Optimizing Schema and Data Types
Bài đăng này đã không được cập nhật trong 6 năm

Lời mở đầu
Trong phần đầu của bài viết MySQL Architecture and History, mình đã giới thiệu những khái niệm cơ bản nhất cũng như "nội thất" trong ngôi nhà MySQL của chúng ta. Sau khi nắm được những nội thất bên trong của ngôi nhà, chúng ta sẽ sử dụng chúng một cách hiệu quả nhất có thể. Ở bài viết này, mình sẽ giới thiệu 2 phương pháp đầu tiên để tối ưu MySQL. Đó là tối ưu schema, và tối ưu kiểu dữ liệu. Không phải lúc nào chúng ta cũng cần theo nhưng quy tắc được học ở trên trường. Đôi lúc dư thừa dữ liệu giúp tăng hiệu năng của hệ thống 1 cách đáng kể. No sliver bullet - đó là bản chất của Software Engineering.
Lựa chọn kiểu dữ liệu phù hợp
Như chúng ta đã biết, "ngôi nhà" MySQL có 1 "phòng bếp" đó là kiểu dữ liệu. Phòng bếp đó có rất nhiều các loại gia vị khác nhau. Lựa chọn loại gia vị phù hợp mới chế được ra những món ăn ngon nhất có thể. Các quy tắc chọn loại kiểu dữ liệu phù hợp:
Nhỏ gọn thường tốt hơn
Đây cũng là quy tắc khá dễ hiểu, vì kiễu dữ liệu nhỏ hơn sử dụng ít bộ nhớ hơn ở đĩa, bộ nhớ đệm, bộ nhớ trong. Chúng cũng yêu cầu ít chu trình CPU hơn để xử lí. Không dại gì chúng ta sử dụng BIGINT để lưu các trường như age trong bảng persons cả. Trừ khi chúng ta có 1 bản ghi là Tôn Ngộ Không.

Đơn giản là tốt
Sử dụng các kiểu dữ liệu đơn giản sẽ giúp chúng ta giảm số lượng các thao tác xử lí để ra được kết quả mong muốn. Ví dụ: Bạn nên lưu ngày tháng trong MySQL bằng kiểu dữ liệu DATETIME thay vì kiểu text. Hiểu đơn giản bởi vì string là một mảng của các kí tự. Việc quy tắc so sánh làm cho việc so sánh ngày tháng được lưu bởi string trở nên phức tạp.
Nếu có thể, đừng dùng NULL

NULL khiển cho các câu truy vấn trở nên khó để tối ưu. Bởi vì NULL khiến việc đánh index, thống kê index, so sánh giá trị trở nên rất phức tạp. Tuy NULL khó chịu là vậy, nhưng việc cải thiện hiệu năng của hệ thống ở việc chuyển từ cột NULL sang cột NOT NULL là không nhiều nên chúng ta cần cân nhắc việc ưu tiên tìm và thay đổi trên các bảng đã tồn tại. Trừ khi bạn thấy NULL đang gây ra những vấn đề.
Như vậy, từ các điểm đã lưu ý ở trên chúng ta sẽ có 1 flow để chọn kiểu dữ liệu phù hợp.
- Đầu tiên, chúng ta phải xem lớp chung của cột chúng ta đang xét đến là gì: numeric, string, hay datetime, ....
- Tiếp theo, lựa chọn kiểu dữ liệu riêng. Ví dụ DATETIME và TIMESTAMP có thể lưu cùng loại dữ liệu: ngày và thời gian, chính xác tới từng giây. TIMESTAMP sử dụng bộ nhớ chỉ bằng 1/2 so với DATETIME. Tuy nhiên khoảng giá trị cho phép của TIMESTAMP lại ít hơn và khả năng của nó mang lại cũng ít hơn.
Trong phần tiếp theo của bài viết này, mình sẽ giới thiệu về các kiểu dữ liệu cơ bản trong MySQL.
