NpOn.Net-V2 Core: Kiến trúc Microservices, tích hợp Data Access tốc độ cao
NpOn.Net-V2 Core: Kiến trúc Data Access trong môi trường Microservices
Tài liệu này trình bày các giải pháp kiến trúc về tầng Data Access Layer (DAL) được phát triển riêng trong hệ sinh thái NpOn.Net-V2. Quá trình hình thành thư viện lõi này bắt nguồn từ mục tiêu tách biệt hoàn toàn Business Logic khỏi các giới hạn của một Database cụ thể, quản lý chặt chẽ Connection Pool, và thiết lập một bộ quy chuẩn cấu trúc dữ liệu minh bạch, phù hợp với kiến trúc phân tán.
1. Microservices vs. Monolith: Cân nhắc đánh đổi thực tế
Xét thuần túy về tốc độ thực thi (Raw Execution Speed), một hệ thống Monolith tối ưu tốt thường sẽ có lợi thế hơn Microservices do không phải gánh chịu độ trễ mạng (Network Latency) hay chi phí tuần tự hóa (Serialization). Việc debug lỗi xuyên suốt nhiều dịch vụ (Distributed Tracing) cũng đem lại rào cản nhất định.
Tuy nhiên, NpOn.Net-V2 áp dụng Microservices vì tính độc lập, sự ổn định cô lập (Fault Isolation) và khả năng mở rộng từng phần. Kiến trúc này cho phép chia nhỏ các miền nghiệp vụ (Domain), giúp bảo vệ tổng thể hệ thống ngay cả khi một tiến trình con gặp sự cố, đồng thời dễ dàng triển khai bảo trì mã nguồn mà không sợ ảnh hưởng chéo.
2. Quản lý truy vấn tập trung (Định hướng Domain-Driven Design)
Việc gắn chặt Logic hệ thống vào các Stored Procedure cố định hoặc đặt các truy vấn SQL rải rác trong mã nguồn sẽ gây khó khăn lớn khi hệ thống mở rộng. Hệ thống giải quyết bài toán này thông qua một bản vẽ cấu hình (Blueprint):
- Tách biệt mức thực thi: Các luồng truy vấn xử lý được quản lý tập trung và lưu trữ tại
GeneralService, trong khi các Database thành phần (nhưAccountService) chủ yếu đóng vai trò nắm giữ tài nguyên cấu trúc cơ bản (Schema). - Tính linh hoạt trong cơ sở hạ tầng: Khi có nhu cầu đổi hệ Engine cơ sở dữ liệu, kỹ sư chỉ việc tùy chỉnh cụm từ khoá truy vấn tại khối cấu hình trung tâm (Mapping Dictionary) mà không cần can thiệp hay biên dịch lại (recompile) mã C#. Điều này tuân thủ trọn vẹn lý thuyết của Domain-Driven Design (DDD).
- Tối ưu quy trình bảo trì: Nhờ thiết kế tách biệt, thao tác sao lưu (Dump) hoặc khôi phục hệ thống được rút gọn xuống việc kết xuất các Mapping Table tại DB trung tâm và các Schema của DB con, tiết kiệm đáng kể nguồn lực.
3. Điều phối truy cập và Quản lý Pool kết nối (Connection Throttling)
Để ngăn ngừa tình trạng quá tải Database, hệ thống không cho phép các Instances triệu gọi kết nối dữ liệu tự do. Thay vào đó, mọi yêu cầu giao tiếp đều được phân luồng tự động qua DbFactoryWrapper.
Ràng buộc tài nguyên bằng Semaphore
Cơ chế Factory.GetConnectionAsync() được giám sát bằng một cấu trúc SemaphoreSlim:
- Tránh bùng nổ kết nối (Connection Escalation): Bằng cách giới hạn triệt để số luồng kết nối đồng thời, cấu trúc này bảo toàn thể lực của Database khi hệ thống chịu các luồng truy cập tăng vọt (Traffic Spikes/DDoS). Các request vượt ngưỡng sẽ ngoan ngoãn chờ ở hàng đợi bất đồng bộ thay vì làm gián đoạn tài nguyên CPU.
- Giải phóng tài nguyên tuyệt đối (Resource Liberation): Sau mỗi tiến trình truy vấn, cấu trúc lõi luôn áp chế một lệnh trả kết nối (
ReleaseConnection). Việc này đảm bảo tài nguyên được thu hồi và đưa về Pool một cách an toàn bất chấp kết quả gọi dữ liệu thành công hay phát sinh lỗi hệ thống, loại bỏ hoàn toàn các lỗi rò rỉ bộ nhớ (Memory/Connection Leak).
4. Tối ưu phân bổ thông qua IL Emit và Object Pooling
Dapper là một trong những thư viện ORM tốc độ cao phổ biến nhất. Tuy nhiên, NpOn.Net-V2 đề xuất một mô hình ánh xạ (Mapping Model) độc lập nhằm tiến xa hơn trong việc quản lý bộ nhớ (Allocation Control).
