Những câu lệnh SQL hữu dụng
Bài đăng này đã không được cập nhật trong 7 năm
Hàn huyên trước khi học
Đã làm việc với database thì chắc hẳn ai cũng từng sử dụng sql để truy vấn và chỉnh sửa dữ liệu trong đó. Đối với những cơ sở dữ liệu có độ phức tạp thấp và tường minh thì câu truy vấn sẽ khá gọn gàng , dễ hiểu chỉ bằng những từ khóa thông dụng như select, join, group, ... Tuy nhiên thì trong một dự án thực tế, quy mô và độ phức tạp của database là khó lường trước (đặc biệt là dự án maintain), chúng ta không thể hòan thành công việc với những keywork cơ bản như vậy. Vì thế mà qua bài viết này, mình xin giới thiệu tới mọi người những câu lệnh sql hữu ích để có thể vượt qua những thử thách truy vấn.
Một số lệnh hữu dụng trong sql
DISTINCT
Lệnh này cho phép bạn loại bỏ những bản ghi trùng lặp khi select. Điều này đặc biệt có ý nghĩa khi bảng được select bị trùng lặp dữ liệu trên một vài đầu thuộc tính hoặc khi join các bảng lại với nhau, làm tăng thêm những kết quả không thực sự cần đến. Cú pháp:
SELECT DISTINCT
columns
FROM
table_name
WHERE
where_conditions
Đây là bảng dữ liệu demo của mình :

Sử dụng DISTINCT :
SELECT DISTINCT
`ho`, `ten`
FROM
`sinhvien`
WHERE
`IQ` > 100
ORDER BY `ho`
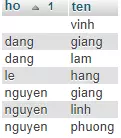
Như bạn có thể thấy, sau khi sử dụng DISTINCT thì các bản ghi trùng nhau giá trị sẽ bị lược bỏ.
Lưu ý là DISTINCT đánh giá sự trùng lặp theo cả bản ghi được select ra nên ở ví dụ trên các giá trị trong 1 cột vẫn có thể có cùng giá trị; và thêm nữa là giá trị null hay rỗng cũng đều được nhìn nhận giống như giá trị thông thường..
DISTINCT khá giống với GROUP BY và thực chất thì GROUP BY là một trường hợp đặc biệt của DISTINCT khi nó tự động sắp xếp kết quả còn DISTINCT thì không.
Tuy nhiên ở trên mình đã để ORDER BY nên kết quả sẽ giống với trường hợp GROUP BY (yaoming)
DISTINCT có thể ứng dụng cho một trường hợp khá hay, đó là kết hợp với hàm tính tập hợp giá trị như SUM() hoặc COUNT() .
Bằng cách này bạn truy vấn một cách bình thường và không loại bỏ bản ghi trùng lặp, tuy nhiên vẫn lấy được kết quả không lặp nhau theo một trường dữ liệu tự định nghĩa. Ví dụ như :
SELECT..., SUM(DISTINCT IQ) AS iq
FROM sinhvie
...
UNION
Hãy thử tưởng tượng dữ liệu gốc (là bảng ...FROM bảng_gốc... ấy) bạn muốn lấy đang ở 2 hoặc nhiều bảng khác nhau, bạn muốn lấy cũng một lúc với chỉ 1 lần query sql duy nhất chứ không query từng bảng rồi gộp vào nhau ở bên ngoài code thì phải làm thế nào.
Đó là vấn đề mà UNION sẽ xử lí hộ bạn, tất nhiên tư tưởng là giống nhau, vẫn sẽ gộp kết quả vào nhau nhưng là bên trong câu query giúp tiết kiệm thời gian mà cũng đỡ lặp sql. Cú pháp :
SELECT column_list
UNION
SELECT column_list
UNION
SELECT column_list
...
Để có thể gộp kết quả lại với nhau đòi hỏi sự tương thích giữa các tập hợp bản ghi con được select ra.
Điều này có nghĩa là những yêu cầu sau cần được đảm bảo :
- Số lượng trường dữ liệu phải bằng nhau.
- Thứ tự các trường cũng cần giống nhau.
