[Paper Explain]-DiffSensei: Kết Hợp LLM và Diffusion Model Để Tạo Manga
Trong thế giới truyện tranh đầy màu sắc và sáng tạo, manga không chỉ đơn thuần là nghệ thuật, mà còn là những câu chuyện giàu cảm xúc, kết hợp tinh tế giữa nội dung và hình ảnh. Với sự phát triển mạnh mẽ của AI giờ đây ngay cả khi bạn không có năng khiếu về vẽ tranh bạn vẫn có thể tạo ra những trang manga chân thực , sống động từ mô tả bằng ngôn ngữ tự nhiên. DiffSensei – một giải pháp đột phá, kết hợp sức mạnh của các mô hình ngôn ngữ lớn đa phương thức (Multimodal LLMs) và các mô hình khuếch tán (Diffusion Models), mang đến khả năng tạo ra các trang manga được cá nhân hóa, sống động và đầy tính nghệ thuật.
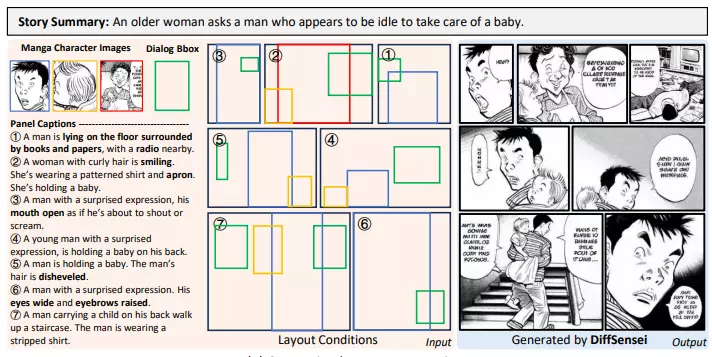
1. DiffSensei là gì ?
DiffSensei là mô hình được thiết kế đặc biệt để tạo ra các trang truyện manga với khả năng kiểm soát đa nhân vật. Điểm nổi bật của DiffSensei nằm ở khả năng tùy chỉnh linh hoạt hình ảnh nhân vật, bố cục trang truyện, và hội thoại dựa trên yêu cầu của người dùng. Mục tiêu của DiffSensei là cho phép người dùng tùy chỉnh nhiều yếu tố của truyện tranh, bao gồm:
- Hình ảnh nhân vật: Người dùng có thể cung cấp hình ảnh của nhân vật và DiffSensei sẽ tạo ra các khung tranh với những nhân vật này.
- Tùy chỉnh nhân vật: Bao gồm thay đổi trang phục, kiểu tóc, biểu cảm, tư thế và hành động của nhân vật sao cho phù hợp với yêu cầu của người dùng.
- Bố cục trang truyện: Vị trí của các khung tranh, nhân vật và hội thoại có thể được điều chỉnh theo ý muốn.
- Hội thoại: DiffSensei có khả năng tạo ra hội thoại cho các nhân vật trong truyện.
- Biểu cảm và hành động của nhân vật: Mô hình có thể điều chỉnh biểu cảm và hành động của nhân vật dựa trên văn bản mô tả.
2. Thách thức của các mô hình tạo sinh hiện tại
Mặc dù các mô hình text-to-image đã đạt được những bước tiến lớn, nhưng khi áp dụng vào manga – một thể loại đòi hỏi cao về tính thống nhất của nhân vật và kiểm soát bố cục – thì chúng vẫn tồn tại nhiều hạn chế. Các vấn đề phổ biến bao gồm:
- Sự thiếu nhất quán giữa các khung hình: Các nhân vật không giữ được diện mạo đồng nhất khi xuất hiện nhiều lần.
- Thiếu kiểm soát bố cục: Các mô hình hiện tại chưa có khả năng kiểm soát chi tiết bố cục trang truyện, chẳng hạn như vị trí của khung tranh, nhân vật và hội thoại.
- Giới hạn trong biểu đạt nhân vật: Khó thay đổi biểu cảm, tư thế, và hành động dựa trên ngữ cảnh truyện.
- Hiệu ứng "copy-paste": Một số mô hình cho phép tùy chỉnh nhân vật bằng cách sử dụng hình ảnh tham chiếu, nhưng thường dẫn đến hiệu ứng "copy-paste" cứng cứng, khiến nhân vật thiếu sự linh hoạt về biểu cảm và hành động. Vấn đề này phát sinh một phần do thiếu dữ liệu huấn luyện về nhiều trạng thái khác nhau của cùng một nhân vật.
- Khó khăn trong việc tạo văn bản: Hầu hết các mô hình text-to-image hiện tại gặp khó khăn trong việc tạo ra văn bản rõ ràng và dễ đọc, đặc biệt là đối với văn bản dài như hội thoại.
