Phân loại bằng Naive Bayes — phần 1
Bài đăng này đã không được cập nhật trong 7 năm
Naive Bayes là một thuật toán đơn giản nhưng mạnh mẽ đáng ngạc nhiên cho mô hình dự đoán.
Trong bài viết này, bạn sẽ khám phá thuật toán Naive Bayes để phân loại. Sau khi đọc bài đăng này, bạn sẽ biết:
- Các đại diện được sử dụng bởi Naive Bayes thực sự được lưu trữ khi một mô hình được ghi vào một tệp.
- Làm thế nào một mô hình đã học có thể được sử dụng để đưa ra dự đoán.
- Làm thế nào bạn có thể học một mô hình Naive Bayes từ dữ liệu đào tạo.
- Làm thế nào để chuẩn bị tốt nhất dữ liệu của bạn cho thuật toán Naive Bayes.
- Đi đâu để biết thêm thông tin về Naive Bayes.
Giới thiệu nhanh về Định lý Bayes
Trong học máy, chúng ta thường quan tâm đến việc chọn giả thuyết tốt nhất (h) dữ liệu đã cho (d).
Trong một vấn đề phân loại, giả thuyết của chúng tôi (h) có thể là lớp để gán cho một thể hiện dữ liệu mới (d).
Một trong những cách dễ nhất để chọn giả thuyết có thể xảy ra nhất dựa trên dữ liệu mà chúng ta có mà chúng ta có thể sử dụng làm kiến thức trước đây về vấn đề này. Định lý Bayes cung cấp một cách mà chúng ta có thể tính toán xác suất của một giả thuyết dựa trên kiến thức trước đây của chúng ta.
Định lý Bayes được nêu là:
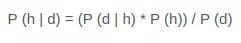 Ở đây
Ở đây
- P (h | d) là xác suất của giả thuyết h đưa ra dữ liệu d. Điều này được gọi là xác suất sau.
- P (d | h) là xác suất của dữ liệu d cho rằng giả thuyết h là đúng.
- P (h) là xác suất của giả thuyết h là đúng (bất kể dữ liệu). Đây được gọi là xác suất trước của h.
- P (d) là xác suất của dữ liệu (bất kể giả thuyết). Bạn có thể thấy rằng chúng tôi quan tâm đến việc tính xác suất sau của P (h | d) từ xác suất trước p (h) với P (D) và P (d | h).
Sau khi tính toán xác suất sau cho một số giả thuyết khác nhau, bạn có thể chọn giả thuyết có xác suất cao nhất. Đây là giả thuyết có thể xảy ra tối đa và có thể chính thức được gọi là giả thuyết tối đa (MAP).
Điều này có thể được viết là:
 P (d) là một thuật ngữ chuẩn hóa cho phép chúng ta tính xác suất. Chúng ta có thể bỏ nó khi chúng ta quan tâm đến giả thuyết có thể xảy ra nhất vì nó không đổi và chỉ được sử dụng để bình thường hóa.
P (d) là một thuật ngữ chuẩn hóa cho phép chúng ta tính xác suất. Chúng ta có thể bỏ nó khi chúng ta quan tâm đến giả thuyết có thể xảy ra nhất vì nó không đổi và chỉ được sử dụng để bình thường hóa.
Quay lại phân loại, nếu chúng ta có số lượng phiên bản chẵn trong mỗi lớp trong dữ liệu đào tạo của mình, thì xác suất của mỗi lớp (ví dụ P (h)) sẽ bằng nhau. Một lần nữa, đây sẽ là một thuật ngữ không đổi trong phương trình của chúng tôi và chúng tôi có thể bỏ nó để chúng tôi kết thúc với:
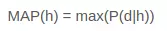
Naive Bayes Classifier
Naive Bayes là một thuật toán phân loại cho các vấn đề phân loại nhị phân (hai lớp) và đa lớp. Kỹ thuật này dễ hiểu nhất khi được mô tả bằng các giá trị đầu vào nhị phân hoặc phân loại.
Nó được gọi là Naive Bayes bởi vì việc tính toán xác suất cho mỗi giả thuyết được đơn giản hóa để làm cho phép tính của họ có thể thực hiện được. Thay vì cố gắng tính các giá trị của từng giá trị thuộc tính 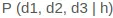 , chúng được giả định là độc lập có điều kiện với giá trị đích và được tính là
, chúng được giả định là độc lập có điều kiện với giá trị đích và được tính là  .
.
Đây là một giả định rất mạnh mà hầu như không có trong dữ liệu thực, tức là các thuộc tính không tương tác. Tuy nhiên, cách tiếp cận thực hiện tốt đáng ngạc nhiên trên dữ liệu mà giả định này không giữ được.
Đại diện được sử dụng bởi mô hình Naive Bayes
Đại diện cho Naive Bayes là xác suất.