- Tất nhiên là loại dữ liệu cũng phải giống hoặc tương đương nhau.
Lưu ý:
- bản chất chỉ là gộp các bản ghi lại với nhau, nên bạn hòan tòan có thể làm mọi thứ trong "SELECT column_list" thậm chí là UNION cả bên trong đó nếu phải làm.
- Kết quả mà bạn nhận được sẽ mặc định là không bị trùng lặp, UNION sẽ ngầm định làm điều đó thay bạn. Hoặc bạn có thể sử dụng DISTINCT ngay sau UNION với tác dụng tương tự.
- Trong một vài trường hợp, đôi khi bạn muốn lấy cả trùng lặp thì UNION cũng hòan tòan đáp ứng được. Hãy thêm ALL vào sau UNION và bạn sẽ thỏa mãn
Hãy nhìn qua ức ảnh này và bạn sẽ thấy nó thật dễ hiểu :
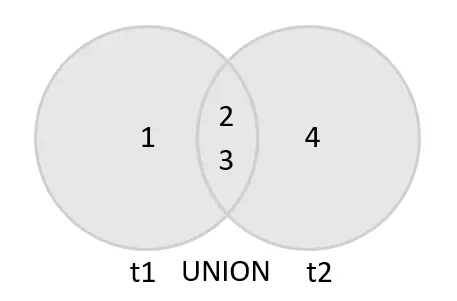 Từ t1 UNION sang t2 :
Từ t1 UNION sang t2 :
Dùng UNION (hay UNION DISTINCT) thì sẽ nhận được 1, 2, 3, 4.
Còn nếu dùng UNION ALL thì sẽ là 1, 2, 3, 2, 3, 4.
ROLLUP
ROLLUP giúp bạn thống kê được tổng phụ và tổng tòan cục.
Với ví dụ về bảng "sinhvien" ở trên, khi bạn muốn lấy tòan bộ bản ghi trong bảng kèm theo tổng IQ của tất cả sinh viên thì bạn sẽ làm như thế nào.
Rõ ràng là nếu bạn hiểu UNION bên trên thì thật là may mắn, vừa đọc xong đã áp dụng được luôn rồi phải không ?
Tuy nhiên trong trường hợp đặc biệt này, ROLLUP còn làm tốt hơn như thế kìa. Sở dĩ nó tốt hơn là bởi viết ngắn hơn, hiệu năng cũng tốt hơn luôn vì nó đâu phải query tới 2 lần xong lại còn gộp vào chứ, haizz ! Cú pháp :
SELECT
select_list
FROM
table_name
GROUP BY
c1, c2, c3 WITH ROLLUP;
Ví dụ với "sinhvien" :
SELECT DISTINCT
`ten` , SUM(`IQ`) totalIQ
FROM
`sinhvien`
GROUP BY
`ten` WITH ROLLUP;
Kết quả là 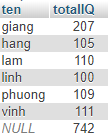
Các bạn đóan xem nếu GROUP BY hơn 1 trường dữ liệu thì điều gì sẽ xảy ra ?
nếu mình thêm cột score như sau : 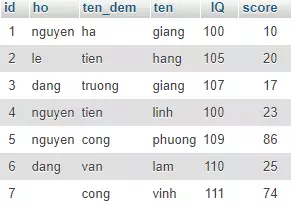 Và sửa lại sql thành :
Và sửa lại sql thành :
SELECT DISTINCT
`ten` , `IQ`, SUM(`score`) totalscore
FROM
`sinhvien`
GROUP BY
`ten`, `IQ` WITH ROLLUP;
Thì kết quả sẽ hư sau :
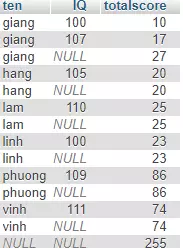
Vậy là sau khi GROUP BY thì score đã tự động được cộng dồn và ROLLUP sử dụng kết quả đó để thực hiện.
Thật đơn giản phải không các bạn, mong rằng qua bài chia sẻ này thì mọi người sẽ có thể áp dụng vào công việc một cách hiệu quả !
All rights reserved