Tái sử dụng vùng nhớ (Object Pooling)
Việc khởi tạo dồn dập các đối tượng khi ánh xạ tập dữ liệu lớn luôn tạo áp lực lên bộ thu gom rác (Garbage Collector - GC). Hệ thống ứng dụng một cơ chế Object Pooling nội bộ nhằm tái chế các container vùng nhớ của object sau quá trình truyền tải, giúp giảm thiểu tối đa tần suất bị đình trệ do quá trình quét rác.
Biên dịch động qua IL Emit & Expression Tree
Kỹ thuật Reflection thông thường gặp nút thắt lớn về chi phí tìm kiếm metadata. Hệ thống phá bỏ rào cản này bằng cách:
- Biên dịch động các mô hình xử lý ánh xạ thông qua IL Emit (Intermediate Language) và Expression Trees cho mỗi kiểu đối tượng.
- Chỉ mất chi phí compile ở lần ánh xạ đầu tiên. Nhờ đó kết quả thu được mang lại tốc độ map dữ liệu (casting & mapping) chớp nhoáng, cạnh tranh sòng phẳng với việc gán biến property thủ công.
5. Chuẩn hóa cấu trúc với INpOnResultSetWrapper
Dù là quản trị dữ liệu Relational, Wide-Column hay Key-Value, chúng đều chia sẻ chung một lý thuyết nguyên thủy: Tiếp nhận một câu lệnh (Command Pipeline) và trả về một cây cấu trúc dữ liệu (Data Node).
Hệ thống cô đọng nguyên lý này vào một Interface trừu tượng duy nhất: INpOnResultSetWrapper.
- Vai trò định tuyến: Interface này chuẩn hoá mọi luồng kết quả thô rải rác trả về từ muôn vàn loại Database thành một dạng đại diện ngôn ngữ đồng nhất. Trình ánh xạ (IL Emit ORM) chỉ giao tiếp độc quyền với Wrapper này mà không mảy may quan tâm xem cái Database Engine nằm bên dưới là loài nào.
- Khả năng mở rộng (Extensibility): Hỗ trợ thêm một nền tảng Database lạ lẫm vào hệ sinh thái chỉ đơn giản là viết một adapter nhẹ để biên dịch kết quả của nó thành cái khuôn chuẩn hoá này.
- Thực tiễn áp dụng: Chuẩn giao tiếp Wrapper này đã được đưa vào thực nghiệm vững chãi cho PostgreSQL, Cassandra, Redis và RabbitMQ. Đối với Kafka, các liên kết đã thành hình nhưng vẫn đang trong giai đoạn tối ưu lại Flow để mượt mà hơn. Riêng Module dành cho ElasticSearch hiện đang trong tiến trình phát triển hăng say (WIP).
6. Điều hướng kết nối qua mạng lưới Dual-Pipeline gRPC
Core của hệ thống chủ động sử dụng cơ sở hạ tầng mạng Code-first (protobuf-net.Grpc), biến gRPC thành các đường ống dẫn truyền tín hiệu với mục tiêu cụ thể:
- Pipeline Nội Bộ (S2S): Giữa tầng các Service cốt lõi, mạng được đẩy qua nền HTTP/2 Binary độc quyền. Nó triệt bỏ hoàn toàn gánh nặng phải đóng gói hay dịch mã JSON lê thê của REST truyền thống, giúp dữ liệu được bắn đi qua lại giữa các máy chủ một cách siêu tốc.
- Pipeline Giao Diện (Public Gateway): Đối với các Services chịu trách nhiệm tương tác ra ngoài, hệ thống chia ngã ba tự động. Nó vừa mở đường chuẩn API HTTP/1.1 JSON truyền thống ở cổng mặc định để dễ dàng kết dính cùng Frontend, đồng thời mở song song một cổng kết nối gRPC plain-text (
h2c) phục vụ nhu cầu kiểm thử (vd: xài Postman) cho Developer một cách gọn gàng và độc lập.
