NoSQL: Cassandra, Data Modeling using KDM Tool Part: 3
Bài đăng này đã không được cập nhật trong 4 năm
The Kashlev Data Modeler (KDM) is a well bulit big data modeling tool that generates schema design for Apache Cassandra autometically. KDM employs a query-driven approach to data modeling that significantly differs from the traditional RDMS modeling. Using its interactive UI, KDM gives a complete view of every level of data modeling cycle to users. It starts with conceptual data model of a system i.e ERD in respect of RDMS. Then data access patterns which totally depends on the queries generation, and ends with a logical and a physical data model. It also provides a CQL script. KDM can do the most complex, error-prone, and time-consuming data modeling. KDM dramatically reduces time, simplifies, and streamlines Cassandra database design.
where to find: http://kdm.dataview.org/ then just sign up with an username and a password. BANG!! then use KDM
Step 1 : Conceptual Model
The following four data modeling principles we need to follow to design a data model in cassandra. Then gradually we will move to a logical level from the conceptual level. The steps are
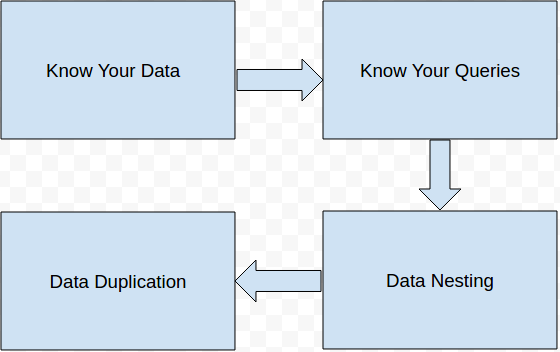
Know Your Data- The first key to successful database design is understanding the data, which is captured with a conceptual data model. The importance and effort required for conceptual data modeling should not be underestimated. Entity, relationship, and attribute types on an ER diagram
Know Your Queries- The key to effective nosql database design is understanding the queries, which are captured via an application workflow model. Like data, queries directly affect table schema design, and if our use case assumptions about the queries change, a database schema will have to change, too.
Data Nesting- The third key to successful database design is data nesting. Data nesting refers to a technique that organizes multiple entities (usually of the same type) together based on a known criterion. Such criterion can be that all nested entities must have the same value for some attribute.
Data Duplication- The fourth key to successful database design is data replication. Replicating data in Cassandra across multiple tables, partitions, and rows is a common practice. It is required to effectually support different queries over the same data. It is far better to duplicate data to enable the “partition per query” access path than to join data from multiple tables and partitions.
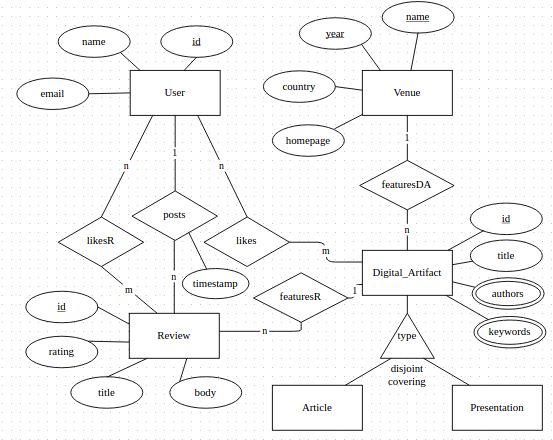
Now lets assume a scenario of a conference. User can register to the system. This system archives published digital atrifacts (DA) in two criteria 1. Article or 2. Presentation. Any DA must be featured by a Venue, and each of the Venue features one or many artifacts. User can like any DA, can post Reviews, or even can like reviews. Designing an ERD in NoSQL is pretty similar to any RDMS ERD. So no need to take a heck for it, just design it as you like and know about ERD diagram. After modeling the design just click the right button of the mouse on the entity levels and set primary key(or keys).
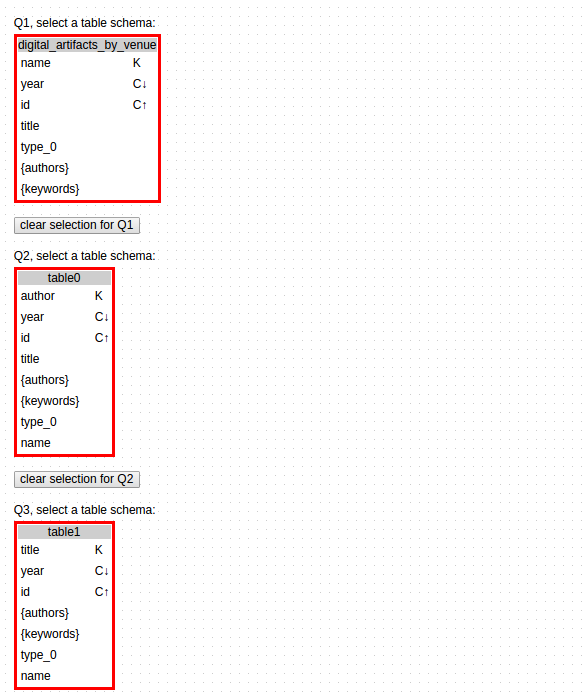
Step 2. Access Pattern
This part is a vital part of the casandra DB modeling. recall the keys what we discussed earlier. know your data and know your queries. So we have to know our queries and data patterns. hit the Access Pattern button. Assume that we have the following queries to serve
Q1. find artifacts for a specified venue; order by year (DESC). Q2. find artifacts for a specified author; order by year (DESC). Q3. Find information for a specified venue. Q4. Find a user with a specified id. Q5. Find the number of 'likes' of a specified review. and so on.
