Ngừng lãng phí Token: 10 mẹo giảm lượng sử dụng Token của Claude Code
Sự phát triển của AI đang tăng tốc, nhưng lượng tiêu thụ token cũng đang tăng lên và ngày càng trở nên đắt đỏ hơn. Thậm chí các công cụ phổ biến từng miễn phí cũng bắt đầu thu phí. Là những nhà phát triển đầy tham vọng, việc tiết kiệm ở những nơi có thể và tránh mất thêm tiền cho các công ty AI là điều hợp lý. Mặc dù vậy, đôi khi các nhà phát triển tự hỏi sau khi chỉ viết vài hàm — tại sao Claude Code lại đắt như vậy, với lượng sử dụng token lên tới hàng trăm ngàn?
Thực tế, hiện tượng này hiếm khi do một câu lệnh (prompt) dài duy nhất. Thay vào đó, nó bắt nguồn từ việc quản lý ngữ cảnh (context) kém. Hôm nay, lấy Claude Code làm ví dụ, hãy cùng khám phá cách giảm chi phí token của Claude Code.
Đầu tiên, điều quan trọng cần hiểu là với tư cách là một tác nhân thông minh (intelligent agent) dựa trên terminal, Claude Code sẽ gửi toàn bộ lịch sử thảo luận trước đó, các tệp đã đọc và nhật ký thực thi công cụ tới API trong mỗi lượt để duy trì sự hiểu biết về dự án. Để nắm vững cách sử dụng Claude Code CLI tiết kiệm nhất, chìa khóa là ép giảm đường cong tăng trưởng ngữ cảnh thông qua các thói quen thao tác tinh tế và các chiến thuật kỹ thuật.

Thay đổi thói quen: Cắt giảm lãng phí Token từ gốc rễ
Thường thì việc tiêu thụ nhanh chóng xảy ra do thói quen sử dụng AI trên nền web được mang vào môi trường dòng lệnh (command-line).
Giữ các phiên (session) ngắn gọn
Các cuộc trò chuyện dài là nơi tiêu hao token ngầm nhất. Khi một phiên trở nên dài dòng, ngay cả việc gửi một tin nhắn cảm ơn đơn giản cũng buộc Claude phải đọc lại toàn bộ mã và các cuộc thảo luận trước đó. Hiệu ứng tích lũy này khiến chi phí tăng theo cấp số nhân.
- Chuyển đổi tác vụ đồng nghĩa với việc đặt lại (reset). Sau khi hoàn thành việc sửa một lỗi cụ thể hoặc một module tính năng, hãy bắt đầu một phiên mới ngay lập tức.
- Xóa bỏ các bộ nhớ vô ích. Sử dụng lệnh
/clearđể xóa ngữ cảnh không còn cần thiết. Đừng cố gắng giải quyết mười vấn đề khác nhau của dự án trong một luồng (thread) duy nhất.
Dừng việc lặp lại quá mức (over-iterating)
Các nhà phát triển thường gửi một hướng dẫn mơ hồ, thấy kết quả không chính xác và tiếp tục theo dõi bằng các điều chỉnh bổ sung. Cách làm này khiến nội dung của cùng một tệp được gửi đi gửi lại nhiều lần trong phiên.
- Chỉnh sửa prompt gốc thay vì thêm tin nhắn mới. Nếu một hướng dẫn bị sai, hãy nhấn mũi tên lên để chỉnh sửa prompt gốc và gửi lại. Thao tác này sẽ xóa lịch sử tương tác sai, khởi động lại ngữ cảnh và cắt giảm trực tiếp các chi phí không hợp lệ.
- Tránh các vòng lặp sửa lỗi (correction loops). Nếu một vấn đề không được khắc phục sau ba lần thử nghiệm, ngữ cảnh hiện tại có thể đã đầy nhiễu. Tại thời điểm này, việc đặt lại phiên và làm rõ logic sẽ tiết kiệm chi phí hơn là tiếp tục chắp vá.