DiffSensei đã giải quyết những hạn chế này bằng cách:
- Sử dụng MLLM (Multimodal LLMs) làm bộ điều hợp đặc trưng nhân vật: Cho phép điều chỉnh linh hoạt các đặc điểm của nhân vật dựa trên văn bản mô tả, giúp nhân vật thể hiện biểu cảm và hành động phù hợp với ngữ cảnh.
- Áp dụng cơ chế masked attention injection: Kiểm soát bố cục của từng nhân vật bằng cách giới hạn vùng chú ý của mô hình trong phạm vi khung giới hạn của nhân vật.
- Sử dụng kỹ thuật dialog embedding: Mã hóa bố cục hội thoại hiệu quả bằng cách nhúng thông tin vị trí khung thoại vào mô hình.
- Huấn luyện trên bộ dữ liệu lớn MangaZero: Bộ dữ liệu quy mô lớn với chú thích chi tiết về nhân vật và hội thoại, cung cấp cho mô hình kiến thức phong phú về phong cách manga và sự đa dạng về trạng thái của nhân vật.
=> Nhờ những cải tiến này, DiffSensei đã vượt qua những hạn chế của các mô hình hiện có và tạo ra những trang truyện manga chất lượng cao hơn, đồng thời cung cấp cho người dùng khả năng kiểm soát chi tiết hơn.
3. Kiến trúc mô hình
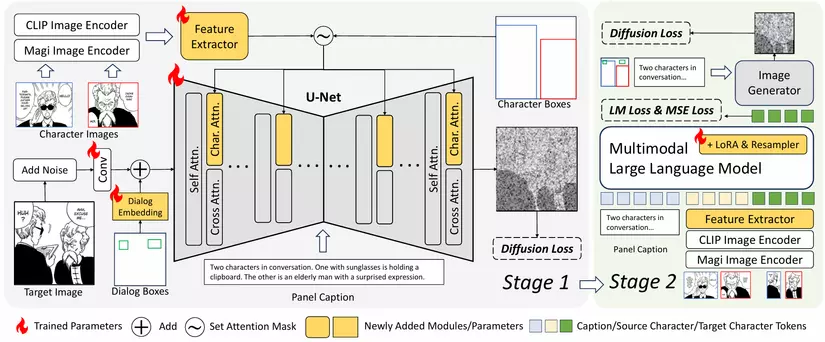 DiffSensei tận dụng sức mạnh kết hợp của Diffusion Model và Multi-modal Large Language Model (MLLM) để tạo ra những trang manga tùy chỉnh theo yêu cầu của người dùng. Hai công nghệ này đóng vai trò then chốt trong việc kiểm soát hình ảnh, bố cục và nội dung của manga.
DiffSensei tận dụng sức mạnh kết hợp của Diffusion Model và Multi-modal Large Language Model (MLLM) để tạo ra những trang manga tùy chỉnh theo yêu cầu của người dùng. Hai công nghệ này đóng vai trò then chốt trong việc kiểm soát hình ảnh, bố cục và nội dung của manga.
1. Diffusion Model (Mô hình khuếch tán):
- Vai trò: Diffusion Model là "xương sống" của DiffSensei, chịu trách nhiệm chính trong việc tạo ra hình ảnh manga.
- Cơ chế hoạt động:
- Giai đoạn huấn luyện: Mô hình học cách thêm nhiễu vào hình ảnh cho đến khi hình ảnh trở nên hoàn toàn nhiễu loạn. Sau đó, nó học cách đảo ngược quá trình này, loại bỏ nhiễu từ hình ảnh nhiễu loạn để khôi phục hình ảnh gốc.
- Giai đoạn tạo sinh: Mô hình nhận một hình ảnh nhiễu loạn ngẫu nhiên làm đầu vào và sử dụng những gì đã học trong giai đoạn huấn luyện để dần dần loại bỏ nhiễu, tạo ra một hình ảnh manga mới.
=> Diffusion Model cho phép tạo ra hình ảnh chất lượng cao, đa dạng và sống động.
2. MLLM (Mô hình ngôn ngữ lớn đa phương thức):
- Vai trò: MLLM đóng vai trò là "bộ não" của DiffSensei, hiểu và phản hồi văn bản để điều chỉnh hình ảnh manga theo ý muốn của người dùng.
- Cơ chế hoạt động:
- Tiếp nhận thông tin: MLLM nhận chú thích văn bản mô tả nội dung của trang manga, đặc trưng hình ảnh nhân vật nguồn và đặc trưng hình ảnh nhân vật đích làm đầu vào.
- Tạo đặc trưng nhân vật: Dựa trên thông tin nhận được, MLLM sử dụng kỹ thuật LoRA và resampler để tạo ra đặc trưng hình ảnh nhân vật đích phù hợp với nội dung chú thích.