Whole number
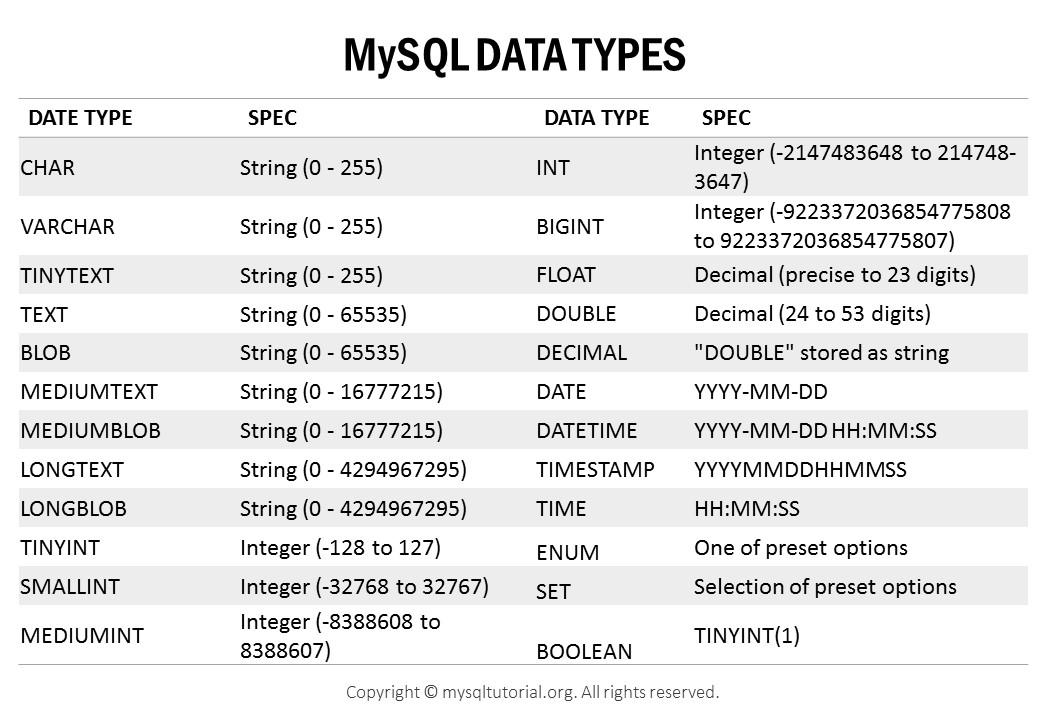
Trong MySQL, có 2 kiểu dữ liệu số là whole number(số nguyên) và real number(số thực). Kiểu dữ liệu số nguyên bao gồm TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT. Đây là bảng tóm tắt sơ lược về các kiểu dữ liệu này.

Chúng ta có thể sử dụng thuộc tính UNSIGNED để không cho phép các giá trị âm và cũng để tăng giá trị giới hạn trên. Ví dụ, với kiểu dữ liệu INT thì khoảng giá trị cho phép là [ -2147483648, 2147483647 ]. Nếu sử dụng UNSIGNED ta có khoảng giá trị cho phép mới là [0, 4294967295]. Thật thú vị phải không ? MySQL cho phép bạn chỉ ra "width" cho kiểu dữ liệu số. Ví dụ INT(11). Tuy nhiên điều này có vẻ khá vô nghĩa khi, việc lưu như vậy cũng không giới hạn khoảng giá trị cho phép của INT.
Về mặt bộ nhớ và khả năng tính toán, INT(11) và INT(1) là giống nhau.
Real number
Số thực là kiểu dữ liệu chúng ta tiếp cận từ từ khi còn học phổ thông. Đó là kiểu dữ liệu có phần thập phân. Tuy vậy chúng ta có thể dùng DECIMAL để lưu các giá trị lớn mà BIGINT cũng không đủ để lưu trữ. Có thể là giá trị tài sản của Bill Gates khi quy ra VND chẳng hạn.
FLOAT và DOUBLE hỗ trợ tính toán xấp xỉ kiểu gần đúng theo chuẩn floating-point. Từ phiên bản MySQL 5.0 DECIMAL hỗ trợ việc tính toán chính xác. Do real number chủ yếu xoay quanh vấn đề về floating point, nên mình sẽ không đề cập trong bài viết này. Các bạn có thể tham khảo các tài liệu về floating-point trên mạng để hiểu vì sao ở 1 số ngôn ngữ 0.1+ 0.2 == 0.3 là false nhé. Mình sẽ chỉ rút ra một vài lưu ý nhỏ như sau:
- Chúng ta cần kiểu DECIMAL khi cần những phép tính chính xác. Những phép tính mà sai số có thể bỏ qua thì nên dùng 2 kiểu dữ liệu còn lại vì DECIMAL cần nhiều không gian và chi phí để tính toán hơn so với FLOAT và DOUBLE
- Chúng ta có thể sử dụng BIGINT để thay thế DECIMAL trong 1 số trường hợp. Ví dụ thay vì lưu 1/10000 1 cent của Mỹ (1 dollar = 100 cent). Ta có thể nhân các giá trị trong bảng với 10^6 để lưu các giá trị này dưới dạng BIGINT, để tiết kiệm không gian và chi phí tính toán.
