Phân tích text tiếng Nhật trong rails
Bài đăng này đã không được cập nhật trong 6 năm
Đã bao giờ bạn lập trình ra một ứng dụng đòi hỏi phải phân tích một đoạn text tiếng Nhật ? Hay bạn muốn phân tích các từ trong câu tiếng Nhật vì bạn đang học tiếng Nhật. Bạn đã có công cụ để làm việc đó chưa. Xin giới thiệu với các bạn một số cách để thực hiện việc trên.
I. Mecab
Mecab là một công cụ mã nguồn mở phân tích hình thái câu từ, được phát triển bởi Taku Kudo. Tên của nó công cụ có nguồn gốc từ tên món ăn ưa thích của tác giả めかぶ (me-ka-bu) có nghĩa là củ cải.
Mecab được phát triển từ Chasen, một công cụ phân tích từ cũng bắt nguồn từ Viện Khoa học và công nghệ sau đại học Nara, xuất thân của Taku Kudo. Tuy nhiên khi so sánh với Chasen, Mecab nhanh hơn khoảng 3~4 lần khi phân tích câu có cùng độ phức tạp. Mecab có thể sử dụng một số loại từ điển khác nhau, nhưng từ điển được sử dụng nhiều nhất là IPADIC. Mecab đã được sử dụng trong việc tạo ra dữ liệu n-gram quy mô lớn của Google. Dữ liệu n-gram là gì, ví dụ dễ hiểu cho các bạn là cụm từ "tôi đi học", khi phân tích ra 1-gram ("tôi", "đi", "học"), 2-gram("tôi đi", "đi học").
Bạn có thể xem thông tin của nó tại đây
1. Cài đặt mecab
Mình sẽ hướng dẫn các bạn cài đặt mecab trên ubuntu
Việc đầu tiên các bạn cần tải package mecab tại đây
Sau đó cài đặt bằng command trong terminal như sau:
$ tar zxfv mecab-0.996.tar.gz
$ cd mecab-0.996
$ ./configure
$ make
$ make check
$ sudo make install
Sau đó chúng ta tải từ điển để mecab sử dụng cho việc phân tích hình thái text. Đầu tiên các bạn sẽ tải bộ từ điển ipadic về tại đây
$ tar zxfv mecab-ipadic-2.7.0-20070801.tar.gz
$ cd mecab-ipadic-2.7.0-20070801/
$ ./configure --with-charset=utf8
$ make
$ sudo make install
Và sau đó chạy lệnh sau để thiết lập mecab config
$ sudo ./configure --with-charset=utf8 --with-mecab-config=/usr/local/bin/mecab-config
2. Sử dụng
Tới đây đã cài đặt thành công mecab, sau đó chúng ta có thể thử phân tích câu tiếng Nhật với mecab. Bật mecab lên và gõ thử
# mecab
# ウィキペディア(Wikipedia)は誰でも編集できるフリー百科事典です
Chúng ta sẽ được kết quả như sau:
ウィキペディア 名詞,一般,*,*,*,*,*
( 記号,括弧開,*,*,*,*,(,(,(
Wikipedia 名詞,固有名詞,組織,*,*,*,*
) 記号,括弧閉,*,*,*,*,),),)
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
誰 名詞,代名詞,一般,*,*,*,誰,ダレ,ダレ
でも 助詞,副助詞,*,*,*,*,でも,デモ,デモ
編集 名詞,サ変接続,*,*,*,*,編集,ヘンシュウ,ヘンシュー
できる 動詞,自立,*,*,一段,基本形,できる,デキル,デキル
フリー 名詞,一般,*,*,*,*,フリー,フリー,フリー
百科 名詞,一般,*,*,*,*,百科,ヒャッカ,ヒャッカ
事典 名詞,一般,*,*,*,*,事典,ジテン,ジテン
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
EOS
Rất thú vị phải không nào 
II. Bộ đôi mecab và gem natto trong rails
Natto là một thư viện của rails cung cấp giao diện cho chúng ta sử dụng mecab trong rails dễ dàng hơn.
1. Cài đặt
Đầu tiên natto sẽ yêu cầu cài đặt một số package trên máy tính các bạn trước để sử dụng được
- Mecab 0.996
- Một từ điển, ví dụ như IPADIC đã cài ở trên
- Ruby 1.9 hoặc cao hơn
- ffi 1.9.0 hoặc cao hơn
Gõ lệnh sau để cài đặt gem natto:
gem install natto
Thiết lập biến môi trường trong ứng dụng rails để natto sử dụng mecab:
ENV['MECAB_PATH']='/usr/local/lib/libmecab.so'
2. Sử dụng
Mở rails console lên và thử:
require 'natto'
nm = Natto::MeCab.new
=> #<Natto::MeCab:0x00000803633ae8
@model=#<FFI::Pointer address=0x000008035d4640>, \
@tagger=#<FFI::Pointer address=0x00000802b07c90>, \
@lattice=#<FFI::Pointer address=0x00000803602f80>, \
@libpath="/usr/local/lib/libmecab.so", \
@options={}, \
@dicts=[#<Natto::DictionaryInfo:0x000008036337c8 \
@filepath="/usr/local/lib/mecab/dic/ipadic/sys.dic", \
charset=utf8, \
type=0>] \
@version=0.996>
puts nm.version
=> 0.996
Hiển thị thông tin về bộ từ điển đang được sử dụng:
sysdic = nm.dicts.first
puts sysdic.filepath
=> /usr/local/lib/mecab/dic/ipadic/sys.dic
puts sysdic.charset
=> utf8
Hãy thử phân tích một đoan text tiếng Nhật
puts nm.parse('俺の名前は星野豊だ!!そこんとこヨロシク!')
