Oracle RAC (Real Application Clusters) — Deep Dive
Mục tiêu tài liệu: Giải thích toàn diện kiến trúc Oracle RAC từ nền tảng đến ứng dụng thực tế, bao gồm cơ chế nội bộ, điểm mạnh/yếu, và so sánh với các giải pháp hiện đại.
Mục lục
- RAC là gì và tại sao cần nó?
- Kiến trúc tổng quan
- Các thành phần cốt lõi — giải thích chi tiết
- 3.1 Oracle Instance
- 3.2 Cache Fusion & GCS
- 3.3 GES — Global Enqueue Service
- 3.4 Private Interconnect
- 3.5 Shared Storage & ASM
- 3.6 Voting Disk & OCR
- 3.7 SCAN & VIP
- Luồng Cache Fusion chi tiết
- Điểm mạnh của RAC
- Điểm yếu và rủi ro của RAC
- Ví dụ triển khai thực tế tại Big Tech
- So sánh RAC với các giải pháp hiện đại
- Khi nào nên và không nên dùng RAC?
- Tài liệu tham khảo
1. RAC là gì và tại sao cần nó?
Oracle RAC (Real Application Clusters) là giải pháp cho phép nhiều server (nodes) cùng truy cập và xử lý dữ liệu từ một database duy nhất trên shared storage, tất cả hoạt động đồng thời như một hệ thống thống nhất.
Vấn đề RAC giải quyết
Hệ thống database truyền thống chạy trên một server duy nhất gặp ba vấn đề lớn:
| Vấn đề | Hệ quả | RAC giải quyết bằng cách |
|---|---|---|
| Single Point of Failure | Server chết → toàn bộ hệ thống dừng | Nhiều nodes active-active, node chết thì node khác tiếp quản |
| Giới hạn phần cứng | Muốn mạnh hơn chỉ có thể nâng cấp CPU/RAM (scale-up) | Thêm node mới vào cluster (scale-out) |
| Bảo trì gián đoạn | Patch OS/DB phải downtime | Rolling upgrade — tắt từng node, hệ thống vẫn chạy |
Khái niệm "Active-Active" vs "Active-Standby"
Điểm khác biệt quan trọng nhất của RAC so với các giải pháp HA truyền thống:
- Active-Standby (Data Guard, Patroni): Chỉ một node phục vụ request tại một thời điểm. Node còn lại "chờ" — lãng phí phần cứng.
- Active-Active (RAC): Tất cả nodes đều nhận và xử lý request đồng thời. Không có node nào chờ. Một node
nnodes =nlần throughput (lý thuyết).
2. Kiến trúc tổng quan
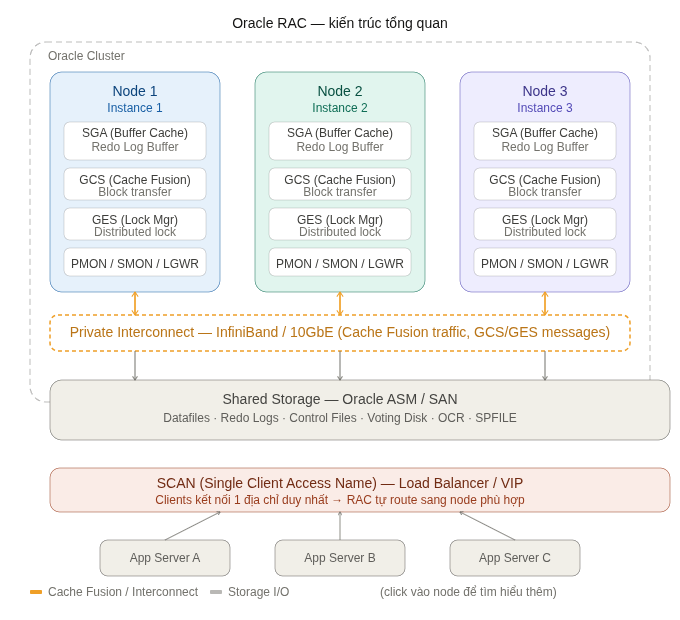
Mô hình tổng quát của một Oracle RAC cluster gồm 3 tầng:
- Tầng trên (Client): Ứng dụng kết nối qua một địa chỉ SCAN duy nhất
- Tầng giữa (Compute): Các nodes chạy Oracle Instance, giao tiếp với nhau qua interconnect
- Tầng dưới (Storage): Shared storage dùng chung, tất cả nodes đọc/ghi trực tiếp
3. Các thành phần cốt lõi — giải thích chi tiết
3.1 Oracle Instance
Mỗi node trong RAC chạy một Oracle Instance độc lập, gồm:
Memory (SGA — System Global Area)
| Vùng nhớ | Chức năng | Ghi chú RAC |
|---|---|---|
| Buffer Cache | Cache data blocks từ datafiles | Được đồng bộ qua Cache Fusion |
| Shared Pool | Cache SQL parsed, PL/SQL code, metadata | Mỗi node có shared pool riêng |
| Redo Log Buffer | Buffer redo entries trước khi ghi xuống disk | Mỗi node có thread redo riêng |
| Large Pool | Dùng cho parallel query, RMAN backup | Tuỳ cấu hình |
| Java Pool | Cho Oracle JVM | Ít dùng |
Điểm quan trọng: Trong RAC, mỗi node có SGA riêng (không chia sẻ RAM), nhưng các Buffer Cache được phối hợp với nhau thông qua Cache Fusion.