String
VARCHAR và CHAR
Varchar Varchar lưu string dưới dạng độ dài tùy biến. Nó có thể sử dụng ít bộ nhớ hơn string độ dài cố định. Vì nó sẽ chỉ sử dụng bộ nhớ theo độ dài của string. Varchar sử dung 1 hoặc 2 bytes cho việc lưu trữ độ dài. 1 bytes nếu độ dài của string <= 255, 2 bytes nếu lến hơn. Ví dụ:
- VARCHAR(10) sẽ dùng 11 bytes đễ lưu trữ
- VARCHAR(1000) sẽ dùng 1002 bytes đễ lưu trữ
Char Char là kiểu string độ dài cố định. Char hữu dụng khi lưu trữ dữ liệu ngắn và các giá trị của cột gần như là là giống nhau. Vì Char k cần thêm byte đễ lưu trữ độ dài.
Blog và Text
Blog và text là 2 kiểu dữ liệu để lưu 1 lượng lớn dữ liệu cũng như các chuỗi nhị phân, kí tự,... Không giống các kiểu dữ liệu khác, MySQL xử lí BLOB và TEXT như 1 đối tượng với định danh của chúng. BLOB lưu trữ dữ liệu nhị phân mà không có collation, hoặc tập kí tự. TEXT có tập kí tự và collation riêng. (Ở đây từ collation, mình không tìm được từ nào sát nghĩa nên mình để nguyên để tiện cho việc tra cứu của các bạn)
Lưu ý: MySQL sẽ không đánh index toàn bộ độ dài của các kiễu dữ liệu này, và không thể sử dụng index cho việc sắp xếp.
Date và Time
MySQL có nhiều kiểu dữ liệu date và time. Ví dụ YEAR, DATE, ...
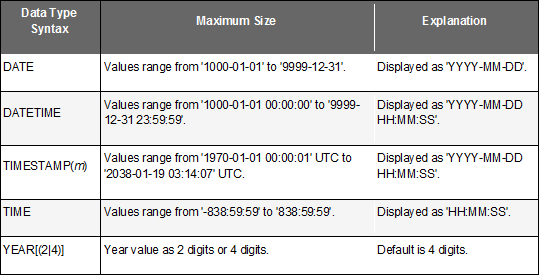
MySQL có 2 kiểu dữ liệu đảm bảo sự chính xác đến từng giây đó là DATETIME, và TIMESTAMP. TIMESTAMP sử dụng 4 bytes để lưu trữ dữ liệu so với 8 bytes của DATETIME nên TIMESTAMP có khoảng gía trị ít hơn. Bạn nên lưu ý, nếu ứng dụng có bạn được kết nối từ các Time zone khác nhau. Với TIMESTAMP, giá trị được lưu sẽ tương quan với Time zone hiện tại, còn với DATETIME, sẽ không có gì thay đổi, vì giá trị DATETIME được lưu được coi như 1 đoạn text đại diện cho ngày tháng và thời gian
Trên đây là những kiểu dữ liệu cơ bản trong MySQL, bạn có thể tìm hiểu thêm những kiểu dữ liệu khác như BIT, SET, ...
Thiết kế schema phù hiệu quả
Sau khi lưu chọn được kiểu dữ liệu phù hợp cho các cột, chúng ta cần thiêt kế schema hiệu quả để đạt kết quả tối ưu sau này. Những vấn đề thiết kế sau đây sẽ khiến cho hiệu năng DB của bạn giảm xuống:
Quá nhiều cột
Điều này là dễ hiểu vì truy vấn bảng nhiều cột sẽ tốn thời gian các bảng có ít cột hơn.