7. Đánh giá hiệu năng thực tế (Benchmarks)
Sức chịu đựng của cấu trúc hàng đợi Queue trên thư viện lõi NpOn đã chứng minh được tính hiệu quả cao khi phân tán ra thực tế. Đây là những thông số ghi nhận trên Management node ở tác vụ kiểm thử áp lực:
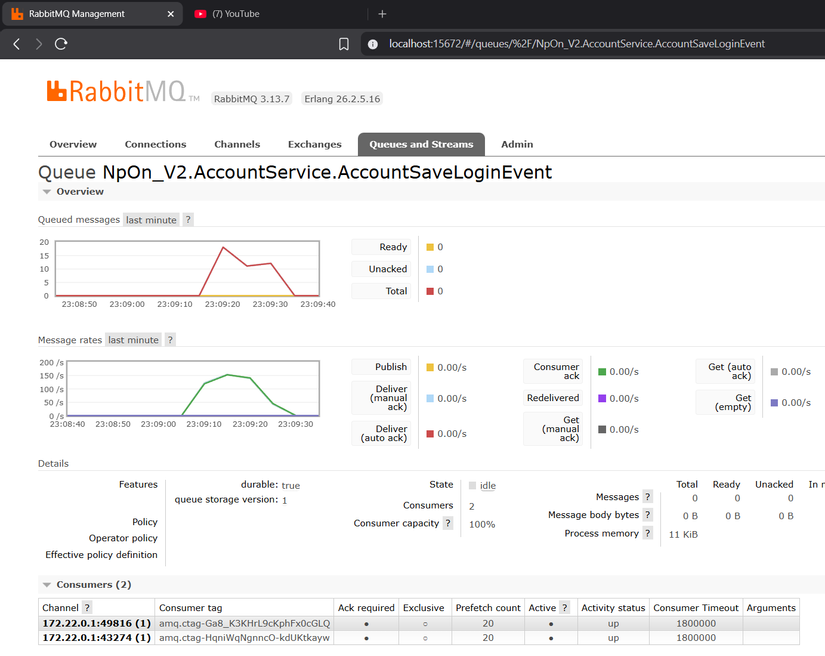 (Biểu đồ thể hiện tần suất lưu lượng thông điệp (Message Rates) được duy trì trôi chảy khi thực thi thông báo qua Single Node)
(Biểu đồ thể hiện tần suất lưu lượng thông điệp (Message Rates) được duy trì trôi chảy khi thực thi thông báo qua Single Node)
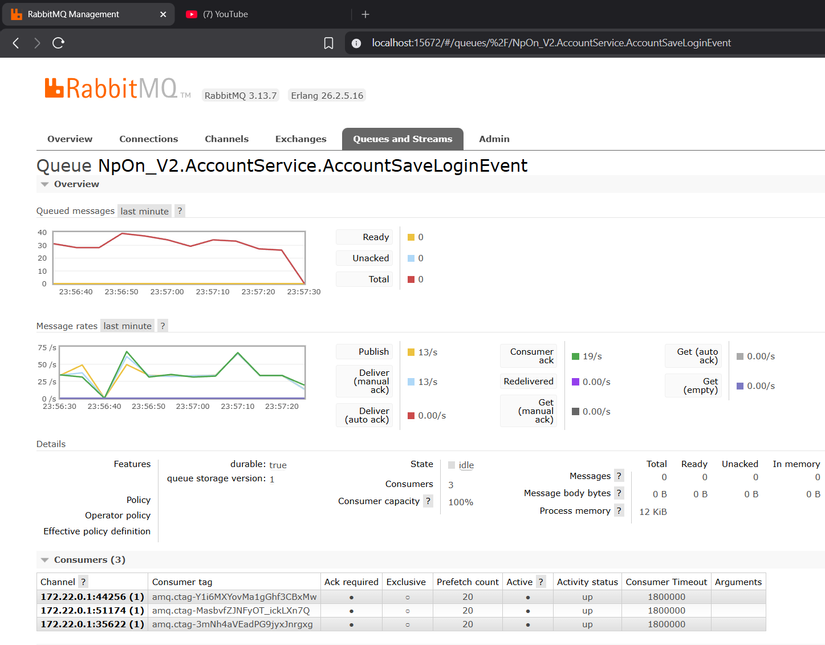 (Biểu đồ phản ánh đường truyền thông điệp duy trì độ gắn kết mạnh mẽ qua cụm độ trễ thấp 3-Node Cluster).
(Biểu đồ phản ánh đường truyền thông điệp duy trì độ gắn kết mạnh mẽ qua cụm độ trễ thấp 3-Node Cluster).
Hệ thống tải mượt mà lưu lượng lớn thông điệp mỗi giây trên kênh thiết lập (AccountSaveLoginEvent) với hệ thống Consumer phân bổ tải trơn tru, không chịu bất kỳ hiện tượng xé xung rớt nhịp nào xuyên suốt quá trình chạy.
Tổng kết
Kiến trúc này hiện đã và đang được triển khai thực tế trên hệ thống phần mềm Nghiệp Vụ Y Tế. Nó đáp ứng tốt những đòi hỏi khắt khe nhất về tính nhất quán, lưu lượng xử lý dữ liệu và yêu cầu hệ thống phải duy trì vận hành (uptime) triền miên một cách ổn định nhất trong Domain ngành y dược.
Bài viết hy vọng sẽ đóng góp các mảng ghép cấu trúc lý thú cho cộng đồng kỹ sư. Anh em bạn bè có thể tìm hiểu để tự viết hoặc bổ sung các cơ chế mở rộng hiện đại (như cơ chế chống gãy vỡ Saga Pattern) chèn vào bên trong các thành tố thiết kế này để làm mịn quy trình Rollback trên toàn cõi Services.
Mã nguồn mở (GitHub Repository): https://github.com/LeDucPr/NpOn.Net-V2
All rights reserved