Ví dụ: Cluster 4 nodes, mỗi node có Buffer Cache 32GB → tổng "virtual buffer" có thể lên đến 128GB, nhưng thực tế bị chia nhỏ và cần overhead để đồng bộ.
Processes (Background Processes)
Ngoài các process thông thường của Oracle, RAC bổ sung thêm:
| Process | Tên đầy đủ | Vai trò |
|---|---|---|
| LMS | Lock Monitor Service | Gửi/nhận data blocks qua interconnect (Cache Fusion) |
| LMD | Lock Monitor Daemon | Xử lý lock request từ các nodes khác |
| LCK | Lock Process | Quản lý non-PCM (non-cache-fusioned) locks |
| DIAG | Diagnosability Process | Thu thập thông tin diagnostic khi có vấn đề |
| RMSn | RAC Management Service | Quản lý cluster resources |
3.2 Cache Fusion & GCS (Global Cache Service)
Cache Fusion là cơ chế cốt lõi và quan trọng nhất của RAC. Đây là lý do RAC khác biệt hoàn toàn với các giải pháp shared-disk truyền thống.
Vấn đề cần giải quyết: "Stale Read"
Trong môi trường multi-node không có Cache Fusion:
- Node A đọc Block #100 từ disk → cache vào RAM của Node A
- Node B modify Block #100 → ghi xuống disk
- Node A đọc lại Block #100 → vẫn lấy từ RAM (stale/cũ!)
Cache Fusion giải quyết bằng cách track trạng thái của mỗi block trên toàn cluster.
Trạng thái block (Block Modes)
Mỗi block trong cluster tồn tại ở một trong các trạng thái sau:
| Mode | Ký hiệu | Ý nghĩa | Ai có thể giữ |
|---|---|---|---|
| Null | N | Block không được cache ở node này | Bất kỳ node nào |
| Shared (CR) | S | Block đang được đọc, không ai đang ghi | Nhiều nodes cùng lúc |
| Exclusive | X | Block đang được ghi, không ai khác được đọc/ghi | Chỉ 1 node tại một thời điểm |
GCS (Global Cache Service) là dịch vụ quản lý trạng thái này trên toàn cluster. Mỗi block có một "master node" — node chịu trách nhiệm track xem block đó đang ở đâu và ở mode gì.
Consistent Read (CR) Image
Khi Node A cần đọc Block #100 nhưng Node B đang giữ ở mode Exclusive (đang ghi):
- Node B không ghi xuống disk ngay
- Node B tạo một CR (Consistent Read) image — bản copy của block trước khi bị sửa
- Node B gửi CR image sang Node A qua interconnect
- Node A đọc CR image — thấy dữ liệu "nhất quán tại thời điểm query bắt đầu"
Đây là cách Oracle đảm bảo Read Consistency trong RAC mà không cần lock đọc.
3.3 GES — Global Enqueue Service
GES (Global Enqueue Service) là dịch vụ quản lý distributed locking — đảm bảo tính nhất quán khi nhiều nodes cùng truy cập các tài nguyên chia sẻ.
Enqueue là gì?
