[NVIDIA Tools] Bài 8: Occupancy Phần 1
Ở bài 7 mình đã đề cập đến vấn đề: làm sao để chọn ra số thread phù hợp thì ở bài viết này mình sẽ chia sẽ 1 cách khá phổ biến để xác định - ở đây sẽ có nhiều bạn thắc mắc là tại sao chúng ta không đơn giản hóa vấn đề - chỉ cần chạy nhiều trường hợp của threads là sẽ xác định được số threads phù hợp thì chỉ đúng khi đoạn code của bạn đơn giản vì nếu phức tạp thì mỗi lần chạy sẽ rất lâu nên việc chạy nhiều trường hợp để chọn threads phù hợp sẽ không phải lựa chọn hay
Occupancy
Trước khi đi vào bài viết thì mình sẽ lấy ví dụ để các bạn hình dung occupancy là gì và công dụng nó như thế nào
Ví dụ: chúng ta có 6 nhân công và 6 công việc thì cách đơn giản nhất để chia công việc là mỗi nhân công làm 1 công việc NHƯNG mỗi nhân công có khả năng thực hiện 3 công việc cùng lúc thì lúc này chúng ta chỉ cần 2 nhân công cho 6 công việc ==> thuê ít nhân công ==> tốn ít tiền hơn và số lượng công việc luôn nhiều hơn số nhân công nên việc tối ưu nhân công cho công việc là cần thiết
Thì ở đây nhân công là threads và công việc là data và câu hỏi đặt ra là làm sao chúng ta xác định được mỗi nhân công có thể thực hiện bao nhiêu công việc ( 1 thread có thể xử lí bao nhiêu data) thì lúc này NVIDIA tạo ra Occupancy để xác định điều đó
Occupancy dùng để xác định số thread tối ưu được dùng trong kernel nhằm đạt hiệu suất cao nhất.
Code
Với N = 1000000
__global__ void square(int *array, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N)
{
array[idx] *= array[idx];
}
}
Như bình thường thì các bạn sẽ sử dụng là
blockSize = 1024;
gridSize = (N + blockSize - 1) / blockSize;
Nhưng liệu con số 1024 đã tối ưu hay chưa thì chúng ta sẽ profile để xem thử occupancy
ncu --metrics sm__warps_active.avg.pct_of_peak_sustained_active ./a.out

Có thể thấy dùng 1024 threads là phí tài nguyên ( vì đã dùng max thread trong 1 block nhưng Occupancy là 53.73% ) ==> chứng tỏ 1 thread có thể thực hiện nhiều hơn 1 công việc
NVIDIA đã tạo ra 1 function dùng để xác định Occupancy phù hợp
template<class T>
__inline__ __host__ CUDART_DEVICE cudaError_t cudaOccupancyMaxPotentialBlockSize(
int *minGridSize,
int *blockSize,
T func,
size_t dynamicSMemSize = 0,
int blockSizeLimit = 0)
{
return cudaOccupancyMaxPotentialBlockSizeVariableSMem(minGridSize, blockSize, func, __cudaOccupancyB2DHelper(dynamicSMemSize), blockSizeLimit);
}
minGridSize = Suggested min grid size to achieve a full machine launch.
blockSize = Suggested block size to achieve maximum occupancy.
func = Kernel function.
dynamicSMemSize = Size of dynamically allocated shared memory. Of course, it is known at runtime before any kernel launch. The size of the statically allocated shared memory is not needed as it is inferred by the properties of func.
blockSizeLimit = Maximum size for each block. In the case of 1D kernels, it can coincide with the number of input elements.
Và đây là kết quả khi dùng Occupancy để xác định số threads

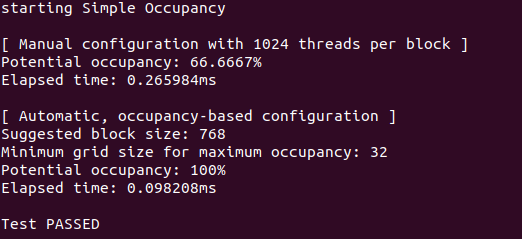
1 lưu ý nhỏ là mỗi máy tính có cấu hình khác nhau nên dẫn tới số thread để đạt 100% occupancy sẽ khác nhau
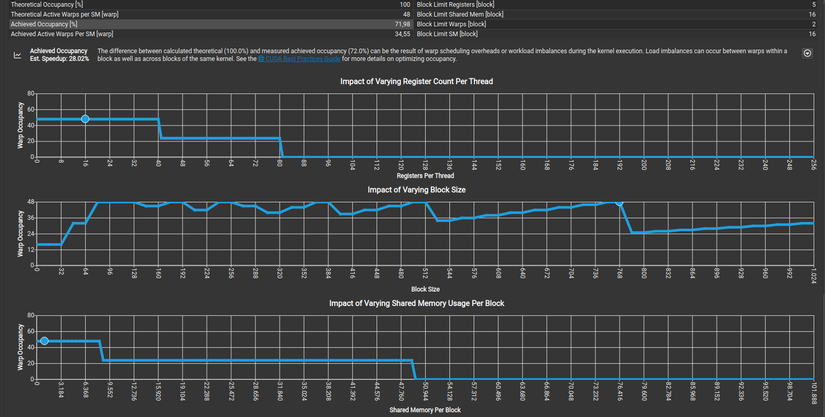
Ở đây các bạn sẽ thắc mắc là tại sao 2 cái occupancy lại khác nhau: 1 cái thì 74,89% 1 cái thì 100% mặc dù chung 1 code
Ở đây sẽ có khái niệm mới gọi là Theoretical occupancy - Achieved occupancy: có thể hiểu đơn giản là lý thuyết để đạt được - thực tế khi code chạy
Lý do tại sao Theoretical occupancy và Achieved occupancy lại ra kết quả khác nhau là vì khi code chạy thì thread sẽ còn bị ảnh hưởng bởi nhiều thứ khác nên mới vậy
==> Chúng ta chỉ chú trọng vào Achieved occupancy chứ đừng nên quá quan tâm vào Theoretical occupancy
Ví dụ:
- Theoretical 100% và Achieved 50%
- Theoretical 80% và Achieved 70%
Thì ta sẽ chọn trường hợp 2 nha
Ở những bài sau mình sẽ hướng dẫn những phương pháp giúp tăng Achieved occupancy
code mình sẽ để ở đây
All rights reserved