- Điều chỉnh hình ảnh: Đặc trưng nhân vật đích được truyền vào Diffusion Model để điều chỉnh hình ảnh, thay đổi biểu cảm, tư thế và hành động của nhân vật.
=> MLLM giúp tăng cường khả năng tương tác văn bản cho DiffSensei, cho phép mô hình tạo ra những hình ảnh manga thể hiện rõ nét nội dung của chú thích.
Sự kết hợp giữa Diffusion Model và MLLM mang đến cho DiffSensei những khả năng vượt trội:
- Kiểm soát bố cục linh hoạt: Sử dụng masked cross-attention injection và dialog embedding, DiffSensei có thể kiểm soát vị trí của nhân vật và hội thoại trong trang manga.
- Tạo nhân vật đa dạng: Bộ trích xuất đặc trưng đa nhân vật và MLLM cho phép tạo ra nhiều nhân vật khác nhau, mỗi nhân vật có đặc điểm riêng biệt.
- Thích ứng với văn bản: MLLM giúp DiffSensei hiểu và phản hồi chú thích văn bản, điều chỉnh hình ảnh để thể hiện nội dung của câu chuyện. => Sự kết hợp giữa Diffusion Model và MLLM là yếu tố then chốt tạo nên sức mạnh của DiffSensei. Hai công nghệ này bổ sung cho nhau, giúp mô hình tạo ra những trang manga tùy chỉnh, chất lượng cao và thể hiện rõ nét ý tưởng của người dùng.
4. Phương pháp
DiffSensei sử dụng một kiến trúc phức tạp kết hợp nhiều thành phần để tạo ra manga tùy chỉnh. Có thể tóm tắt kiến trúc hoạt động theo các bước như sau:
1. Trích xuất đặc trưng của nhân vật:
- DiffSensei sử dụng CLIP và một bộ mã hóa hình ảnh manga (Magi) để trích xuất đặc trưng hình ảnh cục bộ và cấp độ hình ảnh từ hình ảnh nhân vật đầu vào.Ở đó, CLIP trích xuất đặc trưng cấp độ hình ảnh, trong khi Magi tập trung vào đặc trưng cấp độ manga, giúp mô hình hiểu rõ hơn về phong cách và chi tiết đặc trưng của manga.
- Các đặc trưng này sau đó được xử lý bởi một bộ trích xuất đặc trưng, được triển khai dưới dạng module resampler.
- Quá trình này nén hình ảnh nhân vật thành token để tập trung vào ngữ nghĩa thay vì sao chép pixel và còn giúp tránh việc mã hóa các đặc trưng không gian chi tiết từ hình ảnh tham chiếu vào mô hình.
--> Điều này cho phép mô hình tập trung vào biểu diễn ngữ nghĩa của nhân vật hơn là phân phối pixel cứng nhắc, giúp tránh hiệu ứng "copy-paste".
2. Cơ chế Masked Cross-Attention Injection:
- DiffSensei sử dụng masked cross-attention injection để kiểm soát bố cục của từng nhân vật.
- Mỗi đặc trưng nhân vật chỉ chú ý đến các đặc trưng truy vấn trong vùng giới hạn của nó. Ở những vùng không có nhân vật, các đặc trưng truy vấn sẽ chú ý đến một placeholder vector để tránh nhiễu từ các vùng không liên quan.
- Kỹ thuật này đảm bảo rằng mỗi nhân vật chỉ được tạo ra trong khung giới hạn được chỉ định, mà còn duy trì tính nhất quán về đặc điểm và hành động theo từng khung tranh.
- Lợi ích nổi bật của cơ chế này :
- Kiểm soát chính xác bố cục: Các nhân vật không bị chồng lấn hoặc xuất hiện ngoài vị trí mong muốn, đảm bảo phù hợp với cốt truyện.
- Duy trì sự rõ ràng về hình ảnh: Giảm thiểu các yếu tố gây nhiễu, tập trung vào các chi tiết quan trọng của nhân vật.
- Linh hoạt trong biểu cảm và hành động: Cơ chế này cũng giúp các nhân vật dễ dàng thay đổi tư thế hoặc biểu cảm mà không làm mất đi tính toàn vẹn của bố cục tổng thể.
3. Mã hóa bố cục hội thoại (Dialog Embedding):
- DiffSensei sử dụng trainable embedding để biểu diễn bố cục hội thoại.
- Dialog embedding được mở rộng để phù hợp với hình dạng không gian của latent bị nhiễu và sau đó được che bằng bố cục hội thoại.
- Bằng cách cộng dialog embedding đã được che với latent bị nhiễu, DiffSensei có thể mã hóa vị trí hội thoại trong bộ tạo hình ảnh.