Trong Oracle, "enqueue" là một lock mechanism để serialize access đến shared resources. Ví dụ:
TXenqueue: lock transactionTMenqueue: lock table (DML operations)STenqueue: space transaction (khi cần extend segment)
Trong RAC, GES mở rộng các enqueue này để hoạt động trên nhiều nodes. Khi Node A giữ TX enqueue và Node B cũng muốn TX enqueue cho cùng row đó, GES sẽ:
- Block Node B lại
- Thông báo cho Node A rằng có node khác đang chờ
- Khi Node A commit/rollback, GES chuyển lock sang Node B
GES Master
Tương tự GCS, mỗi enqueue loại cũng có một "master node" — node chịu trách nhiệm grant/deny enqueue request cho toàn cluster. Master node được phân phối đều trên các nodes theo hash của enqueue name.
Ví dụ thực tế: UPDATE cùng row từ 2 nodes
Node 1: UPDATE accounts SET balance = balance - 100 WHERE id = 42;
Node 2: UPDATE accounts SET balance = balance + 50 WHERE id = 42;
- Node 1 request TX enqueue cho row id=42 từ GES → được cấp
- Node 2 request TX enqueue cho row id=42 → GES thấy Node 1 đang giữ → Node 2 bị block
- Node 1 COMMIT → GES notify Node 2
- Node 2 được cấp lock → thực hiện UPDATE
- Kết quả cuối: balance giảm 100 rồi tăng 50 (hoặc ngược lại tuỳ thứ tự) — không bị lost update
3.4 Private Interconnect
Private Interconnect là mạng nội bộ tốc độ cao kết nối tất cả nodes trong cluster, dùng để truyền:
- Data blocks (Cache Fusion)
- Lock messages (GES)
- Heartbeat signals (cluster membership)
- Global Enqueue messages
Yêu cầu kỹ thuật
| Thuộc tính | Yêu cầu tối thiểu | Khuyến nghị production |
|---|---|---|
| Bandwidth | 1 Gbps | 10–25 Gbps (InfiniBand hoặc RoCE) |
| Latency | < 1ms | < 100μs (InfiniBand ~1–5μs) |
| Redundancy | 1 NIC | 2+ NICs (bonding/teaming) |
| Isolation | Tách biệt với public network | Dedicated switch/VLAN |
Tại sao interconnect latency quan trọng?
Mỗi block transfer qua Cache Fusion cần 1 round-trip trên interconnect. Với throughput 10,000 TPS và mỗi TPS cần trung bình 5 block transfers:
- 10GbE (latency ~200μs): 50,000 × 200μs = 10 giây overhead/giây → không khả thi
- InfiniBand (latency ~5μs): 50,000 × 5μs = 250ms overhead/giây → chấp nhận được
Đây là lý do Oracle khuyến nghị InfiniBand hoặc RoCE cho production RAC.
Interconnect Failure và Split-Brain
Nếu interconnect bị đứt, các nodes không thể liên lạc với nhau. RAC xử lý bằng:
- Voting Disk (xem mục 3.6): các nodes "bỏ phiếu" để xác định node nào còn sống
- Node thua phiếu → bị fence (forced restart hoặc reboot)
- Điều này ngăn chặn split-brain — tình huống 2 nodes đều nghĩ mình là "master" và ghi dữ liệu không nhất quán
3.5 Shared Storage & ASM
Tất cả nodes trong RAC trỏ vào cùng một tập datafiles trên shared storage. Đây là điểm khác biệt cơ bản so với "shared-nothing" architecture (CockroachDB, TiDB).
