Những điều mà REST chưa làm được?
Bài đăng này đã không được cập nhật trong 8 năm
Bài viết được dịch từ Dive Into GraphQL Đây là bài đầu tiên của series Dive Into GraphQL Series. Nhưng rất hay là bài viết này lại không nói về GraphQL là gì mà nói về những vấn để nó giải quyết. Và chúng ta sẽ tìm hiểu về những gì REST chưa làm được.
REST và kiến trúc cho API
Đầu tiên, không có gì là sai với REST cả, REST là hướng giải quyết hoàn hảo cho cho vấn đề xây dựng một kiến trúc API. Trước khi có REST, SOAP một web service yêu cầu các công cụ rất phức tạp, mất nhiều thời gian để cấu hình và rất nhiều việc phải làm bằng tay. Việc tạo ra web service đòi hỏi các SDK bản quyền, hoặc mã nguồn không publish. Thời điểm đó, việc tạo ra một web service từ trình duyệt là điều không tưởng.
REST, được phát minh từ năm 2000 và trở lên phổ biến 2007, bởi cú pháp đơn giản của nó. REST làm cho request và response trở lên dễ dàng build và parse, đó là lí do tại sao các lập trình viên frontend và backend lại dễ dàng yêu thích nó đến vậy. REST cũng stateless và cacheable, nó làm phát triển cộng đồng sử dụng web service. Nó hoạt động tốt cho đến hiện nay, kiến trúc API ở mọi nơi và REST đang là một sự lựa chọn tốt.
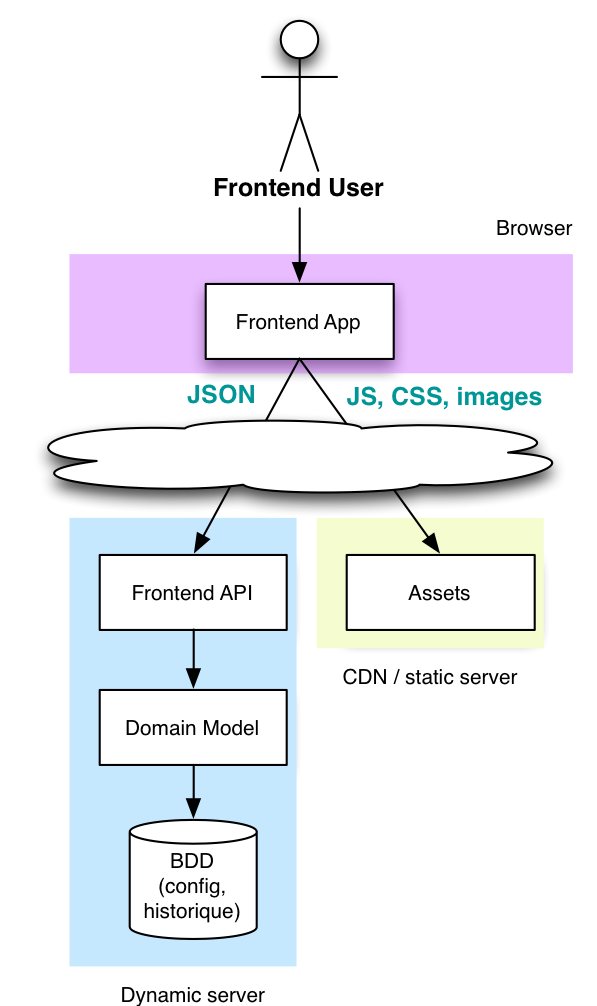
Nhưng thế giới đã thay đổi từ năm 2007. Hãy xem tại sao.
Internet hiện nay chủ yếu là di động
Năm 2015, Google đã thông báo điều đầu tiên, chúng tôi nhận được nhiều lượt tìm kiếm từ di động hơn từ máy tính. Từ đó, các nhà cung cấp Internet đã phát triển băng tần cho Internet di động, kết nối các cable cùng với nhau. Vì vậy cần phải đối mặt: những sản phẩm web apps được xây dựng ngày nay sẽ chủ yếu được sử dụng bởi các thiết bị di động, chứ không phải wifi.
Thiết bị di động 4G hay 3G đều chậm hơn wifi, bởi vì môi trường truyền sóng radio dao động giữa 100ms và 600ms trên 4G(3500ms trên 3G), và cũng bởi vì số lượng kết nối di động rất nhiều, nó ảnh hưởng đến tốc độ và độ trễ.
Với mỗi HTTP request, thời gian reponse trả về là 1 giây, nó được nghiên cứu user's flow of thoughts limit bởi chuyên gia UX Jakob Nielsen. Điều đó có nghĩa là tối đa số HTTP request của ứng dụng di động có thể thực hiện mà không mất dữ liệu chỉ là 1.