Quá nhiều joins
Quá nhiều phép joins khi để lấy ra dữ liệu cũng làm giảm tốc độ của câu truy vấn
Cột chấp nhận giá trị Null
Trong phần đầu của bài biết, mình đã nói về những lợi ích đạt được khi không chấp nhận lưu trí Null
Từ những vấn đề trên, phần nào chúng ta sẽ có cách để tránh giúp thiết kế DB hiệu quả hơn. Nhưng không chỉ có vậy chúng ta cần normalize hoặc denormalize schema để hiệu năng DB có thể được nâng lên.
Normalization và Denormalization
Normalization là 1 khái niệm rất hay trong DB giúp tránh việc dư thừa dữ liệu, giúp cấu trúc bảng trở nên tối ưu hơn. Có nhiều tiêu chuẩn của normalization như 1NF, 2NF, 3NF, Boyce Code NF (3.5 NF), 4NF,... Bạn có thể tìm hiểu thêm về normalization ở đây
Chúng ta sẽ bắt đầu với ví dụ đơn giản để hiểu qua 1 chút về normalization sau:
| EMPLOYEE | DEPARTMENT | HEAD |
|---|---|---|
| Jones | Accounting | Jones |
| Smith | Engineering | Smith |
| Brown | Accounting | Jones |
| Green | Engineering | Smith |
Vấn đề dễ nhận ra ở bảng này đó là việc dữ liệu có thể không thống nhất khi được update. Ví dụ bây giờ Brown đảm nhiệm vị trí trưởng phòng kế toán, chúng ta cần update lại nhiều dòng trên bảng này. Để giải quyết vấn đề này. chúng ta cần chia bảng gốc thành 2 bảng là bảng employees và bảng departments như sau:
| EMPLOYEE | DEPARTMENT |
|---|---|
| Jones | Accounting |
| Smith | Engineering |
| Brown | Accounting |
| Green | Engineering |
| DEPARTMENT | HEAD |
|---|---|
| Accounting | Jones |
| Engineering | Smith |
Những bảng của chúng ta đã ở chuẩn loại 2, và giúp cho việc thay đổi dữ liệu tốn ít chi phí hơn.

Lợi ích và hạn chế của schema được normalize
Lợi ích:
- Việc update dữ liệu sau khi đã normalize thường nhanh hơn trước khi normalize như bạn có thể thấy qua ví dụ ở trên
- Các bảng được normalized thường nhỏ hơn, do đó chúng cần ít bộ nhớ hơn
- Bảng được normalize giúp tránh việc dư thừa dữ liệu, dẫn đến việc chúng ta không cần đến DISTINCT, GROUP BY trong các câu truy vấn
Bên cạnh nhưng lợi ích mà normalize mang lại, nó cũng tồn tại những hạn chế. Như chúng ta có thể thấy việc chia từ 1 bảng -> 2 bảng như ở trên dẫn đến việc nhiều câu truy vấn cần các phép joins. Phép joins là một hành động rất tốn chi phí, và có thể dẫn đến việc chúng ta không thể tận dụng được index trong các câu truy vấn này.
Lợi ích và hạn chế của schema không normalize
Schema không normalize giúp tránh việc joins nhiều bảng để đạt được kết quả mong muốn khi truy vấn. Chúng ta có thể sử dụng được index vì chúng ta không cần joins các bảng. Việc dồn dữ liệu vào 1 bảng giúp chúng ta có thể lựa chọn kiểu index phù hợp để việc truy vấn nhanh hơn. Ví dụ, bạn có 1 website cho phép người dùng đăng tin của họ, 1 vài người dùng là thành viên "premium" . Nếu bạn sử dụng normalize, khi muốn truy vấn ra 10 tin gần nhất từ các thành viên premium, câu truy vấn sẽ trông như thế này:
SELECT message_text, user_name
FROM message
INNER JOIN user ON message.user_id=user.id
WHERE user.account_type='premium'
ORDER BY message.published DESC LIMIT 10;
Để thực thi câu truy vấn này, MySQL cần scan published index trong bảng message. Cho mỗi bản ghi tìm được, chúng ta lại phải vào bảng user để check xem đó có phải thành viên premium không. Đây là phương án truy vấn không hiệu quả khi chỉ có 1 lượng nhỏ users là premium. Với 1 schema denormalize, chúng ta có câu truy vấn sau:
SELECT message_text,user_name
FROM user_messages
WHERE account_type='premium'
ORDER BY published DESC
LIMIT 10;
Câu truy vấn hiệu quả hơn vì tránh được phép join và tận dụng được index published
Kết hợp normalize, denormalize
Trong thực tế hiếm khi, chúng ta bắt gặp schema chỉ theo normalize, denormalize. Chúng ta thường kết hợp cả 2 để mang lại hiệu quả cao nhất. Cách phổ biến để denormalize dữ liệu là tạo bản sao, cache các cột từ bảng này sang bảng khác. Từ phiên bản MySQL 5.0, bạn có thể sử dụng trigger để update lại dữ liệu được cache.