Các loại shared storage được hỗ trợ
| Loại | Ưu điểm | Nhược điểm | Phổ biến |
|---|---|---|---|
| Oracle ASM | Tích hợp tốt nhất với Oracle, tự quản lý | Chỉ dùng cho Oracle | Khuyến nghị |
| SAN (Fibre Channel) | Hiệu năng cao, mature | Đắt, phức tạp | Phổ biến |
| NFS (NAS) | Đơn giản, rẻ hơn | Latency cao hơn SAN | Chỉ một số vendor |
| iSCSI | Rẻ, dùng Ethernet | Latency cao hơn FC | Non-critical workload |
ASM (Automatic Storage Management)
ASM là volume manager và filesystem riêng của Oracle, thay thế cho LVM + filesystem truyền thống. Nó cung cấp:
- Striping tự động: Phân phối data đều trên các disk để tối đa IOPS
- Mirroring tự động: Normal Redundancy (2-way), High Redundancy (3-way)
- Rebalancing tự động: Khi thêm/xoá disk, ASM tự cân bằng lại data
- Disk Groups: Nhóm các disk lại, gán cho database dùng
Ví dụ ASM Disk Group:
+DATA diskgroup (Normal Redundancy, 4 disks × 2TB = 8TB total, ~4TB usable)
├── /dev/sdb → ASM Disk 1
├── /dev/sdc → ASM Disk 2
├── /dev/sdd → ASM Disk 3
└── /dev/sde → ASM Disk 4
3.6 Voting Disk & OCR
Voting Disk
Voting Disk (hay Quorum Disk) là một vùng lưu trữ đặc biệt trên shared storage, dùng để xác định node nào còn sống khi xảy ra network partition.
Cơ chế hoạt động:
- Mỗi node phải ghi "heartbeat" lên Voting Disk mỗi vài giây
- Nếu node không ghi heartbeat trong thời gian quy định → cluster coi node đó đã chết
- Oracle yêu cầu số lẻ Voting Disks (1, 3, 5) để tránh tie vote
- Node chiếm được majority (> 50%) Voting Disks → node đó "thắng" và tiếp tục chạy
- Node thua → tự reboot ngay lập tức (STONITH — Shoot The Other Node In The Head)
Ví dụ kịch bản 3 nodes, interconnect đứt:
Trước khi đứt: Node1 ✅ Node2 ✅ Node3 ✅ (tất cả vote trên 3 Voting Disks)
Interconnect đứt giữa Node1 và [Node2+Node3]:
- Node1 thấy mình cô lập → chỉ có 1/3 votes → THUA → tự reboot
- Node2+Node3 vẫn thấy nhau → có 2/3 votes → THẮNG → tiếp tục chạy
OCR (Oracle Cluster Registry)
OCR là nơi lưu cấu hình của toàn bộ cluster:
- Danh sách các nodes
- Cấu hình network (VIP, SCAN, interconnect)
- Các Oracle resources (database, services, listeners)
- Cấu hình ASM disk groups
OCR được lưu trên shared storage và replicated tự động. Nếu OCR hỏng, cluster không thể start.
3.7 SCAN & VIP
VIP (Virtual IP)
Mỗi node trong RAC có một VIP — địa chỉ IP ảo gắn với node đó. Khi node chết:
- VIP của node đó bị failover sang node khác trong vài giây
- Clients đang kết nối vào VIP đó nhận được TCP RST → reconnect sang node mới
VIP được quản lý bởi Oracle Clusterware, không cần load balancer bên ngoài.
SCAN (Single Client Access Name)
SCAN là địa chỉ DNS duy nhất cho toàn bộ cluster. Thay vì client phải biết IP của từng node, client chỉ cần kết nối vào SCAN.
Cơ chế:
DNS: rac-scan.company.com → [192.168.1.10, 192.168.1.11, 192.168.1.12]
(3 SCAN IPs cho cluster 3 nodes)
- Oracle khuyến nghị 3 SCAN IPs (có thể dùng 1 nhưng không khuyến nghị)
- SCAN Listener nhận connection → hỏi load balancing algorithm → redirect client sang node phù hợp
