# Phân lớp bằng Random Forests trong Python
Bài đăng này đã không được cập nhật trong 7 năm
Random Forests là thuật toán học có giám sát (supervised learning). Nó có thể được sử dụng cho cả phân lớp và hồi quy. Nó cũng là thuật toán linh hoạt và dễ sử dụng nhất. Một khu rừng bao gồm cây cối. Người ta nói rằng càng có nhiều cây thì rừng càng mạnh. Random forests tạo ra cây quyết định trên các mẫu dữ liệu được chọn ngẫu nhiên, được dự đoán từ mỗi cây và chọn giải pháp tốt nhất bằng cách bỏ phiếu. Nó cũng cung cấp một chỉ báo khá tốt về tầm quan trọng của tính năng. Random forests có nhiều ứng dụng, chẳng hạn như công cụ đề xuất, phân loại hình ảnh và lựa chọn tính năng. Nó có thể được sử dụng để phân loại các ứng viên cho vay trung thành, xác định hoạt động gian lận và dự đoán các bệnh. Nó nằm ở cơ sở của thuật toán Boruta, chọn các tính năng quan trọng trong tập dữ liệu.
Thuật toán Random Forests
Giả sử bạn muốn đi trên một chuyến đi và bạn muốn đi đến một nơi mà bạn sẽ thích.
Vậy bạn sẽ làm gì để tìm một nơi mà bạn sẽ thích? Bạn có thể tìm kiếm trực tuyến, đọc các bài đánh giá trên blog và các cổng thông tin du lịch hoặc bạn cũng có thể hỏi bạn bè của mình.
Giả sử bạn đã quyết định hỏi bạn bè và nói chuyện với họ về trải nghiệm du lịch trong quá khứ của họ đến những nơi khác nhau. Bạn sẽ nhận được một số khuyến nghị từ tất cả các bạn. Bây giờ bạn phải tạo danh sách các địa điểm được đề xuất. Sau đó, bạn yêu cầu họ bỏ phiếu (hoặc chọn địa điểm tốt nhất cho chuyến đi) từ danh sách các địa điểm được đề xuất bạn đã thực hiện. Địa điểm có số phiếu bầu cao nhất sẽ là lựa chọn cuối cùng của bạn cho chuyến đi.
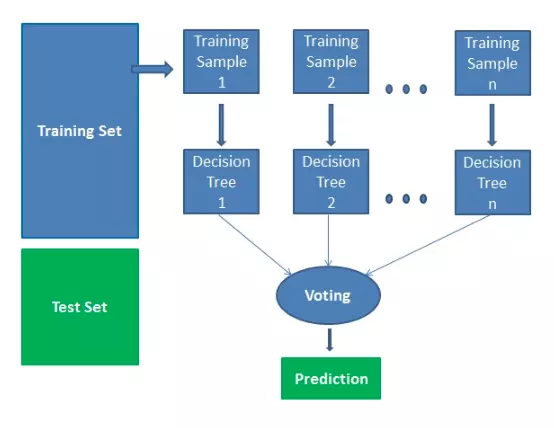
Trong quá trình quyết định ở trên, có hai phần. Trước tiên, hãy hỏi bạn bè về trải nghiệm du lịch cá nhân của họ và nhận được đề xuất từ nhiều nơi họ đã ghé thăm. Điều này cũng giống như sử dụng thuật toán cây quyết định. Ở đây, mỗi người trong số các bạn chọn những nơi mà họ đã ghé thăm cho đến nay. Phần thứ hai, sau khi thu thập tất cả các khuyến nghị, là thủ tục bỏ phiếu để chọn địa điểm tốt nhất trong danh sách các khuyến nghị. Toàn bộ quá trình nhận được khuyến nghị từ bạn bè và bỏ phiếu cho họ để tìm ra nơi tốt nhất được gọi là thuật toán rừng ngẫu nhiên.
