[P2] - Lấy dữ liệu website bằng puppeteer
Bài đăng này đã không được cập nhật trong 4 năm
Ở phần 1 mình đã nắm được những kiến thức cơ bản về thằng puppeteer này rồi
Mục tiêu của mình ở phần này là sẽ quét những bài viết to ở mỗi category của trang 24h.com.vn. Sau đó vào từng bài để lấy phần header
1. Lấy link bài viết
Nhắc lại chút kiến thức của phần 1 nhé. Mình sẽ dùng hàm evaluate của thằng puppeteer để chạy js trong browser.
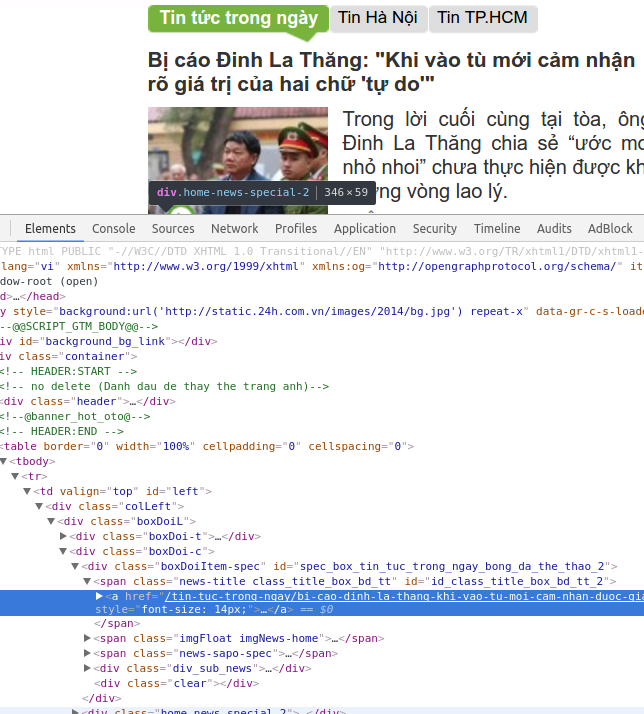 Những bài viết mình muốn lấy nó nằm trong thẻ
Những bài viết mình muốn lấy nó nằm trong thẻ <div class="colLeft"> & <span class="news-title">. Vậy ta vào console của Chrome code tạm trước xem sao đã
// Lấy toàn bộ thẻ a chứa link & title
let titles = document.querySelectorAll("div.colLeft span.news-title a");
let ar_title = [];
// lấy ra link & title của bài viết => đẩy vào mảng ar_title
titles.forEach(item => {
ar_title.push({
href: item.getAttribute('href').trim(),
title: item.getAttribute('title').trim(),
})
});
Vậy là ta đã có được link & title của những bài viết mà ta cần lấy. Áp dụng chỗ code trên vào trong hàm evaluate trong phần 1 nhé
(async() => {
try {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
page.setViewport({width: 1280, height: 720});
await page.goto(URL);
const articles = await page.evaluate(() => {
let titles = document.querySelectorAll("div.colLeft span.news-title a");
let ar_title = [];
titles.forEach(item => {
ar_title.push({
href: item.getAttribute('href').trim(),
title: item.getAttribute('title').trim(),
})
});
return ar_title
});
console.log(ar_title);
await browser.close();
} catch (error) {
console.log("Catch : " + error);
}
})();
2. Vào từng bài viết để lấy content
2.1: Code sai SML
Ta có link từng bài viết rồi. Giờ thì chọc vào từng bài để lấy header thôi. Thử xem sao
Theo hướng thông thường ta sẽ chạy forEach để lấy link sau đó mở 1 page mới => lấy dữ liệu ở trong hàm evaluate
let i = 0;
await Promise.all(articles.map(item => {
return browser.newPage().then(async page => {
await page.goto(URL + item.href);
let title = await page.evaluate(() => {
return document.querySelector("p.baiviet-sapo").innerText;
});
i++;
console.log(i + ': ', title);
// await page.close();
});
}));
Bạn thử chạy code phía trên xem sao
Kinh khủng phải không. Nó bật 1 đống tab, điều này ảnh hưởng nghiêm trọng đến hiệu năng & khiến máy dễ bị treo

2.2: Refactor code lại
Code thế kia thì không xài được rồi. Vậy giờ hướng của ta sẽ là
- Mở trang chủ. Lấy ra list những link bài viết
- Ở tab đó. Di chuyển đến bài viết đầu tiên. Lấy header của bài viết đó
- Ở tab đó. Di chuyển đến bài viết thứ 2. Lấy header của bài viết đó
- Cứ lặp như vậy ta sẽ lấy được hết header của các bài viết mà vẫn đảm bảo được hiệu năng. Chỉ là hơi lâu một chút =))
Ok. Thử nào