Bật chế độ xử lý tác vụ hàng loạt (batching mode)
Hợp nhất các tác vụ liên quan là một bước hiệu quả cao để giảm chi phí. Thay vì đưa ra ba yêu cầu riêng biệt để sửa đổi A, thêm B và kiểm tra C, hãy kết hợp chúng thành một hướng dẫn duy nhất. Ví dụ: yêu cầu sửa lỗi trong hàm A, thêm chú thích và tạo các bài kiểm thử đơn vị (unit tests) cho hàm B cùng một lúc. Bằng cách này, Claude chỉ cần đọc nền tảng mã một lần để tạo ra một giải pháp hoàn chỉnh, tránh được sự hao tổn do phải tải đi tải lại cùng một tệp.

Chiến thuật Kỹ thuật: Kiểm soát chính xác Kiến trúc Ngữ cảnh
Vượt ra ngoài các thói quen thao tác, việc sử dụng chính xác các tính năng tích hợp là một trong những phương pháp hay nhất cho Claude Code CLI (best practices for Claude Code CLI) để chặn chính xác lưu lượng không cần thiết.
Chuyển đổi mô hình động và điều chỉnh mức độ nỗ lực
Không phải tất cả các tác vụ đều yêu cầu các mô hình cấp cao nhất. Việc sử dụng liên tục Opus cho các tác vụ nhỏ nhặt là một sự lãng phí tài nguyên khổng lồ.
- Haiku: Xử lý các tác vụ mang tính máy móc như định dạng mã, đổi tên biến và di chuyển tệp đơn giản.
- Sonnet: Công cụ chủ lực. Chịu trách nhiệm phát triển logic nghiệp vụ và triển khai hầu hết các tính năng.
- Opus: Chỉ được kích hoạt khi xử lý các thiết kế kiến trúc phức tạp trải dài trên nhiều tệp hoặc các bế tắc logic sâu sắc.
# Gọi các mô hình nhẹ cho các tác vụ xử lý văn bản hoặc định dạng cơ bản
/model haiku
# Giảm chiều sâu suy nghĩ cho các tác vụ thông thường để tiết kiệm chi phí đầu ra
/effort low

Ngăn chặn việc quét mù quáng và tận dụng chế độ kế hoạch
Dưới các hướng dẫn mơ hồ, AI có xu hướng đọc nhiều tệp để xây dựng sự hiểu biết. Để ngăn Claude Code đọc toàn bộ kho lưu trữ (stop Claude Code from reading entire repo), hãy cung cấp tọa độ chính xác.
- Chỉ định phạm vi số dòng. Nêu rõ ràng những dòng mã nào cần tập trung vào thay vì toàn bộ tệp.
- Vào chế độ kế hoạch. Nhấn
Shift+Tabđể chuyển sang trạng thái kế hoạch. Xem xét kế hoạch được đề xuất trước khi AI thực sự đọc các tệp lớn. Nếu nó có ý định đọc các tệp dữ liệu khổng lồ không liên quan, hãy can thiệp ngay lập tức.
# Ví dụ về một hướng dẫn với phạm vi phân tích được giới hạn nghiêm ngặt
So sánh logic đồng bộ hóa trạng thái giữa src/api/user.ts dòng 10-50 và src/store/auth.ts
Tinh giản bộ nhớ liên tục CLAUDE.md
Tệp CLAUDE.md được tải đầy đủ trong mỗi lượt trò chuyện. Nếu tệp này quá cồng kềnh, chi phí cơ bản của mỗi vòng sẽ tăng lên đáng kể. Việc áp dụng các mẹo quản lý cửa sổ ngữ cảnh của Claude Code (Claude Code context window management tips) ở đây rất được khuyến khích.
- Chỉ giữ lại các quy tắc cứng. Chỉ lưu trữ các lệnh thực thi kiểm thử, hướng dẫn về kiểu viết mã (code style) và các thư mục không được phép chạm vào.