Về mặt kỹ thuật, nó là một phương pháp tổng hợp (dựa trên cách tiếp cận phân chia và chinh phục) của các cây quyết định được tạo ra trên một tập dữ liệu được chia ngẫu nhiên. Bộ sưu tập phân loại cây quyết định này còn được gọi là rừng. Cây quyết định riêng lẻ được tạo ra bằng cách sử dụng chỉ báo chọn thuộc tính như tăng thông tin, tỷ lệ tăng và chỉ số Gini cho từng thuộc tính. Mỗi cây phụ thuộc vào một mẫu ngẫu nhiên độc lập. Trong bài toán phân loại, mỗi phiếu bầu chọn và lớp phổ biến nhất được chọn là kết quả cuối cùng. Trong trường hợp hồi quy, mức trung bình của tất cả các kết quả đầu ra của cây được coi là kết quả cuối cùng. Nó đơn giản và mạnh mẽ hơn so với các thuật toán phân loại phi tuyến tính khác.
Thuật toán hoạt động như thế nào?
Nó hoạt động theo bốn bước:
- Chọn các mẫu ngẫu nhiên từ tập dữ liệu đã cho.
- Thiết lập cây quyết định cho từng mẫu và nhận kết quả dự đoán từ mỗi quyết định cây.
- Hãy bỏ phiếu cho mỗi kết quả dự đoán.
- Chọn kết quả được dự đoán nhiều nhất là dự đoán cuối cùng.
Ưu điểm: Random forests được coi là một phương pháp chính xác và mạnh mẽ vì số cây quyết định tham gia vào quá trình này. Nó không bị vấn đề overfitting. Lý do chính là nó mất trung bình của tất cả các dự đoán, trong đó hủy bỏ những thành kiến. Thuật toán có thể được sử dụng trong cả hai vấn đề phân loại và hồi quy. Random forests cũng có thể xử lý các giá trị còn thiếu. Có hai cách để xử lý các giá trị này: sử dụng các giá trị trung bình để thay thế các biến liên tục và tính toán mức trung bình gần kề của các giá trị bị thiếu. Bạn có thể nhận được tầm quan trọng của tính năng tương đối, giúp chọn các tính năng đóng góp nhiều nhất cho trình phân loại. Nhược điểm: Random forests chậm tạo dự đoán bởi vì nó có nhiều cây quyết định. Bất cứ khi nào nó đưa ra dự đoán, tất cả các cây trong rừng phải đưa ra dự đoán cho cùng một đầu vào cho trước và sau đó thực hiện bỏ phiếu trên đó. Toàn bộ quá trình này tốn thời gian. Mô hình khó hiểu hơn so với cây quyết định, nơi bạn có thể dễ dàng đưa ra quyết định bằng cách đi theo đường dẫn trong cây.
Các tính năng quan trọng
Random forests cũng cung cấp một chỉ số lựa chọn tính năng tốt. Scikit-learn cung cấp thêm một biến với mô hình, cho thấy tầm quan trọng hoặc đóng góp tương đối của từng tính năng trong dự đoán. Nó tự động tính toán điểm liên quan của từng tính năng trong giai đoạn đào tạo. Sau đó, nó cân đối mức độ liên quan xuống sao cho tổng của tất cả các điểm là 1.
Điểm số này sẽ giúp bạn chọn các tính năng quan trọng nhất và thả các tính năng quan trọng nhất để xây dựng mô hình.
Random forests sử dụng tầm quan trọng của gini hoặc giảm tạp chất trung bình (MDI) để tính toán tầm quan trọng của từng tính năng. Gini tầm quan trọng còn được gọi là tổng giảm trong tạp chất nút. Đây là mức độ phù hợp hoặc độ chính xác của mô hình giảm khi bạn thả biến. Độ lớn càng lớn thì biến số càng có ý nghĩa. Ở đây, giảm trung bình là một tham số quan trọng cho việc lựa chọn biến. Chỉ số Gini có thể mô tả sức mạnh giải thích tổng thể của các biến. Random Forests và cây quyết định Random Forests là một tập hợp của nhiều cây quyết định. Cây quyết định sâu có thể bị ảnh hưởng quá mức, nhưng Random forests ngăn cản việc lấp đầy bằng cách tạo cây trên các tập con ngẫu nhiên. Cây quyết định nhanh hơn tính toán. Random forests khó giải thích, trong khi cây quyết định có thể diễn giải dễ dàng và có thể chuyển đổi thành quy tắc.