Đầu tiên là ta phải loop biến articles để lấy ra url từng bài viết
// chứa danh sách những promise
const promises = [];
for (let i = 0; i < articles.length; i++) {
promises.push(await getTitle(articles[i].href, page, i))
}
Sau đó gọi đến hàm chuyên để lấy header
async function getTitle(link, page, key) {
await page.goto(URL + link, {
// Set timeout cho page
timeout: 3000000
});
// Chờ 2s sau khi page được load để tránh overload
await page.waitFor(2000);
let title = await page.evaluate(() => {
let header = document.querySelector("p.baiviet-sapo");
if (header === null) {
header = document.querySelector("div.imageTitle a");
}
return header.innerText;
});
console.log('Page ID Spawned', key, title);
return page;
}
Done. Bạn thử chạy xem có được như plan mình vạch ra phía trên không
3. Download ảnh được load bằng AJAX
3.1: Mục tiêu
Mình có tìm được 1 trang load content bằng ajax: https://demo.tutorialzine.com/2009/09/simple-ajax-website-jquery/demo.html Mình sẽ tìm cách download ảnh con mèo ở page 3
3.2: Hướng giải quyết
- Goto đến trang đó
- Click vào page 3
- Lấy được đường dẫn ảnh cần download
- Download ảnh đó về
3.3: Practice
Mình sẽ bỏ qua những đoạn code cơ bản nhé
await page.click('#navigation > li:nth-child(3) > a');
await page.waitForSelector('div#pageContent img');
Mình sẽ click vào page 3. Sau đó chờ cho đến khi ảnh con mèo được load ra
Lúc này ta mới dùng hàm evaluate để lấy được đường dẫn của ảnh
const imgUrl = await page.evaluate(() => {
return document.querySelector('div#pageContent img').getAttribute('src');
});
Bạn chú ý là đường dẫn này là tương đối nhé. Chưa có domain
Code để lấy được đường dẫn ảnh của ta sẽ như sau
const puppeteer = require('puppeteer');
let DOMAIN = 'https://demo.tutorialzine.com/2009/09/simple-ajax-website-jquery';
let URL = DOMAIN + '/demo.html';
(async() => {
try {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto(URL);
await page.click('#navigation > li:nth-child(3) > a');
await page.waitForSelector('div#pageContent img');
const imgUrl = await page.evaluate(() => {
return document.querySelector('div#pageContent img').getAttribute('src');
});
console.log(imgUrl);
browser.close()
} catch (error) {
console.log("Catch : " + error);
}
})();
Để download ảnh thì nodejs có bộ lib image-downloader. Bạn có thể tham khảo ở đây
Ta có url rồi. Giờ chỉ việc ghép vào xài thôi
console.log(imgUrl);
const options = {
url: DOMAIN + '/' + imgUrl,
dest: 'images'
};
const { filename, image } = await download.image(options);
browser.close()
Vậy là mình đã hướng dẫn bạn cách lấy được nội dung bài viết & download img được load bằng AJAX
Tất cả code trên đều chỉ là mình tự mày mò nên chắc chắn nó chưa được clear & clean. Rất mong nhận được sự góp ý để code của mình có thể hoàn thiện được hơn
All rights reserved