Một danh sách các xác suất được lưu trữ để nộp cho một mô hình Naive Bayes đã học. Điêu nay bao gôm:
- Xác suất lớp : Xác suất của mỗi lớp trong tập dữ liệu huấn luyện.
- Xác suất có điều kiện : Xác suất có điều kiện của từng giá trị đầu vào được cung cấp cho mỗi giá trị lớp.
Tìm hiểu mô hình Naive Bayes từ dữ liệu
Học một mô hình Naive Bayes từ dữ liệu đào tạo của bạn rất nhanh.
Đào tạo là nhanh bởi vì chỉ có xác suất của mỗi lớp và xác suất của mỗi lớp được cung cấp các giá trị đầu vào (x) khác nhau cần phải được tính toán. Không có hệ số cần phải được trang bị bởi các thủ tục tối ưu hóa.
Tính xác suất của lớp
Các xác suất của lớp chỉ đơn giản là tần suất của các thể hiện thuộc về mỗi lớp chia cho tổng số thể hiện.
Ví dụ: trong phân loại nhị phân, xác suất của một thể hiện thuộc lớp 1 sẽ được tính như sau:
 Trong trường hợp đơn giản nhất, mỗi lớp sẽ có xác suất 0,5 hoặc 50% cho một vấn đề phân loại nhị phân có cùng số lượng phiên bản trong mỗi lớp.
Trong trường hợp đơn giản nhất, mỗi lớp sẽ có xác suất 0,5 hoặc 50% cho một vấn đề phân loại nhị phân có cùng số lượng phiên bản trong mỗi lớp.
Tính xác suất có điều kiện
Các xác suất có điều kiện là tần số của từng giá trị thuộc tính cho một giá trị lớp đã cho chia cho tần số của các thể hiện với giá trị lớp đó.
Ví dụ: nếu thuộc tính thời tiết của người Hồi giáo có các giá trị là nắng Nắng và thuộc tính mưa và thuộc tính lớp có các giá trị lớp thì đi ra ngoài và ở lại nhà , thì xác suất có điều kiện của từng giá trị thời tiết cho mỗi lớp giá trị có thể được tính như sau:
- P (thời tiết = nắng | lớp = đi ra) = đếm (trường hợp với thời tiết = nắng và lớp = đi ra ngoài) / đếm (trường hợp với lớp = đi ra ngoài)
- P (thời tiết = nắng | lớp = ở nhà) = đếm (trường hợp với thời tiết = nắng và lớp = ở nhà) / đếm (trường hợp với lớp = ở nhà)
- P (thời tiết = mưa | lớp = đi ra) = đếm (trường hợp với thời tiết = mưa và lớp = đi ra ngoài) / đếm (trường hợp với lớp = đi ra ngoài)
- P (thời tiết = mưa | lớp = ở nhà) = đếm (trường hợp với thời tiết = mưa và lớp = ở nhà) / đếm (trường hợp với lớp = ở nhà)
Đưa ra dự đoán với mô hình Naive Bayes
Đưa ra một mô hình BaNaive Bayes, bạn có thể đưa ra dự đoán cho dữ liệu mới bằng định lý Bayes.
MAP (h) = max (P (d | h) * P (h))
Sử dụng ví dụ trên, nếu chúng ta có một đối tượng mới với thời tiết của nắng , chúng ta có thể tính toán:
đi ra ngoài = P (thời tiết = nắng | lớp = đi ra ngoài) * P (lớp = đi ra)
ở lại nhà = P (thời tiết = nắng | lớp = ở nhà) * P (lớp = ở nhà)
Chúng ta có thể chọn lớp có giá trị tính toán lớn nhất. Chúng ta có thể biến các giá trị này thành xác suất bằng cách chuẩn hóa chúng như sau:
P (đi ra ngoài | thời tiết = nắng) = đi ra ngoài / (đi ra ngoài + ở nhà)
P (ở nhà | thời tiết = nắng) = ở nhà / (đi ra ngoài + ở nhà)
Nếu chúng ta có nhiều biến đầu vào hơn, chúng ta có thể mở rộng ví dụ trên. Ví dụ: giả vờ chúng ta có một thuộc tính của Xe car với các giá trị làm việc của Google và bị hỏng . Chúng ta có thể nhân xác suất này vào phương trình.
Ví dụ dưới đây là phép tính cho nhãn lớp go-out trực tuyến của Sony với việc bổ sung biến đầu vào ô tô được đặt thành cách làm việc của Wap:
đi ra ngoài = P (thời tiết = nắng | lớp = đi ra ngoài) * P (xe = làm việc | lớp = đi ra ngoài) * P (lớp = đi ra ngoài)
Ở phần sau chúng ta tiếp tục tìm hiểu về Gaussian Naive Bayes.
All rights reserved