- Khi thêm/xoá node, không cần thay đổi SCAN address phía client
Connection Load Balancing
Oracle RAC hỗ trợ 2 kiểu load balancing:
| Kiểu | Cơ chế | Dùng khi |
|---|---|---|
| Client-side LB | Client tự random chọn node | Short connections, stateless |
| Server-side LB | SCAN Listener chọn node dựa trên load thực tế | Long connections, session-intensive |
4. Luồng Cache Fusion chi tiết
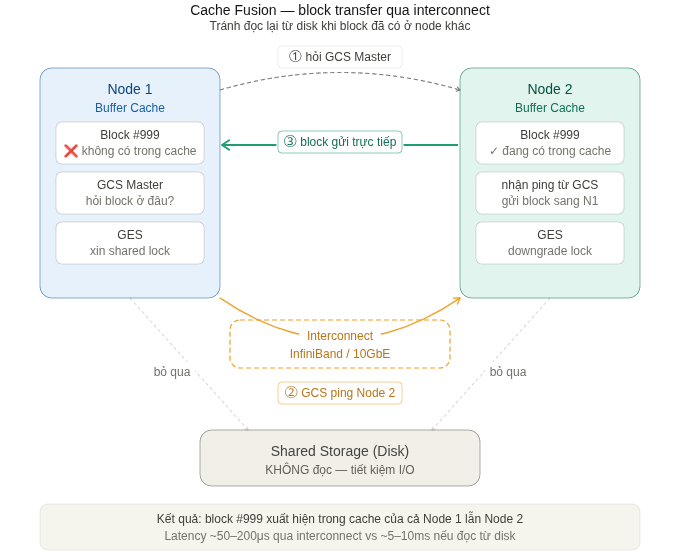
Kịch bản: Node 1 cần đọc Block #999, Node 2 đang giữ block đó
Bước 0 — Trạng thái ban đầu:
- Block #999 đang trong Buffer Cache của Node 2 (mode Shared)
- Node 1 cần đọc Block #999, không có trong cache của mình
Bước ① — Node 1 hỏi GCS Master:
Node 1 → GCS Master (giả sử đang trên Node 3):
"Tôi cần Block #999 để đọc (Shared mode)"
Bước ② — GCS Master ping Node 2:
GCS Master → Node 2:
"Node 1 cần Block #999. Hãy gửi block đó sang Node 1"
Bước ③ — Node 2 gửi block trực tiếp cho Node 1:
Node 2 → Node 1 (qua interconnect, KHÔNG qua disk):
[Block #999 data — ~8KB]
Đồng thời gửi ACK về GCS Master: "Đã gửi xong"
Bước ④ — GCS Master cập nhật directory:
GCS Master ghi nhận: Block #999 hiện đang ở cả Node 1 (Shared) và Node 2 (Shared)
Kết quả:
- Node 1 có Block #999 trong cache
- Không có I/O đến disk
- Latency: ~5–50μs (interconnect) thay vì ~5–10ms (disk read)
Kịch bản phức tạp: Write conflict
Node 1: UPDATE t SET val=100 WHERE id=1; -- cần Block #999 mode Exclusive
Node 2: đang giữ Block #999 mode Shared
- Node 1 request Block #999 Exclusive → GCS Master
- GCS Master gửi "Downgrade request" đến Node 2: "Trả lại Block #999"
- Node 2 ghi current image (sau khi apply redo) lên disk (nếu cần)
- Node 2 gửi block sang Node 1, downgrade mode của mình xuống Null
- Node 1 nhận block ở mode Exclusive → thực hiện UPDATE
5. Điểm mạnh của RAC
5.1 High Availability thực sự Active-Active
Khác với Data Guard hay Patroni chỉ có 1 node phục vụ tại một thời điểm, RAC cho phép tất cả nodes đều nhận request. Khi một node chết:
Kịch bản thực tế — Node 2 crash lúc 3 giờ sáng:
03:00:00 - Node 2 crash (kernel panic)
03:00:02 - Cluster phát hiện Node 2 không còn heartbeat
03:00:03 - Remaining nodes bắt đầu Instance Recovery cho Node 2
03:00:08 - Instance Recovery hoàn tất (apply redo log của Node 2)
03:00:08 - Clients đang connected vào Node 2 nhận TCP RST
03:00:09 - Clients reconnect vào Node 1 hoặc Node 3 (qua VIP/SCAN)
TAF (Transparent Application Failover) tự động retry query
03:00:10 - Hệ thống hoạt động bình thường, throughput giảm ~33%
Tổng downtime: ~10 giây — so với Active-Standby có thể mất 30–120 giây.
5.2 Rolling Upgrades — Zero Downtime Maintenance
Ví dụ: Upgrade Oracle 19c → 21c trên cluster 4 nodes:
Week 1: Tắt Node 4, upgrade, bật lại → cluster chạy 3 nodes (75% capacity)
Week 2: Tắt Node 3, upgrade, bật lại → cluster chạy 3 nodes
Week 3: Tắt Node 2, upgrade, bật lại → cluster chạy 3 nodes
Week 4: Tắt Node 1, upgrade, bật lại → cluster chạy 4 nodes (100% capacity)
Trong suốt quá trình này, không có downtime. Ứng dụng vẫn chạy bình thường, chỉ giảm capacity tạm thời.