俺 名詞,代名詞,一般,*,*,*,俺,オレ,オレ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
名前 名詞,一般,*,*,*,*,名前,ナマエ,ナマエ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
星野 名詞,固有名詞,人名,姓,*,*,星野,ホシノ,ホシノ
豊 名詞,固有名詞,人名,名,*,*,豊,ユタカ,ユタカ
だ 助動詞,*,*,*,特殊・ダ,基本形,だ,ダ,ダ
! 記号,一般,*,*,*,*,!,!,!
! 記号,一般,*,*,*,*,!,!,!
そこ 名詞,代名詞,一般,*,*,*,そこ,ソコ,ソコ
ん 助詞,特殊,*,*,*,*,ん,ン,ン
とこ 名詞,一般,*,*,*,*,とこ,トコ,トコ
ヨロシク 感動詞,*,*,*,*,*,ヨロシク,ヨロシク,ヨロシク
! 記号,一般,*,*,*,*,!,!,!
EOS
Các bạn có thể xem thêm về cách sử dụng natto tại đây
III. Kuromoji-ruby
Đây là một thư viện của ruby để phân tích cú pháp text tiếng Nhật, sử dụng rất dễ dàng
1. Cài đặt
Để sử dụng được kuromoji, yêu cầu bạn sẽ phải cài đặt Java trước ở trên máy và môi trường java
Thêm vào trong Gemfile:
gem 'kuromoji-ruby'
và thực hiện bundle để cài đặt nó.
2. Sử dụng
Sau đó bạn có thể thử ở trong console:
Kuromoji::Core.new.tokenize("あそこにいるのチャウチャウちゃうんちゃう")
#=> {"あそこ"=>"名詞,代名詞,一般,*,*,*,あそこ,アソコ,アソコ",
"に"=>"助詞,格助詞,一般,*,*,*,に,ニ,ニ",
"いる"=>"動詞,自立,*,*,一段,基本形,いる,イル,イル",
"の"=>"助詞,連体化,*,*,*,*,の,ノ,ノ",
"チャウチャウ"=>"名詞,一般,*,*,*,*,*",
"ちゃう"=>"動詞,自立,*,*,五段・ワ行促音便,基本形,ちゃう,チャウ,チャウ",
"ん"=>"名詞,非自立,一般,*,*,*,ん,ン,ン"}
Kuromoji::Core.new.reading("吉田篤")
=> {"吉田"=>"ヨシダ", "篤"=>"アツシ"}
Một ví dụ khác, tôi sẽ thử 1 ví dụ để chuyển đổi text Kanji sang Katakana cho các bạn xem
Để chuyển đổi sang text Katakana, các bạn định nghĩa một hàm như sau:
require "kuromoji-ruby"
def to_kana str
new_str = Kuromoji::Core.new.tokenize(clean_spaces(str))
.map{|word, features| [word].concat features.split(",")}
.map{|words| words.last == "*" ? words.first : words.last}
.map{|word| word.tr("0-9", "0-9")}
.compact
.join(GLUE)
.squeeze("-")
new_str
end
Kuromoji sẽ phân tích tham số truyền vào là 1 đoạn text, sau đó tách ra chữ cái để phân tích từng chữ, out put đầu ra là các feature. Các bạn có thể vào trang https://www.atilika.org/kuromoji/ để xem demo được rõ hơn. Một ví dụ sau:
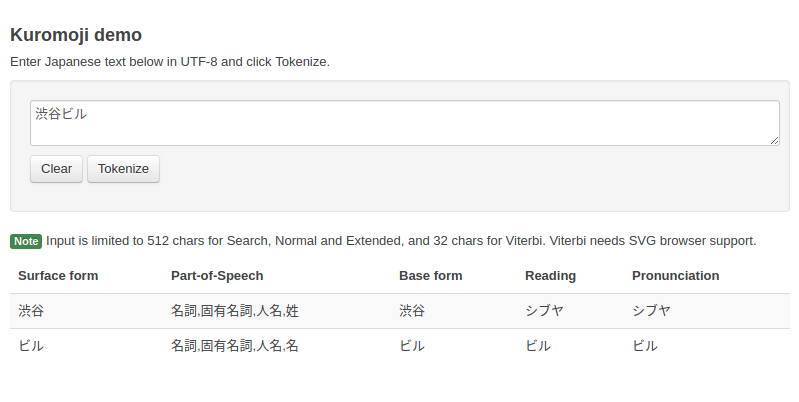
Sau khi nhập vào text 渋谷ビル ta sẽ được text kana tương ứng là シブヤビル
Đây là một số cách để các bạn phân tích một đoạn text tiếng nhật, phụ vụ cho việc học tập hoặc có thể ứng dụng mà các bạn viết sẽ yêu cầu các bạn thực hiện việc đó
Cảm ơn các bạn đã đọc bài viết của mình !
All rights reserved