- Xóa các tài liệu nền. Đừng nhồi nhét các thông số kỹ thuật lỗi thời hoặc lịch sử dự án dài dòng vào đó. Hãy định vị tệp này như một sổ tay vận hành thay vì một bách khoa toàn thư của dự án.
Sử dụng các tác nhân phụ (subagents) để cô lập các tác vụ tẻ nhạt
Các tác nhân phụ chạy trong các ngữ cảnh bị cô lập. Khi thực hiện các tác vụ tạo ra lượng thông tin dư thừa khổng lồ, chẳng hạn như tìm kiếm tệp hoặc phân tích nhật ký quy mô lớn, hãy giao chúng cho các tác nhân phụ. Khi hoàn thành, chúng chỉ mang kết luận trở lại cuộc trò chuyện chính. Hàng ngàn dòng của các quy trình trung gian đó vẫn ở trong không gian phụ mà không làm ô nhiễm không gian token của phiên chính.
Chẩn đoán và Bảo trì: Làm cho Chi phí trở nên Minh bạch
Chủ động thực hiện nén ngữ cảnh
Đừng đợi cho đến khi hệ thống nhắc rằng ngữ cảnh đã đầy. Sau khi giải quyết thành công một vấn đề mang tính cột mốc, hãy chủ động chạy lệnh /compact. Lệnh này nén các cuộc trò chuyện phức tạp thành các bản tóm tắt ngắn gọn, loại bỏ các lần thử trung gian và nhật ký lỗi dài dòng để nhường chỗ cho các tác vụ tiếp theo.
Sử dụng /context để giám sát theo thời gian thực
Lệnh /context là một công cụ chẩn đoán liệt kê rõ ràng nội dung nào hiện đang chiếm nhiều token nhất. Thông qua nó, có thể bắt được những thứ tiêu thụ khổng lồ ẩn giấu, chẳng hạn như một tệp cấu hình JSON khổng lồ vô tình được tải lên.
Chiến lược Nâng cao: Chuyển sang các Mô hình Ngôn ngữ Lớn (LLM) Cục bộ để Xóa bỏ Nỗi lo về Token
Bất kể tối ưu hóa thế nào, chừng nào còn phụ thuộc vào các API đám mây, chi phí token vẫn tồn tại. Khi việc thanh toán đám mây ngày càng trở nên đắt đỏ, việc sử dụng các mô hình lớn cục bộ đôi khi là một lựa chọn khôn ngoan.
Lợi ích của các mô hình lớn cục bộ là rất đáng kể:
- Chi phí bằng không thực sự. Mô hình chạy trên phần cứng cục bộ, vì vậy bất kể ngữ cảnh xếp chồng lên nhau dày đến đâu hoặc cuộc trò chuyện dài bao nhiêu, sẽ không có thêm hóa đơn API nào được tạo ra.
- Quyền riêng tư dữ liệu tuyệt đối. Nền tảng mã, cấu trúc dự án và logic nghiệp vụ không bao giờ rời khỏi thiết bị cục bộ. Đối với các dự án cấp doanh nghiệp liên quan đến dữ liệu mật, các mô hình cục bộ đáp ứng các yêu cầu tuân thủ khắt khe nhất.
- Tính khả dụng ngoại tuyến. Ngay cả trong môi trường mạng yếu hoặc hoàn toàn mất kết nối, việc đánh giá mã (code reviews) và tái cấu trúc (refactoring) vẫn có thể diễn ra suôn sẻ.
Trước đây, ngưỡng để cấu hình môi trường mô hình cục bộ rất cao, đòi hỏi phải xử lý các phần phụ thuộc phức tạp và các lệnh terminal. Ngày nay, với các môi trường phát triển Web hiện đại như ServBay, các nhà phát triển có thể dễ dàng đạt được việc triển khai các LLM cục bộ chỉ bằng một cú nhấp chuột (one-click deployment of local LLMs).