Let's go to assign the access patterns. fist we have to determine what we want by what we have. for example, for Q4. we have a user_id of an user, we need need the information of that user. So go to the conceptual model and right click on user_id and assign given value (=) to it. Now we want. Same way, just right click on the desire attributes and assign find to them.
If we need to serve a query which need to fetch data from two entity, first thing first is find out
the relational ways through which these entities are connected. If its a one way communication, its simple choose simple access pattern and do the same what we did for Q4. If it has multiple way, the choose cyclic access pattern. Select the given and find values as the same way, but but we need to restrict the relationship path by which they related for that particlar query. for example, in Q2, we need artifacts for a specified author order by year (DESC)., so we have author's id, put it as given, we need his/her artifacts, so put DA's id, DA's title, year and so on as find. Now click on generate relation button and select the featureDA. generate different queries and play around.
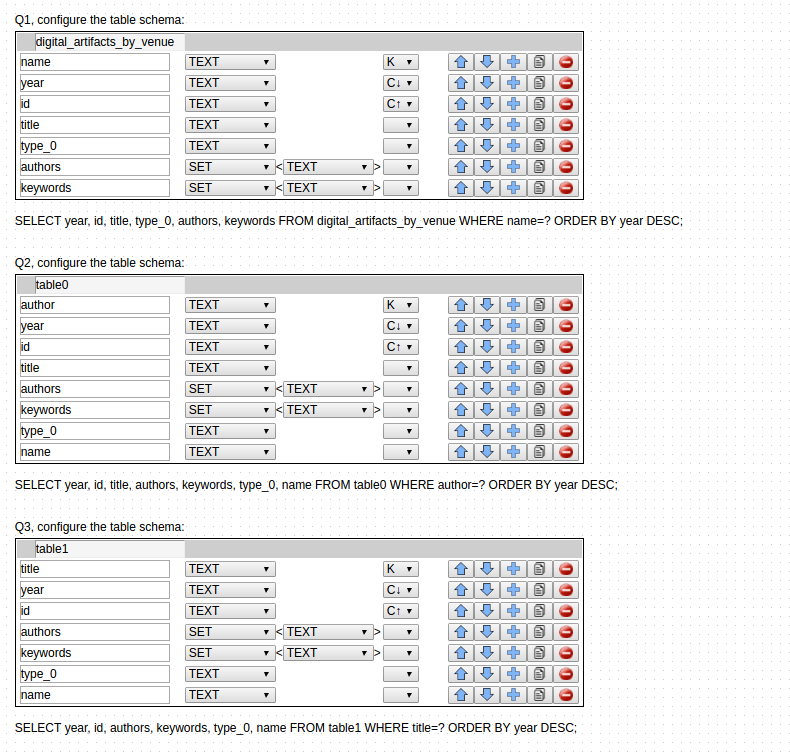
Step 3. Logical Model
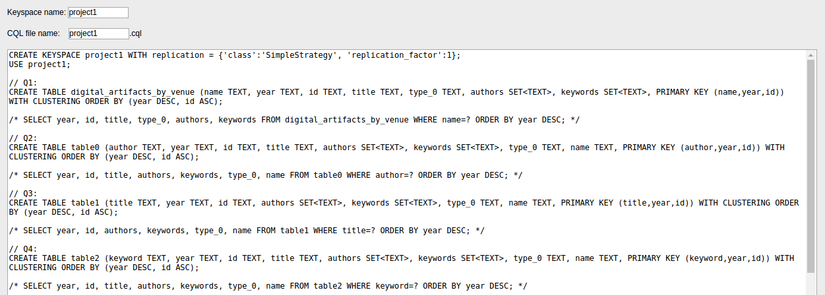
We completed our duties already, now its KDM's job to generate logical model, physical model and a CQL script for us. Click on Logical button. Dedicated tables for each query will be generated, sometimes more than one table could be generated, just select the best possible one which serves our interest.like this
Step 4. Physical Model
Do you know we are very near to our desired CQL script? yes we are. Click on Physical button. customise the table as you want. Such as, define primary key, cluster key, statics, change table names, add or delete field.... so on. now Do the last thing, Just Click on Download CQL button. and get the script and run the script in your cqlsh shell.
DONE. SMILE 
If you reached the end of this long post then well done and Thank You.
Part 1: Cassandra Architecture, Data Structure and Basic operations
Part 2: NoSQL: Cassandra, Part:2
All rights reserved