Đấy là chưa kể đến thời lượng pin. Sử dụng sóng radio rất tốn năng lượng, vì vậy thiết bị di động sẽ tắt radio ngay khi có thể, dẫn tới việc mất các kênh kết nối với trạm phát sóng. Để thực hiện request thiết bị di dộng cần phải kết nối đến trạm phát sóng để gửi HTTP request. Vì vậy, vấn đề thời lượng pin cũng ảnh hưởng đến người thiết kế App.
Kiến trúc hướng dịch vụ (cho client)
Tưởng tượng ưng dụng Twitter-like sử dụng REST API cho backend. Hãy lên danh sách những dữ liệu mà cần phát fetch để hiển thị lên trang chính:
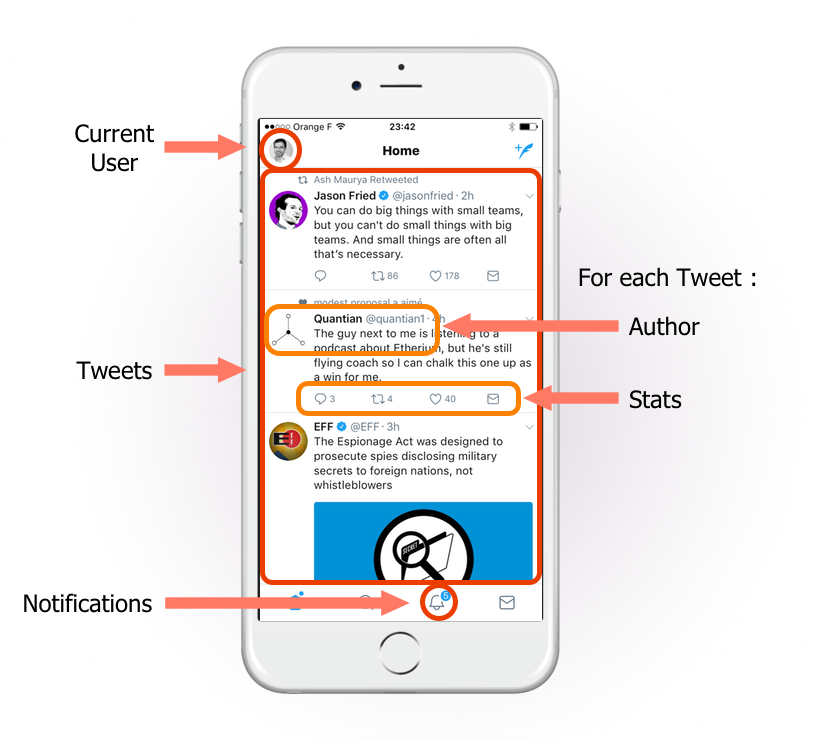
REST backend sẽ cần 1 endpoint(địa chỉ url)/1 dữ liệu. Vì vậy ứng dụng sẽ phải gửi request đến ít nhất những endpoint:
- GET /user current user name và avatar
- GET /notifications số các thông báo chưa đọc
- GET /tweets danh sách 20 các bài viết mới nhất
- GET /users?ids=[123, 456, 789, ...] thông tin profile của tác giả của 20 bài viết mới nhất
- GET /tweet_stats?ids=[123, 456, 789, ...] stats của 20 bài viết mới nhất
- POST /views gửi view stats cho những tweets đã được hiển thị
Đó là 6 HTTP request - chưa tính các request cho avatar images, hay các media nhúng trong tweet. Resquest 4, 5 sẽ phải chờ request 3. Và với 1 trang đơn giản cần hơn 1 giây để lấy các data cần thiết.
Bên cạnh đó, web và ứng dụng di động sử dụng nhiều hơn 1 nhà cung cấp service(được hiểu là nhiều hơn 1 HTTP domain). Ví dụ như: authentication, avatars, comments, analytics, ... Vấn đề độ trễ trở lên rất vất vả, bởi mỗi domain mới lại cần đến phân tích tìm kiếm DNS và HTTP client không thể giữ kết nối giữa các domain.
Tóm lại, nhược điểm chính của REST là làm cho clients trở lên chậm hơn, đặc biệt trên di động.
