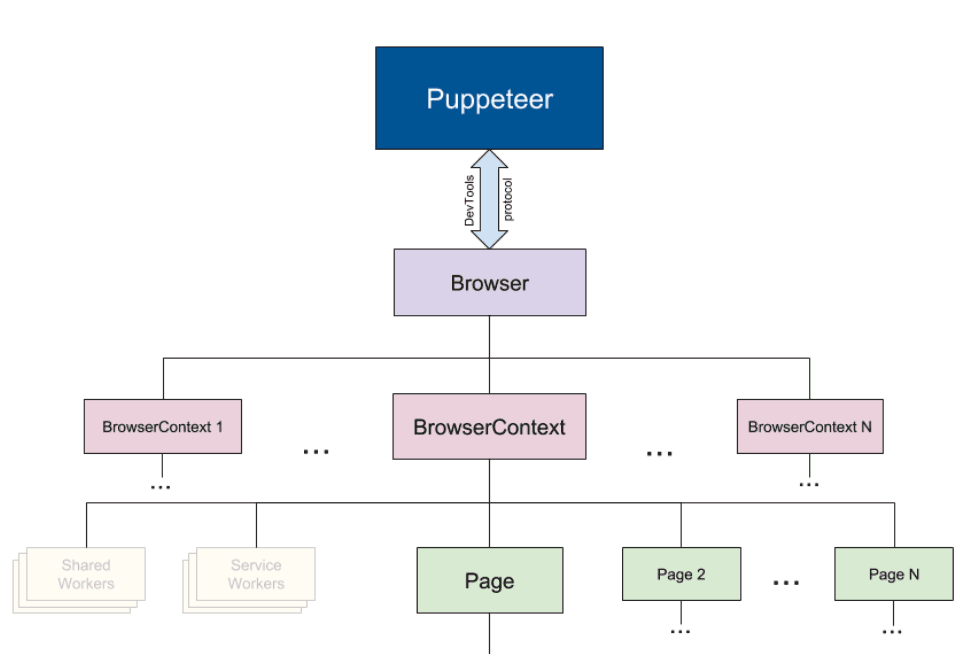
Tất cả những tương tác người dùng ở giao diện thực tế đều có thể được sử dụng bởi Puppeteer. Có thể kể đến như:
- Gửi những form dữ kiệu, kiểm thử UI hay các thao tác bàn phím,...
- Tự động lưu dưới dạng ảnh hay PDF khi thực hiện chụp màn hình
- Lấy dữ liệu dù trang web có yêu cầu xác thực người dùng hoặc load dữ liệu dùng Ajax
- Tạo môi trường auto-test, chạy case test của bạn trên môi trường Chrome phiên bản mới nhất
- Ghi lại timeline trace của trang web của bạn, giúp cho việc chuẩn đoán các vấn đề về hiệu năng
- Kiểm thử các Chrome Extensions.
2.2. Bắt đầu với Puppeteer
2.2.1. Cài đặt
Như đã nói ở trên, Puppeteer là một thư viện của Npm. Chính vì vậy việc cài đặt Puppeteer vô cùng đơn giản:
npm i puppeteer
# or "yarn add puppeteer"
2.2.1. Khởi tạo và gọi đến một trang web
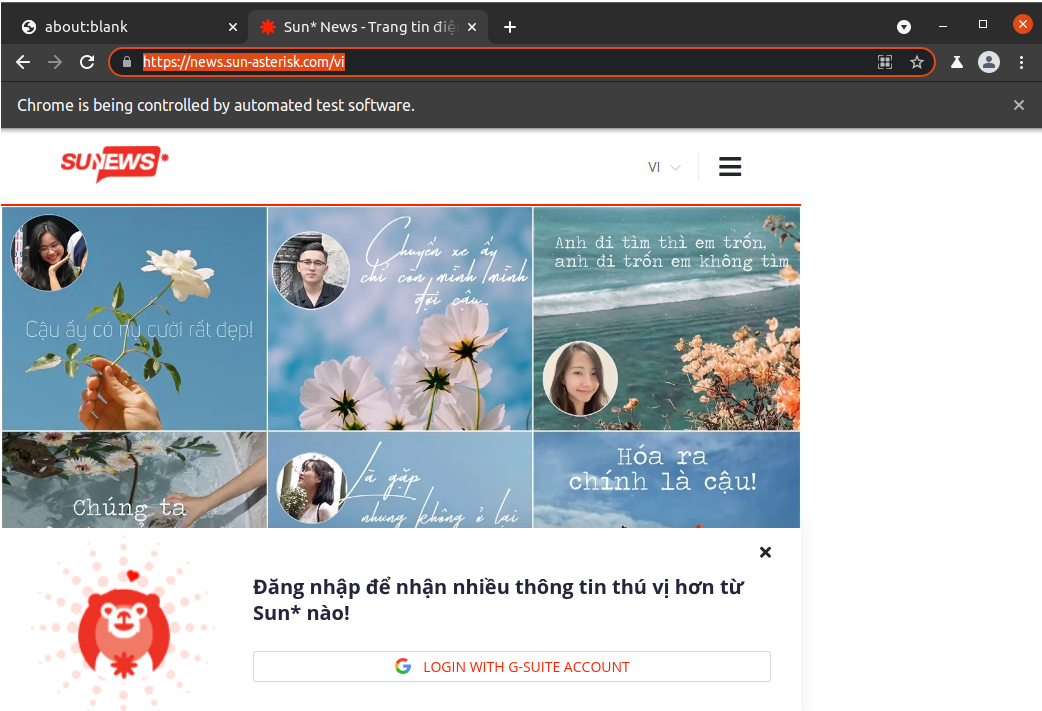
Sau khi hoàn tất quá trình cài đặt Puppeteer. Chúng ta tiến hành việc gọi tới một trang web bất kỳ. Ở đây, mình sẽ lấy ví dụ về việc gọi tới trang chủ của Sun News
import { launch } from "puppeteer";
export const screenshotWithPuppeteer = async () => {
const browser = await launch({ headless: false }); // khởi tạo browser
const page = await browser.newPage(); // tạo một trang web mới
await page.goto("https://news.sun-asterisk.com/vi"); // điều hướng trang web theo URL
// chụp ảnh trang web
await page.screenshot({
path: "sun.png",
});
await browser.close(); // đóng trang web
};
Sau khi chạy đoạn code trên, hệ thống sẽ tự động mở một trình duyệt mới. Nếu bạn muốn ẩn trình duyệt đi, bạn chỉ cần bỏ tham số { headless: false } hoặc set giá trị { headless: true } , sau đó Puppeteer thực hiện chụp màn hình và lưu dưới tên sun.png
Tạm kết
Vậy và chúng ta đã bước đầu làm quen với Puppeteer trong việc truy xuất thông tin với Headless Browser. Ở bài viết sau, mình sẽ đề cập sâu hơn về các phương thức mà Puppeteer cung cấp cho người dùng trong việc điều khiển một Headless Browser nhé!
Tài liệu tham khảo
All rights reserved