4. MLLM đóng vai trò như bộ điều hợp đặc trưng nhân vật tương thích văn bản:
- Sau khi huấn luyện bộ tạo hình ảnh, DiffSensei có thể tạo ra các trang manga tuân thủ hình ảnh nhân vật và điều kiện bố cục.
- Tuy nhiên, để tăng cường khả năng điều chỉnh biểu cảm, tư thế và hành động của nhân vật dựa trên chú thích văn bản, DiffSensei sử dụng MLLM như một bộ điều hợp đặc trưng nhân vật tương thích văn bản.
- Bằng cách sử dụng Language Modeling Loss và Mean Squared Error Loss, MLLM được huấn luyện để tạo ra đặc trưng nhân vật đích phù hợp với chú thích văn bản.
- Đặc trưng nhân vật đã được điều chỉnh này sau đó được truyền vào bộ tạo hình ảnh để tạo ra hình ảnh cuối cùng.
5. Kết quả thực nghiệm
DiffSensei đã chứng minh hiệu suất vượt trội so với các mô hình tạo truyện tranh từ văn bản hiện có trên nhiều khía cạnh, bao gồm:
- Quantitative comparisons on automatic metrics:
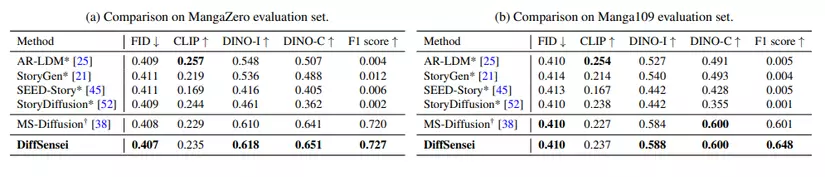
- DiffSensei đạt điểm cao hơn trên các chỉ số đánh giá tự động như FID, CLIP, DINO-I, DINO-C và F1 score so với các mô hình cơ sở, cả trên tập đánh giá MangaZero và Manga109.
- DiffSensei thể hiện khả năng hiểu và phản hồi văn bản tốt hơn so với MS-Diffusion, một mô hình tùy chỉnh đa chủ thể, thể hiện qua điểm CLIP cao hơn đáng kể.
- Mặc dù AR-LDM đạt điểm CLIP cao hơn, nhưng nó lại bị điểm DINO-C thấp do không có khả năng quản lý nhiều nhân vật. Ngược lại, DiffSensei cân bằng tốt giữa việc duy trì diện mạo của nhân vật và khả năng thích ứng với văn bản.
- Qualitative comparison with baselines:
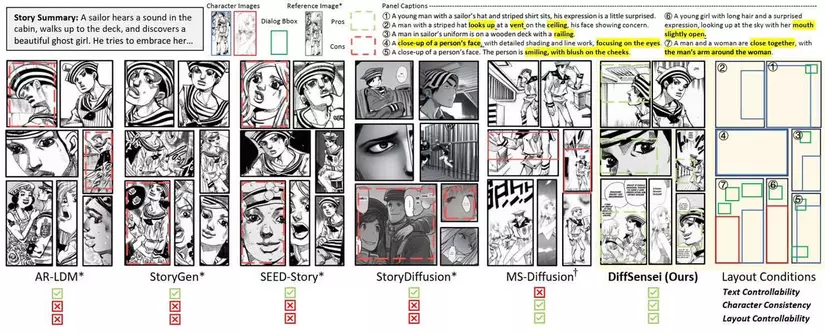
- SEED-Story tạo ra những câu chuyện rời rạc và thiếu mạch lạc do hạn chế trong việc dự đoán chú thích.
- StoryDiffusion bị giới hạn trong việc tạo hình ảnh có độ phân giải cố định, dẫn đến kết quả kém khi đầu vào có tỷ lệ khung hình không cân đối.
- MS-Diffusion thiếu linh hoạt trong việc điều chỉnh diện mạo của nhân vật dựa trên văn bản.
- DiffSensei thể hiện khả năng tuân thủ văn bản, bảo tồn đặc điểm nhân vật và trình bày câu chuyện tổng thể tốt hơn.
=> Tóm lại, DiffSensei thể hiện hiệu suất vượt trội so với các mô hình khác trong việc tạo manga tùy chỉnh, cả về kết quả định lượng, định tính và ưa thích của con người. DiffSensei tạo ra những trang truyện tranh chất lượng cao hơn, tuân thủ văn bản tốt hơn, và bảo tồn đặc điểm nhân vật hiệu quả hơn, mang đến trải nghiệm đọc truyện hấp dẫn và lôi cuốn hơn.
6. Tài liệu tham khảo
All rights reserved