Nhóm các request
Một trong những giải pháp là data inclusion. Ý tưởng là request nhiều dữ liệu từ 1 endpoint, server sẽ dữ liệu liên quan:
GET /tweets?include=authors,stats
Nó cho phép gộp request 3, 4, 5 request. Data inclusion không cho phép gộp các request mà không liên quan đến nhau (ví dụ như tweets và notifications)
Năm 2013, Facebook giới thiệu một giải pháp khác. Nó gọi là the Batch endpoin. Nó là 1 REST endpoint, bạn có thể gửi nhiều sub-request trong batch query parameter:
curl \
-F 'access_token=...' \
-F 'batch=[{"method":"GET", "relative_url":"me"},{"method":"GET", "relative_url":"me/friends?limit=50"}]' \
https://graph.facebook.com
Một cách khác, Facebook server queries cho những data stores, và nhóm các kết quả vào 1 JSON response:
[
{ "code": 200,
"headers":[
{ "name": "Content-Type",
"value": "text/javascript; charset=UTF-8" }
],
"body": "{\"id\":\"…\"}"},
{ "code": 200,
"headers":[
{ "name":"Content-Type",
"value":"text/javascript; charset=UTF-8"}
],
"body":"{\"data\": [{…}]}}
]
Không có chuẩn có nghĩa là có quá nhiều chuẩn
REST không phải là một chuẩn, nó là một kiểu kiến trúc, một bộ các quy tắc.

Lập trình Frontent và Backend cần một cam kết
Những hướng giải quyết
Tóm lại, kiến trúc REST làm cho ứng dụng chậm, khó khăn và đắt hơn để phát triển và quá giới hạn chức năng. Những vấn đề là có thật. Rất nhiều công ty đã chịu đựng REST, và cố gắng tìm một thứ thay thế tốt hơn.
Có thể chúng ta có thể vá REST bằng cách thêm tất cả những gì mà nó thiểu: HTTP/2 for request multiplexing, batch endpoint, sparse fieldset selectors, schemas, swagger documetation, ... Có những API platform danh cho vấn đề này. Theo ý kiến riêng của tôi đó giống như eat soup with a fork. Bạn có thể tự mình quản lý nó bằng tay, nhưng đó có thực sự là ý tưởng tốt không? Tôi xem xét rằng REST không thực sự phù hợp với những yêu cầu mô hình web app hiện đại. Và thật không may, những gì mà Marmelab đã đầu tư cho REST how much Marmelab, my company, has invested into REST.
Tại sao không sử dụng SQL qua HTTP? SQL có UNION, JOIN, HAVING, BY, và nó đã được chuẩn hoá. Những queries đó sẽ được sử dụng cho database schema. Nhưng SQL có những hạn chế cho SELECT, CREATE, UPDATE, và DELETE, do vậy vẫn quá giới hạn trong việc sử dụng trường hợp này. Và hãy giữ ý tưởng về sử dụng ngôn ngữ query khai báo.
Nếu bạn nghĩ bạn có thể vượt qua những giới hạn bằng việc sự dụng old Remote Procedure Call (RPC), bạn có thể đã đúng. Nhưng rủi ro là sẽ lại vấp ngã với SOAP, và không ai muốn rơi vào [the bit of utmost complexity] (http://web.archive.org/web/20070113213839/http://www.loudthinking.com/arc/000602.html) một lần nữa.

Google đã sáng chế ra Protocol Buffers để tối ưu hiệu năng và dùng để schema, và nó đã được public vào năm 2008. Đây là một cơ chế mở rộng trung lập, nền tảng trung lập về ngôn ngữ để tuần tự hóa dữ liệu có cấu trúc. Đó là một giải pháp tốt, nhưng nó không giải quyết vấn đề phức tạp của các truy vấn và aggregations. Không giống như Apache Thrift, một giao thức nhị phân cho RPC.
Gần hơn chiếc Chén Thánh là Falcor, được mở từ Netflix vào giữa năm 2015. Falcor là cả một máy chủ trung gian và một SDK khách hàng. Nhưng đó là một công cụ chứ không phải là một kiến trúc. Và nó chỉ có JavaScript; nếu bạn đang làm Mục tiêu-C hoặc Kotlin, bạn đang trên sự may mắn. Falcor không cung cấp giản đồ và kiểu tĩnh, và nó thiếu ngôn ngữ truy vấn mạnh mẽ.
Tóm lại
Không có cách gì tốt hơn. Điều gì cần để thay thế REST với một kiến trúc mới cho phép:
- Tập hợp các tài nguyên truy vấn (ví dụ: tweets và hồ sơ, trong một chuyến đi vòng), ngay cả từ các tên miền khác nhau
- Truy vấn một danh sách rõ ràng các trường, không phải là một tài nguyên hoàn chỉnh
- Cung cấp một lược đồ mô tả cú pháp của request và response
- Là một tiêu chuẩn, nhưng không quá gắn với giao thức HTTP
- Hỗ trợ Publish / Subscribe các kịch bản ra khỏi hộp
- Chuyển các công việc từ server đến client.
Tôi tin rằng, một công cụ gần đây được publish bởi Facebook sẽ giải quyết được vấn đề này(gợi ý cho bạn là nó bắt đầu bằng chữ G). Đọc bài tiếp theo để khám phá ra đó là gì.

All rights reserved
