NoSQL: Cassandra, Part:2
Bài đăng này đã không được cập nhật trong 4 năm
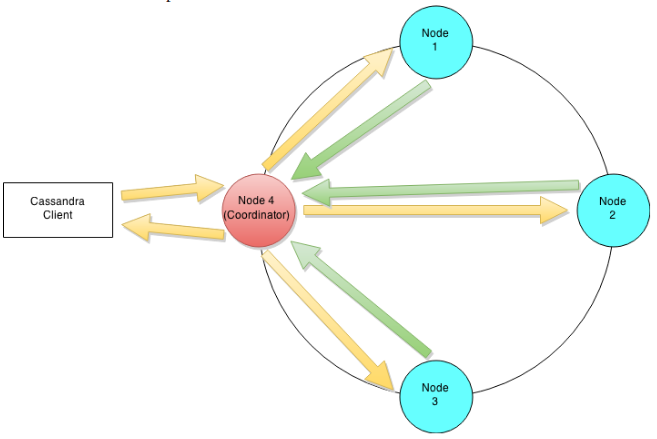
In Part 1, We've seen Cassandra operations with only single node, which is practically not actual use of Cassandra. First, some overview, cluster is arrangement of nodes as a ring. Clients send CRUD operation requests to any of the node in the ring; that node takes the role as coordinating node, forwards the request to the other nodes which duty is to serve the request.
Cassandra Strategy
A Cassandra cluster is conceptualized as a ring because it uses a stable hashing algorithm to distribute data. At start up each node is allocated a token range which determines its position in the cluster and the rage of data stored by the node. Each node receives a commensurable range of the token ranges to ensure that data is spread evenly across the ring. Each node is assigned a token and is accountable for token values from the previous token (exclusive) to the node's token (inclusive). Each node in a Cassandra cluster is accountable for a certain set of data which is determined by the partitioner. A partitioner is a hash function for computing the resultant token for a particular row key. This token is then used to determine the node which will store the first replica. Currently Cassandra offers a Murmur3Partitioner (default), RandomPartitioner and a ByteOrderedPartitioner .
Replication
Cassandra also keep copy of data according to the chosen replication strategy. The replication strategy determines arrangement of the replicated data. There are two main replication strategies used by Cassandra, Simple Strategy and the Network Topology Strategy. The first replica for the data is determined by the partitioner. The placement of the subsequent replicas is determined by the replication strategy. The simple strategy places the subsequent replicas on the next node in a clockwise manner. The network topology strategy works fine when Cassandra is deployed across number of data centres. Data centre awares and makes sure that copy are not stored on the same rack. Cassandra uses snitches to discover the overall network overall topology. This information is used to efficiently route inter-node requests within the bounds of the replica placement strategy.
Cassandra Write Path
Lets have a walk to understand Cassandra's architecture through an example write operation. Assume that a client wants to write some data to the database. The diagram below shows the cluster level interaction that takes place.Since Cassandra doesn't follow master-slave, a client can connect with any of the node in a cluster. Clients can interface with a Cassandra node using either a thrift protocol or using CQL The node that a client connects to is defined as the coordinator. The coordinators' responsibility is satisfying the clients request. The consistency level fixes the number of nodes that the coordinator needs to hear from in order to notify the client of a successful operation. Inter-node requests are sent through a messaging service in an asynchronous manner. Based on the partition key and the replication strategy used the coordinator forwards the mutation to all applicable nodes. In this example it is predicted that nodes 1,2 and 3 are the applicable nodes where node 1 is the first replica and nodes 2 and 3 are subsequent replications. The coordinator will wait for a response from the suitable number of nodes required to satisfy the consistency level. QUORUM is a majorly used consistency level. this can be calculated using the (n/2 +1) formula where n is the replication factor. In this example let's assume that we have a consistency level of QUORUM and a replication factor of 3. Thus the coordinator will wait for at most 10 seconds (default setting) to hear from at least two nodes before informing the client of a successful reply. Every node first writes the mutation to the commit log and then writes the mutation to the memtable. Writing to the commit log ensures durability of the write as the memtable is an in-memory structure and is only written to disk when the memtable is flushed to disk. A memtable is flushed to disk when:
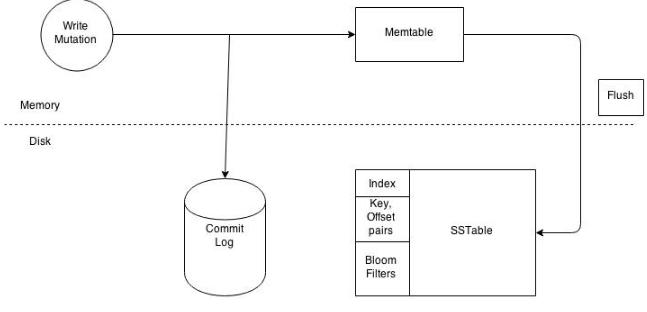
Figure: Write operations at a node level
It reaches its max level size in memory The number of minutes a memtable can stay in memory elapses. Manually flushed by a user A memtable is flushed to an unchanged structure called and SSTable (Sorted String Table). The commit log is used for playback purposes in case data from the memtable is lost due to node failure. For example the machine has a power outage before the memtable could get flushed. Every SSTable creates three files on disk which include a bloom filter, a key index and a data file. Over a period of time a number of SSTables are created. This results in the need to read multiple SSTables to satisfy a read request. Compaction is the process of combining SSTables so that related data can be found in a single SSTable. This helps with making reads much faster.