Áp dụng tương tự cho: OS patch, firmware upgrade, hardware replacement.
5.3 Transparent Application Failover (TAF)
TAF cho phép Oracle client tự động retry một số loại operation khi node chết, mà ứng dụng không cần code thêm gì:
-- Connection string với TAF:
jdbc:oracle:thin:@(DESCRIPTION=
(FAILOVER=on)
(LOAD_BALANCE=on)
(ADDRESS=(PROTOCOL=TCP)(HOST=rac-scan)(PORT=1521))
(CONNECT_DATA=(SERVICE_NAME=mydb)
(FAILOVER_MODE=(TYPE=SELECT)(METHOD=BASIC)(RETRIES=180)(DELAY=5))))
TAF hỗ trợ:
- SELECT: Retry query từ đầu trên node mới
- SESSION: Tạo lại session trên node mới (nhưng transaction đang dở bị rollback)
TAF không hỗ trợ: DML đang trong transaction chưa commit — ứng dụng phải tự handle.
5.4 Horizontal Scalability (Scale-Out)
Thêm node mới vào cluster không cần restart hay reconfigure ứng dụng:
# Thêm Node 5 vào cluster đang chạy:
cluvfy comp peer -n node5 # Verify node đủ điều kiện
addNode.sh # Chạy trên node mới
srvctl add instance -db mydb -instance mydb5 -node node5
srvctl start instance -db mydb -instance mydb5
# → Cluster giờ có 5 nodes, SCAN tự động distribute load sang node mới
Thực tế tại một ngân hàng lớn: Trước Black Friday, họ thêm 4 nodes vào cluster hiện có 8 nodes. Sau Black Friday, remove 4 nodes đó. Không có downtime, không thay đổi code.
5.5 Resource Management với Services
RAC cho phép định nghĩa Services — nhóm các loại workload và pin chúng vào specific nodes:
-- Tạo service OLTP chỉ chạy trên Node1, Node2 (có failover sang Node3)
srvctl add service -db mydb -service oltp_svc
-preferred node1,node2 -available node3
-- Tạo service Reporting chỉ chạy trên Node3, Node4
srvctl add service -db mydb -service report_svc
-preferred node3,node4
Kết quả: OLTP và reporting không tranh giành CPU/RAM với nhau, và failover được kiểm soát có chủ đích.
6. Điểm yếu và rủi ro của RAC
6.1 "Hot Block" Contention — Kẻ thù số một của RAC
Đây là vấn đề nghiêm trọng nhất và thường gặp nhất trong RAC thực tế.
Cơ chế xảy ra:
Khi nhiều nodes cùng cập nhật các blocks nằm trong cùng một vùng nhỏ của database (ví dụ: sequence table, index root block, hot row), Cache Fusion phải liên tục chuyển block qua lại giữa các nodes:
Node1 cần Block #1 Exclusive → lấy từ Node2 → modify →
Node2 cần Block #1 Exclusive → lấy từ Node1 → modify →
Node3 cần Block #1 Exclusive → lấy từ Node2 → modify →
... vòng lặp vô tận ...
Hậu quả: Hệ thống 4 nodes có thể chậm hơn hệ thống 1 node vì overhead của Cache Fusion vượt qua lợi ích của parallel processing.
Dấu hiệu nhận biết (AWR/ASH):
Top Wait Events:
gc buffer busy acquire → Block đang được transfer, node khác phải chờ
gc cr request → Waiting for Consistent Read block từ remote node
gc current request → Waiting for current (dirty) block từ remote node
Ví dụ thực tế:
Một e-commerce site dùng SEQUENCE để generate order ID:
-- Mỗi node gọi NEXTVAL hàng nghìn lần/giây
INSERT INTO orders (id, ...) VALUES (order_seq.NEXTVAL, ...);
Sequence cache block bị tranh chấp liên tục giữa 4 nodes → throughput giảm 60% so với single node.
