[POSTGRES] Tìm Hiểu BRIN Index Trong Database
Postgres BRIN(Block Range Index) Index - Tối ưu hiệu năng với Storage nhỏ nhất
Trong bài viết này mình tập trung giải thích loại index BRIN (Block Range Index). Mục đích sử dụng và nó có những điểm nổi bật hơn những loại index khác ở điểm nào.
Sẽ demo sql đơn giản để so sánh với các index phổ biến khác trong postgresql
Block Range Index Là gì.
Block Range Index được viết tắt là BRIN, trong postgres block là 1 đơn vị của việc storage và được sét mặc định là 8kb. BRIN đơn giản là một chuỗi block (mặc định là 128kb). BRIN index là 1 cách dễ dàng để tăng tóc độ, nó đặc biệt hữu ích cho data tuần tự hoặc sắp xếp các đặc điểm như kiểu time-series hoặc một kiểu sắp xếp.
Một vài điểm của BRIN
- sẽ hoạt động tốt khi data được sắp xếp hoặc khi scans 1 cách tuần tự (tốt hơn khi index scans)
- thay vì lưu trữ độc lập mỗi record, BRIN sẽ lưu trữ theo từng block-level summaries, điều này làm size sẽ nhỏ hơn các loại index khác
- mỗi block sẽ chứa 1 khoảng giá trị, index sẽ lưu giá trị min và max tương ứng với mỗi block.
- sẽ chia table vào trong những khối và lưu trữ thông tin cho mỗi khối.
Create BRIN index
- để tạo BRIN ta chỉ cần sử dụng
CREATE INDEXvớiUSING BRIN
CREATE INDEX ind_column_timestamp ON table_name USING BRIN (column_name);
Khi nào chúng ta cần sử dụng nó.
Rất nhiều ứng dụng ngày nay luôn muốn record data từ devices, tracking-information, real-time transaction banking và tổng thể các nguồn khác - tất cả điều chung 1 thành phần là timestamp, và timestamp là luôn luôn tăng.