Cassandra Read Path
At the cluster level a read operation is as same as a write operation. As with the write path the client can connect with any node in the cluster. The selected node is called the coordinator and is responsible for returning the requested data. A row key must required for every read operation. The coordinator uses the row key to determine the first replica. The replication strategy in conjunction with the replication factor is used to find all other applicable replicas.The write path the consistency level determines the number of replica's which must respond before successfully returning data. Let's assume that the request has a consistency level of QUORUM and a replication factor of 3, thus requiring the coordinator to wait for successful replies from at least 2 nodes. If the contacted replicas has a different version of the data the coordinator returns the latest version to the client and issues a read repair command to the node/nodes with the older version of the data. The read repair operation pushes the newer edition of the data to nodes with the older edition. Every Column Family stores data in a number of SSTables. Thus Data for a particular row can be located in a number of SSTables and the memtable. Thus for every read request Cassandra needs to read data from all applicable SSTables and scan the memtable for applicable data fragments. This data is then saved and returned to the coordinator.
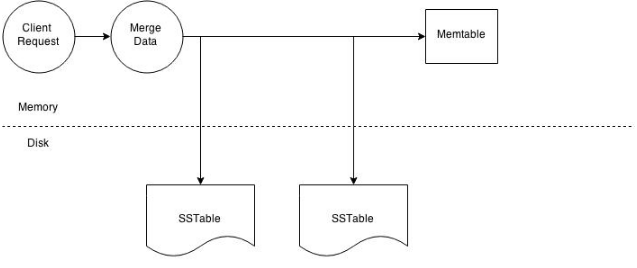
figure: Node level read operation
On a SSTable base, the operation becomes a bit more complicated. Every SSTable has an associated bloom filter which activates it to quickly ascertain if data for the requested row key exists on the corresponding SSTable. This reduces IO when performing an row key lookup. A bloom filter is always held in memory since the whole purpose is to save disk IO. Cassandra also keeps a copy of the bloom filter on disk which enables it to recreate the bloom filter in memory quickly . Cassandra does not store the bloom filter Java Heap instead makes a separate allocation for it in memory. If the bloom filter returns a negative response no data is returned from the particular SSTable. This is a common case as the compaction operation tries to group all row key related data into as few SSTables as possible.
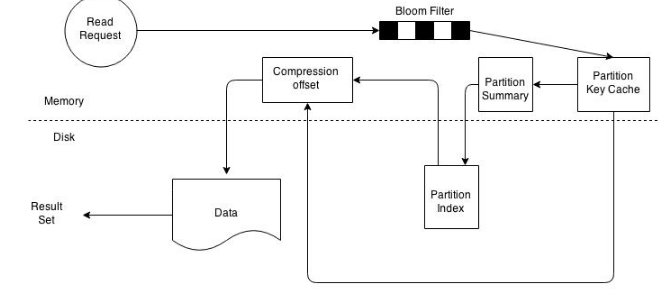
figure: SSTable read path
If the bloom filter provides a assertive response the partition key cache is scanned to ascertain the compression offset for the requested row key. It then proceeds to fetch the compressed data on disk and returns the result set. If the partition cache does not contain a corresponding entry the partition key summary is scanned. The partition summary is a subset to the partition index and helps determine the approximate location of the index entry in the partition index. The partition index is then scanned to locate the compression offset which is then used to find the appropriate data on disk.
If you reached the end of this long post then well done and Thank You.
** Part 1: Cassandra Architecture, Data Structure and Basic operations**
All rights reserved