Bên cạnh normalize, denomalize, chúng ta vẫn còn các kĩ thuật khác để nâng cao hiệu năng DB. Tiếp tục nào !!!
Bảng cache và bảng summary
Đôi khi, việc dư thừa dữ liệu lại giúp cải thiện đáng kể hiệu năng của hệ thống. Nhưng đôi khi, chúng ta cần xây dựng các bảng riêng biệt cho mục đích cache và summary.
Summary table thường có tác dụng trong việc truy vấn kết quả nhanh hơn từ các phép GROUP BY. Ví dụ bạn cần đếm số lượng tatas cả các tin được đăng lên webiste trong vòng 24h gần đây. Bạn có thể sử dụng 1 bảng summary table để đếm số lượng sau mỗi giờ thay vì phải truy vấn cả bảng messages.
Cache table thường dùng để tối ưu các câu truy vấn tìm kiếm.
Ví dụ bạn cần các kiểu index khác nhau cho dữ liệu 1 bảng. Nhưng do MySQL không hỡ trợ 1 bảng có 2 storage engine khác nhau, nên ta có thể dùng 1 cache table. Ở bảng gốc nếu storage engine là InnoDB thì trong bảng cache( chứa 1 số cột từ bảng gốc) ta có thể sử dụng MyISAM engine. Như vậy chúng ta sẽ có thể truy vấn = index của cả 2 storage engine này hỗ trợ. Quả là hữu dụng phải không nào.

Khi sử dụng bảng summary và bảng cache, chúng ta cần quyết định xem việc update các bảng này sẽ theo thời gian thực hay theo giai đoạn. Thông thương, việc update theo giai đoạn sẽ giúp tiết kiệm tài nguyên vì có thể chúng ta chỉ cần mỗi tiếng update 1 lần. Make your choice tùy thuộc vào yêu cầu ứng dụng của bạn. Sau đây mình sẽ chỉ ra vài ứng dụng của thể của summary table và cache table.
Materialized Views
Nhiều hệ thống quản trị cơ sở dữ liệu như SQL Server, Oracle đều có 1 tính năng đó là materialized views. Tính năng này giống với summary table mình vừa chỉ ra. MySQL chưa hỗ trợ tính năng này, nhưng bạn có thể sử dụng công cụ mã nguồn mở để tự build cho mình
Counter tables
Ví dụ 1 ngôi trường cần đếm số lượng học sinh trong trường. Thay vì phải đếm lại mỗi lần được query, chúng ta có thể sử dụng 1 biến counter để đếm. Biến đêm này sẽ thay đổi mỗi khi 1 bản ghị học sinh được thêm hoặc xóa. . Vì biến đếm là 1 chi phí thêm mỗi khi bạn thêm hoặc xóa bản ghi. Nên ta thường áp dụng kĩ thuật này cho các bảng có ít sự thay đổi, mà bị truy vấn nhiều
Lời kết
Như vậy, trong bài viết này mình đã trình bày 1 số kĩ thuật cơ bản để tối ưu hiệu năng bằng phương pháp tối ưu kiểu dữ liệu và tối ưu schema. Trong các phần tiếp theo của series này, mình sẽ trình bày các kĩ thuật tối ưu khác để hiệu năng DB đạt hiệu quả nhất có thể.
Rât mong sự ủng hộ và góp ý của các bạn.
Happy coding.

Tham Khảo
https://www.percona.com/blog/2015/01/20/identifying-useful-information-mysql-row-based-binary-logs/
https://viblo.asia/p/mysql-architecture-and-history-RQqKLkd057z
http://shop.oreilly.com/product/0636920022343.do
https://www.quora.com/What-is-normalized-vs-denormalized-data
All rights reserved