Xây dựng một Trình phân loại bằng cách sử dụng Scikit-learn
Bạn sẽ xây dựng một mô hình trên tập dữ liệu hoa iris, đó là một bộ phân loại rất nổi tiếng. Nó bao gồm chiều dài vách ngăn, chiều rộng vách ngăn, chiều dài cánh hoa, chiều rộng cánh hoa và loại hoa. Có ba loài hoặc lớp: setosa, versicolor và virginia. Bạn sẽ xây dựng một mô hình để phân loại loại hoa. Tập dữ liệu có sẵn trong thư viện scikit-learning hoặc bạn có thể tải xuống từ UCI Machine Learning Repository.
Bắt đầu bằng cách nhập thư viện datasets từ scikit-learn và tải tập dữ liệu iris bằng load_iris ().
#Import scikit-learn dataset library
from sklearn import datasets
#Load dataset
iris = datasets.load_iris()
Bạn có thể in tên mục tiêu và đối tượng địa lý, để đảm bảo bạn có tập dữ liệu phù hợp, như vậy:
# print the label species(setosa, versicolor,virginica)
print(iris.target_names)
# print the names of the four features
print(iris.feature_names)
['setosa' 'versicolor' 'virginica']
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
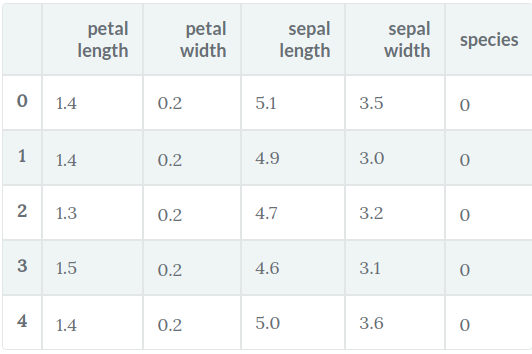
Bạn nên luôn khám phá dữ liệu của mình một chút để biết bạn đang làm việc với cái gì. Tại đây, bạn có thể thấy năm hàng đầu tiên của tập dữ liệu được in, cũng như biến mục tiêu cho toàn bộ tập dữ liệu.
# print the iris data (top 5 records)
print(iris.data[0:5])
# print the iris labels (0:setosa, 1:versicolor, 2:virginica)
print(iris.target)
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Ở đây, bạn có thể tạo một DataFrame của tập dữ liệu iris theo cách sau.
# Creating a DataFrame of given iris dataset.
import pandas as pd
data=pd.DataFrame({
'sepal length':iris.data[:,0],
'sepal width':iris.data[:,1],
'petal length':iris.data[:,2],
'petal width':iris.data[:,3],
'species':iris.target
})
data.head()
 Trước tiên, bạn tách các cột thành các biến phụ thuộc và độc lập (hoặc các tính năng và nhãn). Sau đó, bạn chia các biến đó thành một tập huấn luyện và kiểm tra.
Trước tiên, bạn tách các cột thành các biến phụ thuộc và độc lập (hoặc các tính năng và nhãn). Sau đó, bạn chia các biến đó thành một tập huấn luyện và kiểm tra.
# Import train_test_split function
from sklearn.model_selection import train_test_split
X=data[['sepal length', 'sepal width', 'petal length', 'petal width']] # Features
y=data['species'] # Labels
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% test
Sau khi tách, bạn sẽ đào tạo mô hình trên tập huấn luyện và thực hiện các dự đoán trên tập kiểm tra.
#Import Random Forest Model
from sklearn.ensemble import RandomForestClassifier
#Create a Gaussian Classifier
clf=RandomForestClassifier(n_estimators=100)
#Train the model using the training sets y_pred=clf.predict(X_test)
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
Sau khi đào tạo, kiểm tra tính chính xác bằng cách sử dụng giá trị thực tế và dự đoán.
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
('Accuracy:', 0.93333333333333335)
Bạn cũng có thể đưa ra dự đoán cho một mục, ví dụ:
sepal length = 3
sepal width = 5
petal length = 4
petal width = 2
Bây giờ bạn có thể dự đoán loại hoa nào.