Giải pháp:
-- Tăng sequence cache size (mỗi node giữ 1000 giá trị, ít transfer hơn)
ALTER SEQUENCE order_seq CACHE 1000;
-- Hoặc dùng NOORDER (không cần global order)
ALTER SEQUENCE order_seq CACHE 1000 NOORDER;
6.2 Chi phí License — Gánh nặng tài chính
Oracle RAC license theo số CPU cores, không theo nodes hay RAM:
Ví dụ cluster 4 nodes × 32 cores/node = 128 cores:
Oracle Enterprise Edition: 128 × $47,500 = $6,080,000
RAC Option (bắt buộc): 128 × $23,000 = $2,944,000
Annual Support (22%/năm): ~$1,984,000/năm
─────────────────────────────────────────────────────
Tổng năm đầu: $11,008,000
Chi phí 5 năm: ~$19,000,000+
So sánh: Một Aurora cluster tương đương (db.r6g.16xlarge × 4) tốn khoảng $180,000/năm — rẻ hơn 100 lần.
Đây là lý do nhiều tổ chức đang trong quá trình "Oracle migration" sang PostgreSQL, Aurora, hoặc Spanner.
6.3 Shared Storage là Single Point of Failure tiềm tàng
Dù các nodes redundant, nếu shared storage gặp sự cố → toàn bộ cluster down. Đây là điểm yếu cố hữu của shared-disk architecture.
Kịch bản rủi ro:
- SAN controller firmware bug → I/O hang
- Storage network (Fibre Channel switch) lỗi
- ASM disk group mount fail sau reboot
Giải pháp: Redundant storage path (multi-path I/O), redundant FC switches, ASM High Redundancy (3-way mirroring).
6.4 Độ phức tạp vận hành cao
RAC đòi hỏi đội ngũ có chuyên môn cao để vận hành:
| Kỹ năng cần thiết | Lý do |
|---|---|
| Oracle Clusterware | Troubleshoot cluster events, node eviction |
| ASM administration | Disk group management, rebalancing |
| Network/Storage | Interconnect tuning, SAN zoning |
| RAC performance tuning | Identify và giải quyết contention |
| Oracle Diagnostics | AWR, ASH, ADDM, cluster trace files |
Hậu quả thực tế: Một DBA Oracle không có kinh nghiệm RAC có thể cấu hình sai interconnect → toàn bộ lợi ích của RAC biến mất, thậm chí chậm hơn single node.
6.5 RAC không phải giải pháp cho mọi vấn đề scale
Một quan niệm sai lầm phổ biến: "Thêm node vào RAC = tăng tuyến tính performance."
Thực tế (Amdahl's Law áp dụng):
| Loại workload | Scale-out hiệu quả? | Lý do |
|---|---|---|
| Read-heavy (reporting, analytics) | ✅ Tốt | Mỗi node đọc từ disk độc lập, ít Cache Fusion |
| OLTP với random writes | ⚠️ Trung bình | Phụ thuộc mức độ "hotness" của blocks |
| Write-heavy vào cùng tables | ❌ Kém | Hot block contention nghiêm trọng |
| Full table scans lớn | ❌ Kém | Parallel query có thể giúp nhưng storage là bottleneck |
7. Ví dụ triển khai thực tế tại Big Tech
7.1 Hệ thống ngân hàng: JP Morgan Chase style
Một core banking system điển hình:
Cluster cấu hình:
8 nodes × 64 cores (Exadata X8M)
2TB RAM mỗi node
Shared storage: Exadata Smart Flash Cache
Interconnect: InfiniBand HDR (200 Gbps)
Workload phân chia theo Service:
├── core_banking_svc → Node 1,2,3,4 (preferred)
│ - Account balance queries
│ - Fund transfers
│ - Transaction posting
├── fraud_detect_svc → Node 5,6 (preferred)
│ - Real-time fraud scoring
│ - Machine learning inference
└── report_svc → Node 7,8 (preferred)
- Regulatory reports
- End-of-day batch
Kết quả:
- 99.999% availability (< 5 phút downtime/năm)
- ~180,000 TPS peak (Black Friday / year-end closing)
- Rolling upgrade không downtime
7.2 Telco: Subscriber Management
Hệ thống quản lý 100 triệu thuê bao:
Vấn đề: Mỗi cuộc gọi/SMS cần lookup subscriber record
→ Cùng vài triệu "hot" subscriber records bị đọc liên tục
Giải pháp RAC:
- Application routing: subscriber ID % 4 → node ID
- Mỗi node chủ yếu xử lý 25% subscribers