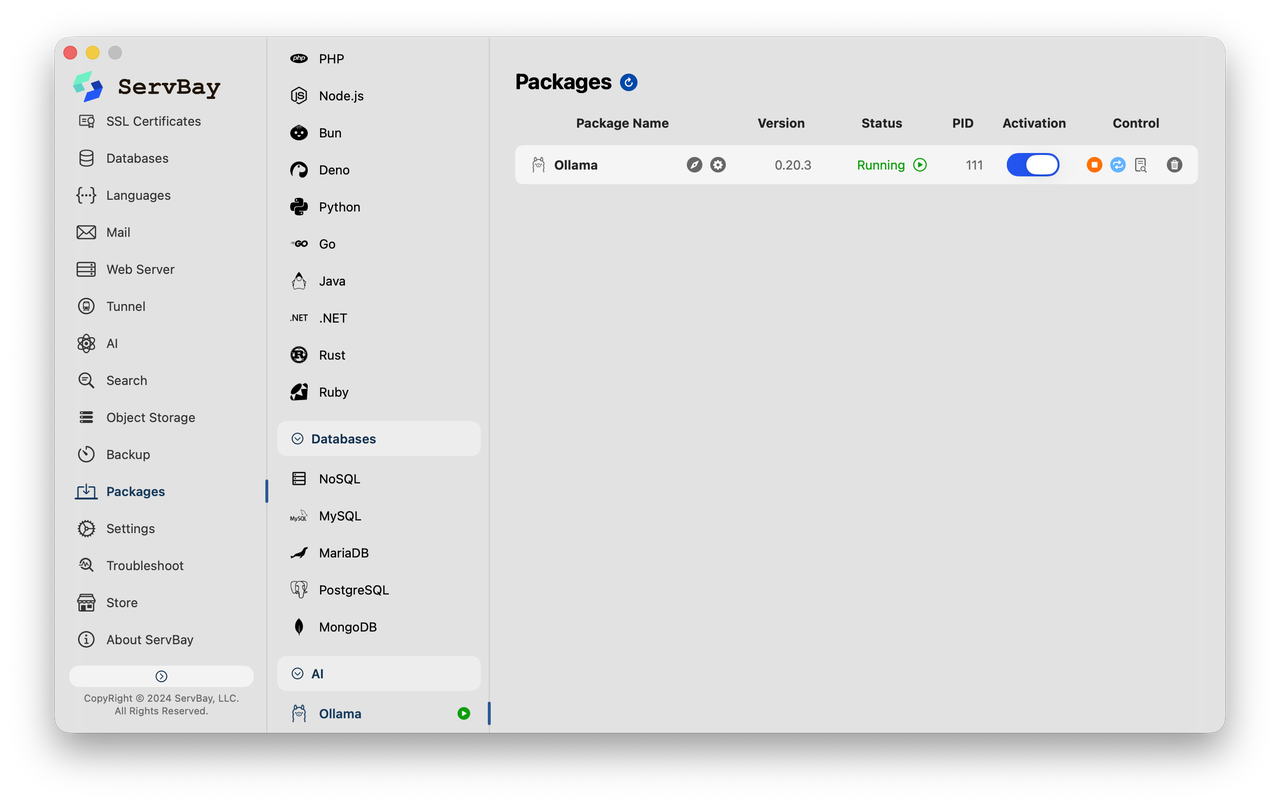
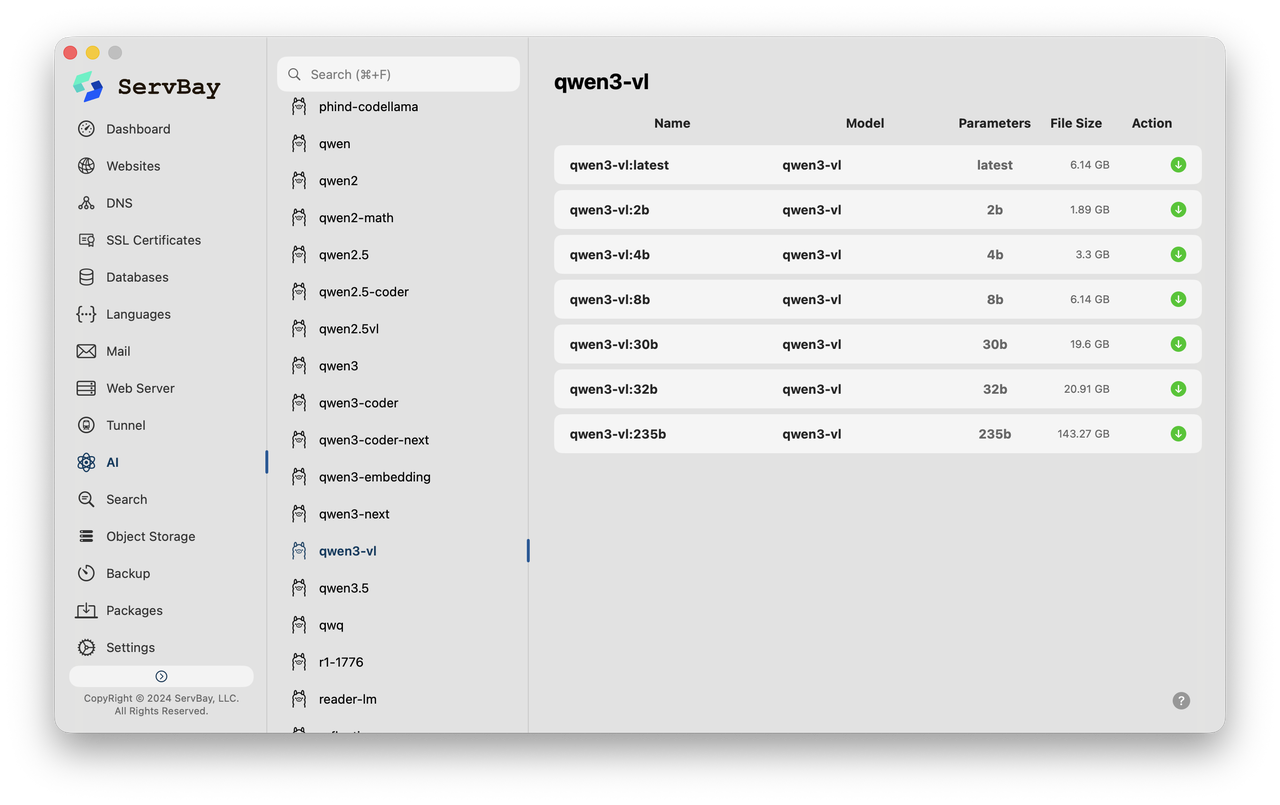
Bằng cách tích hợp công cụ Ollama, ServBay làm cho việc tải xuống, chạy và quản lý các mô hình AI cục bộ trở nên đơn giản như tải xuống một ứng dụng di động. Kết hợp với các công cụ dòng lệnh hoặc plugin soạn thảo tương thích, các nhà phát triển có thể tận hưởng sự hỗ trợ viết mã của AI mà không phải đau đầu vì hóa đơn token.
Tổng kết
Việc kiểm soát lượng sử dụng token của Claude Code không phải là hạn chế tần suất mà là xây dựng nhận thức về quản lý tài sản ngữ cảnh. Bằng cách giữ cho các phiên ngắn gọn, gộp nhóm các tác vụ, xác định chính xác các vị trí và chuyển đổi mô hình một cách linh hoạt, bạn có thể đạt được sự sụt giảm mạnh về chi phí mà không làm giảm chất lượng đầu ra. Đối với các nhà phát triển theo đuổi hiệu quả chi phí tối đa và bảo vệ quyền riêng tư, việc triển khai các mô hình cục bộ thông qua ServBay cũng là một giải pháp thay thế tuyệt vời.
All rights reserved