clf.predict([[3, 5, 4, 2]])
array([2])
Ở đây, 2 cho biết loại hoa Virginica
Các tính năng quan trọng trong Scikit-learn
Ở đây, bạn đang tìm các tính năng quan trọng hoặc chọn các tính năng trong tập dữ liệu IRIS. Trong quá trình tìm hiểu, bạn có thể thực hiện tác vụ này trong các bước sau:
Đầu tiên, bạn cần tạo một mô hình Random Forests. Thứ hai, sử dụng biến quan trọng của tính năng để xem điểm quan trọng của đối tượng địa lý. Thứ ba, hình dung các điểm số này bằng thư viện
from sklearn.ensemble import RandomForestClassifier
#Create a Gaussian Classifier
clf=RandomForestClassifier(n_estimators=100)
#Train the model using the training sets y_pred=clf.predict(X_test)
clf.fit(X_train,y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
import pandas as pd
feature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)
feature_imp
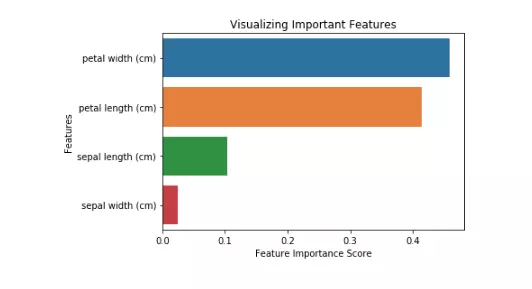
petal width (cm) 0.458607
petal length (cm) 0.413859
sepal length (cm) 0.103600
sepal width (cm) 0.023933
dtype: float64
Bạn cũng có thể hình dung tầm quan trọng của đối tượng địa lý. Hình ảnh dễ hiểu và dễ hiểu.
Để hiển thị, bạn có thể sử dụng kết hợp matplotlib và seaborn. Bởi vì seaborn được xây dựng trên đầu trang của matplotlib, nó cung cấp một số chủ đề tùy chỉnh và cung cấp các loại cốt truyện bổ sung. Matplotlib là một superset của seaborn và cả hai đều quan trọng không kém cho visualizations tốt. Thứ ba, hình dung những điểm số bằng cách sử dụng thư viện seaborn.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# Creating a bar plot
sns.barplot(x=feature_imp, y=feature_imp.index)
# Add labels to your graph
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.title("Visualizing Important Features")
plt.legend()
plt.show()
 Tạo mô hình trên các tính năng được chọn
Tại đây, bạn có thể loại bỏ tính năng "chiều rộng sepal" vì nó có tầm quan trọng rất thấp và chọn 3 tính năng còn lại.
Tạo mô hình trên các tính năng được chọn
Tại đây, bạn có thể loại bỏ tính năng "chiều rộng sepal" vì nó có tầm quan trọng rất thấp và chọn 3 tính năng còn lại.
# Import train_test_split function
from sklearn.cross_validation import train_test_split`
# Split dataset into features and labels
X=data[['petal length', 'petal width','sepal length']] # Removed feature "sepal length"
y=data['species']
`# Split dataset into training set and test set`
`X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.70, random_state=5) # 70% training and 30% test`
Sau khi chia nhỏ, bạn sẽ tạo ra một mô hình trên các tính năng tập huấn được chọn, thực hiện các dự đoán về các tính năng bộ thử đã chọn và so sánh các giá trị thực tế và được dự đoán.
from sklearn.ensemble import RandomForestClassifier
#Create a Gaussian Classifier
clf=RandomForestClassifier(n_estimators=100)
#Train the model using the training sets y_pred=clf.predict(X_test)
clf.fit(X_train,y_train)
`# prediction on test set`
y_pred=clf.predict(X_test)
#Import scikit-learn metrics module for accuracy calculation
from sklearn import metrics
`# Model Accuracy, how often is the classifier correct?`
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
('Accuracy:', 0.95238095238095233)
Bạn có thể thấy rằng sau khi loại bỏ các tính năng ít quan trọng nhất (chiều dài sepal), độ chính xác tăng lên. Điều này là do bạn đã xóa dữ liệu gây hiểu lầm và tiếng ồn, dẫn đến độ chính xác tăng lên. Một số lượng ít tính năng hơn cũng làm giảm thời gian đào tạo.
Phần kết luận Trong hướng dẫn này, bạn đã biết được Random Forests là gì, nó hoạt động như thế nào, tìm ra các tính năng quan trọng, so sánh giữa Random Forests và cây quyết định, lợi thế và bất lợi. Bạn cũng đã học xây dựng mô hình, đánh giá và tìm các tính năng quan trọng trong scikit-learn.
All rights reserved