- Hot blocks của Node 1 ít khi cần sang Node 2,3,4
- Cache Fusion overhead giảm đáng kể
Kết quả: 4-node RAC gần đạt hiệu quả tuyến tính (3.7× single node)
7.3 E-Commerce: Black Friday Scaling
Bình thường: 2 nodes (đủ cho baseline traffic)
Black Friday: Thêm 6 nodes vào cluster (scale-out trong vài giờ)
→ 8 nodes tổng, handle 10× traffic bình thường
Sau Black Friday: Remove 6 nodes
→ Tiết kiệm license cost (pay per use với cloud RAC)
Vấn đề gặp phải: Order sequence hot block
Giải pháp: SEQUENCE CACHE 10000 NOORDER + application-level ID generation (UUID)
8. So sánh RAC với các giải pháp hiện đại
| Hệ thống | Mô hình | Shared Storage | Scale-out | Consistency | Chi phí | Phù hợp cho |
|---|---|---|---|---|---|---|
| Oracle RAC | Shared-disk cluster | ASM/SAN | ~128 nodes | Strong ACID | Rất cao | Banks, Telco, Gov với Oracle |
| Google Spanner | Distributed NewSQL | Colossus (GFS) | Không giới hạn | External Consistency (TrueTime) | Cao (cloud) | Global applications |
| Amazon Aurora | Shared-storage cluster | Aurora Storage | 1 writer + 15 readers | Strong (writer) | Trung bình | AWS-native applications |
| CockroachDB | Distributed shared-nothing | Không (local SSD) | Không giới hạn | Serializable | Thấp–Trung bình | Cloud-native, global |
| Vitess/MySQL | Sharding middleware | Không (sharded) | Không giới hạn | Per-shard strong | Thấp | High-volume OLTP |
| PostgreSQL + Patroni | Active-standby HA | Không | 1 primary, n replicas | Strong (primary) | Rất thấp | General purpose |
Tại sao Big Tech hiện đại không dùng RAC?
- Lock-in: RAC chỉ chạy trên Oracle — không thể migrate sang cloud-native dễ dàng
- Cost: License Oracle đắt hơn 10–100× so với open-source alternatives
- Scale model: RAC scale đến ~10–20 nodes hiệu quả; Google/Amazon cần hàng nghìn nodes
- Cloud-native: Kubernetes, containerization, microservices → shared-nothing fits better
- Operational complexity: 1 Spanner cluster tự quản lý hoàn toàn; RAC cần team chuyên biệt
9. Khi nào nên và không nên dùng RAC?
Nên dùng RAC khi:
- Đã có Oracle database ecosystem sâu rộng (PL/SQL, Oracle Forms, Apex...)
- Cần zero planned downtime (rolling upgrade là ưu tiên hàng đầu)
- Workload chủ yếu là OLTP với read-heavy và writes phân tán đều
- Budget cho phép và có đội DBA Oracle giàu kinh nghiệm
- Regulatory requirement yêu cầu Oracle (một số ngân hàng, chính phủ)
- Dùng Oracle Exadata (RAC + Exadata = combination mạnh nhất của Oracle ecosystem)
Không nên dùng RAC khi:
- Ứng dụng mới xây dựng từ đầu → chọn cloud-native ngay từ đầu
- Workload chủ yếu write-heavy vào cùng một set records → hot block contention
- Budget hạn chế → PostgreSQL + Patroni + PgBouncer đủ dùng cho 99% use cases
- Cần scale đến hàng trăm nodes → shared-disk không phải kiến trúc phù hợp
- Team không có Oracle DBA kinh nghiệm → operational risk quá cao
10. Tài liệu tham khảo
- Oracle RAC Administration Guide 21c
- Oracle Clusterware Administration and Deployment Guide
- Oracle ASM Administrator's Guide
- Expert Oracle RAC 12c — Riyaj Shamsudeen, Syed Jaffar Hussain, Kai Yu, Tariq Farooq (Apress)
- Oracle RAC Performance Tuning — Murali Vallath (Digital Press)
- Oracle MOS Note: RAC Cache Fusion Internals (Doc ID 258445.1)
- Google Spanner: Globally-Distributed Databases — OSDI 2012
Cập nhật lần cuối: 2026
Phiên bản Oracle tham chiếu: Oracle Database 21c / 23ai
Tác giả ghi chú: Tài liệu này tổng hợp từ Oracle official docs, production experience, và so sánh với các giải pháp hiện đại tính đến 2026.
All rights reserved