Timestamps là cực kì hữu ích, hỗ trợ rất lớn các loại cơ bản như phân tích, query and ...
BRIN không chỉ có hiệu năng tốt hơn BTree mà còn tiết kiệm hơn 99% của space of disk.
demo
- để bắt đầu demo thì cần phải có 1 postgres
- Tạo 1 table
tracking
CREATE TABLE ticketing (
id BIGSERIAL,
tracking_id VARCHAR(32),
count int,
created_at timestamptz NOT NULL
);
insert data mẫu
DO $FN$
BEGIN
FOR counter IN 1..3000000 LOOP
insert into trackings(count, tracking_id, created_at ) values(
floor(random() * 10 + 1)::int,
uuid_in(overlay(overlay(md5(random()::text || ':' || random()::text) placing '4' from 13) placing to_hex(floor(random()*(11-8+1) + 8)::int)::text from 17)::cstring),
now()::timestamptz
);
END LOOP;
END;
$FN$
- create btree index:
CREATE INDEX in_trackings_btree ON trackings(created_at);
select size disk space:
SELECT pg_size_pretty(pg_relation_size('in_trackings_btree'));
kết quả:
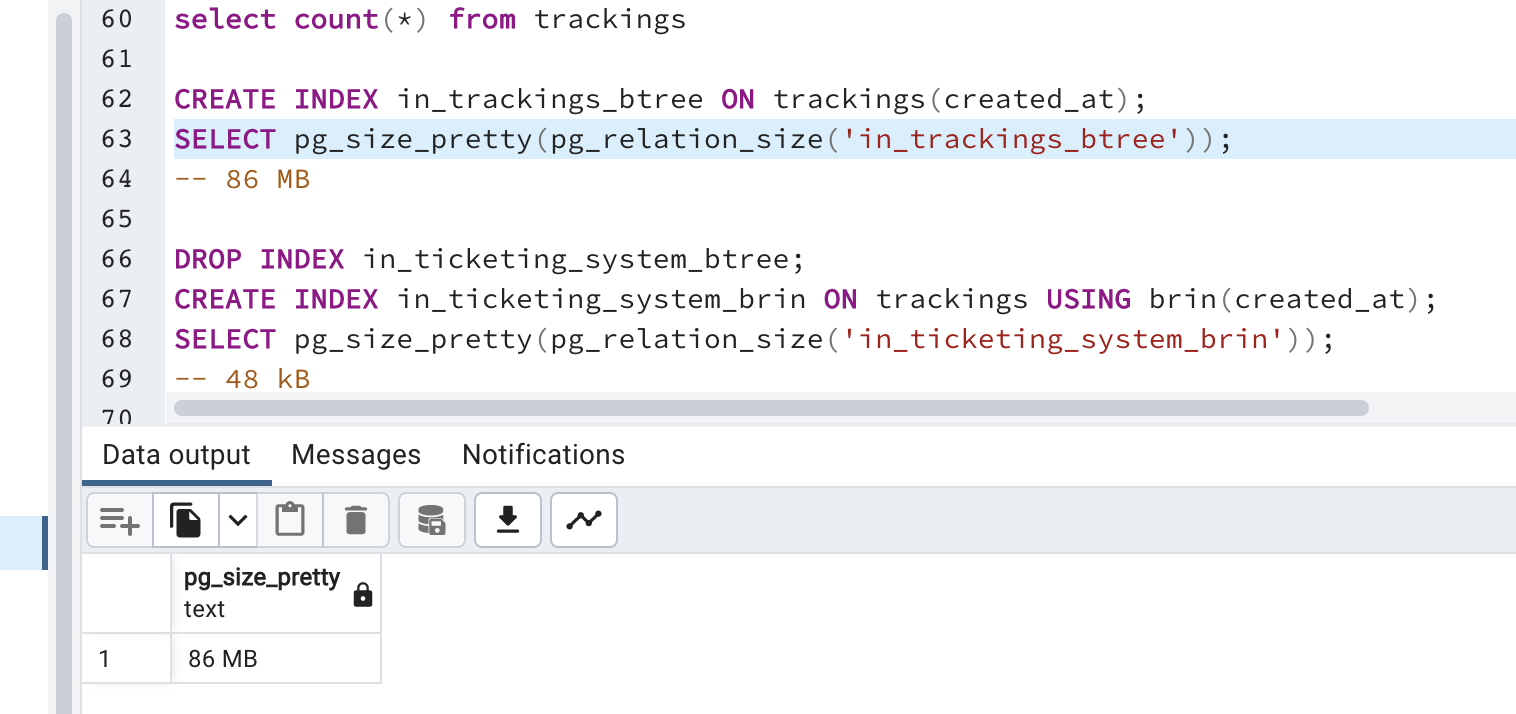
- create brin index:
CREATE INDEX in_trackings_brin ON trackings USING brin(created_at);
select size disk space:
SELECT pg_size_pretty(pg_relation_size('in_trackings_brin'));
kết quả:
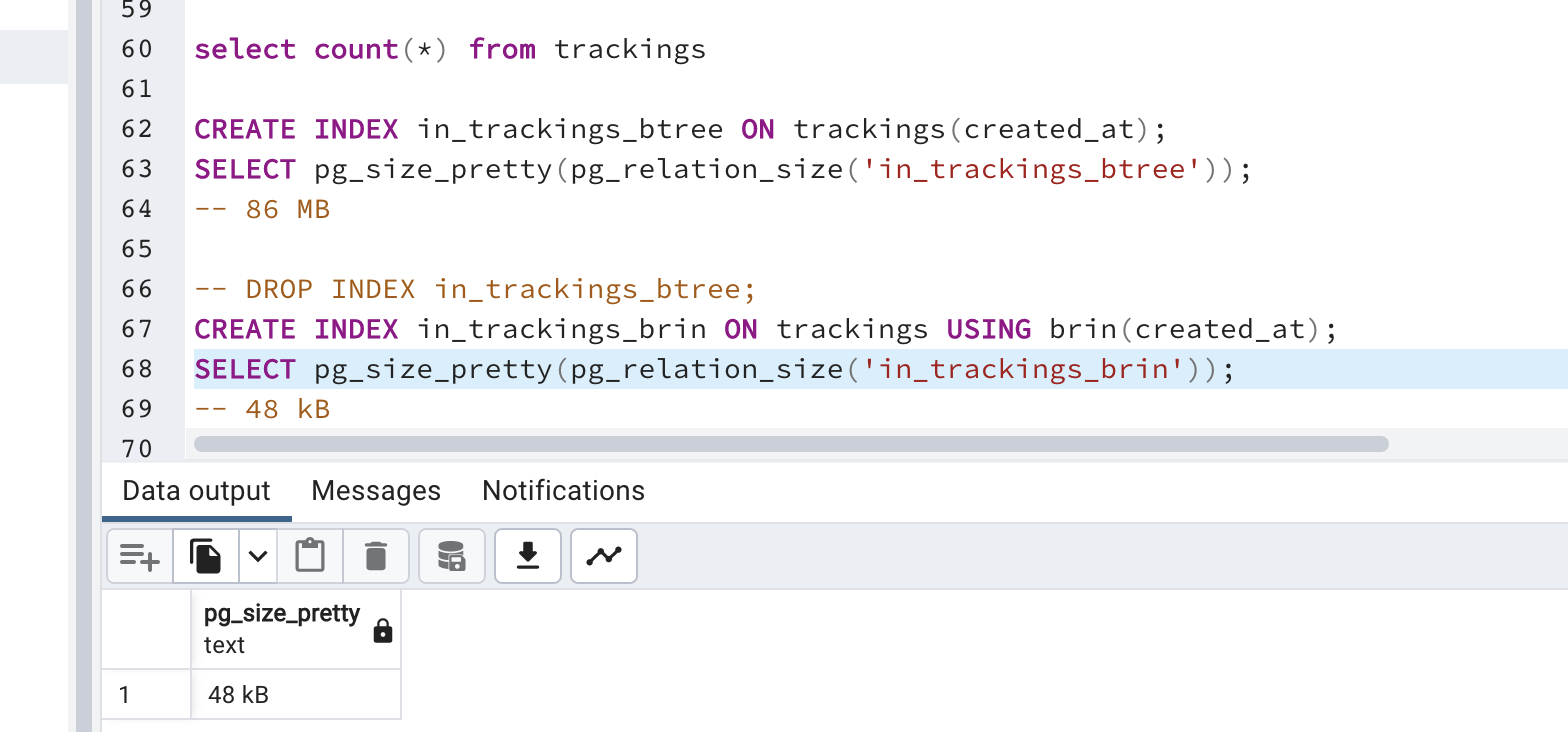
Kết luận.
- BRIN sẽ mang lại hiệu năng tốt hơn nếu data sequence hoặc sắp xếp
- Tối ưu về disk space hơn.
Liên Hệ
- facebook: https://www.facebook.com/phucducdev/
- group: https://www.facebook.com/groups/575250507328049
- gmail: ducnp09081998@gmail.com
- linkedin: https://www.linkedin.com/in/phucducktpm/
- hashnode: https://hashnode.com/@OpenDev
- telegram: https://t.me/OpenDevGolang
All rights reserved
