[New Idea] - Data Free Model Pruning with Genetic Algorithm
Bài đăng này đã không được cập nhật trong 4 năm
Phương pháp pruning model hiện tại
Các phương pháp model pruning hiện tại được sinh ra với mục đích giảm kích thước của model bằng cách loại bỏ đi các trọng số không quan trọng trong mạng:
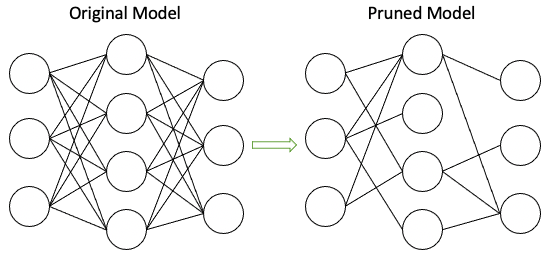
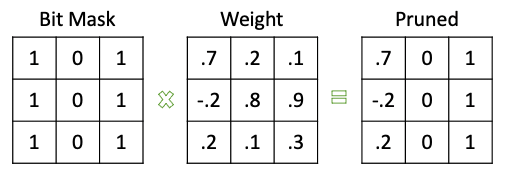
Chiến lược để pruning trong các phương pháp hiện tại như sau:
- Sử dụng một binary bitmask cho mỗi layer (chứa giá trị 0 nếu các weight tương ứng không được sử dụng trong quá trình forward)
- Huấn luyện một model lớn với độ chính xác đủ tốt trên orignal dataset
- Chọn ra các weight không quan trọng bằng một thuật toán cụ thể (ví dụ đơn giản có thể chọn theo threshold hoặc theo sparsity của mạng)
- Finetune lại mạng mới (với chỉ các weight được giữ lại) trên original dataset
Tham khảo: To prune, or not to prune: exploring the efficacy of pruning for model compression
Vấn đề phát sinh trong thực tế
- Đôi khi chúng ta muốn pruning một pretrained model nhưng không thể truy cập vào dataset gốc
- Dataset gốc quá lớn khiến cho việc finetuning khó khăn (ví dụ như Imagenet chẳng hạn)
- Vấn đề đặt ra là Liệu có thể thực hiện pruning trực tiếp từ pre-trained model mà không cần đến dataset gốc hay không?
Ý tưởng ban đầu
- Thay vì tự định nghĩa sub-mask các weight không quan trọng thì sẽ tự học các sub-mask đó
- Thay vì fine-tuning lại các weight thì không fine-tuning nữa mà giữ nguyên các weight của pre-trained model thay vào đó sẽ đi tìm các kết nối giữa các weight (hay sub-network)
- Không sử dụng tập dữ liệu ban đầu nên có thể không cần tiếp cận theo gradient-based mà sử dụng các thuật toán evolution để tìm kiếm sub-network
Thực hiện thuật toán
Thuật toán sẽ có các bước chính như sau:
- Xuất phát từ một pre-trained
- Xây dựng một model có kiến trúc giống pre-trained model nhưng có thêm một lớp scores mask cho mỗi layer
- Lớp scores mask sẽ lưu điểm của mỗi weight cho từng layer. Việc lựa chọn các weight sẽ được sử dụng trong scores mask đơn giản là lựa chọn top k% các score trên từng layer
- Sử dụng GA để khởi tạo một population ban đầu gồm nhiều score khác nhau.
- Tiến hành chạy GA để learning ra các scores mask
Code thử
Xây dựng pre-trained model
Thử với tập MNIST có accuracy 98% làm pre-trained model. Xây dựng một mô hình CNN đơn giản
- Import modules cần thiết
import os
import math
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import CosineAnnealingLR
import torch.autograd as autograd
- Định nghĩa device
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
- Định nghĩa kiến trúc mạng
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1, bias=False)
self.conv2 = nn.Conv2d(32, 64, 3, 1, bias=False)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128, bias=False)
self.fc2 = nn.Linear(128, 10, bias=False)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
- Load pre-trained model
model = Net().to(device)
model.load_state_dict(torch.load('mnist_cnn.pt'))
- Lưu các module_list và weight tương ứng để lát nữa copy sang mạng mới
module_list = [module for module in model.modules() if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear)]
module_shape = [m.weight.shape for m in module_list]
original_weights = [m.weight for m in module_list]
Xây dựng mạng mới với sub-mask
Xây dựng phần GetSubmassk tính toán trên top k%.
class GetSubnet(autograd.Function):
@staticmethod
def forward(ctx, scores, k):
# Get the supermask by sorting the scores and using the top k%
out = scores.clone()
_, idx = scores.flatten().sort()
j = int((1 - k) * scores.numel())
# flat_out and out access the same memory.
flat_out = out.flatten()
flat_out[idx[:j]] = 0
flat_out[idx[j:]] = 1
return out
Xây dựng supermask cho layer convolution
class SupermaskConv(nn.Conv2d):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# initialize the scores
self.scores = nn.Parameter(torch.Tensor(self.weight.size()))
nn.init.kaiming_uniform_(self.scores, a=math.sqrt(5))
# NOTE: initialize the weights like this.
nn.init.kaiming_normal_(self.weight, mode="fan_in", nonlinearity="relu")
# NOTE: turn the gradient on the weights off
self.weight.requires_grad = False
self.scores.requires_grad = False
def forward(self, x):
subnet = GetSubnet.apply(self.scores.abs(), sparsity)
w = self.weight * subnet
x = F.conv2d(
x, w, self.bias, self.stride, self.padding, self.dilation, self.groups
)
return x
Xây dựng supermask cho layer Linear
class SupermaskLinear(nn.Linear):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# initialize the scores
self.scores = nn.Parameter(torch.Tensor(self.weight.size()))
nn.init.kaiming_uniform_(self.scores, a=math.sqrt(5))
# NOTE: initialize the weights like this.
nn.init.kaiming_normal_(self.weight, mode="fan_in", nonlinearity="relu")
# NOTE: turn the gradient on the weights off
self.weight.requires_grad = False
self.scores.requires_grad = False
def forward(self, x):
subnet = GetSubnet.apply(self.scores.abs(), sparsity)
w = self.weight * subnet
return F.linear(x, w, self.bias)
Định nghĩa mạng mới tương đương với mạng pre-trained nhưng với các layer super mask
class GANet(nn.Module):
def __init__(self):
super(GANet, self).__init__()
self.conv1 = SupermaskConv(1, 32, 3, 1, bias=False)
self.conv2 = SupermaskConv(32, 64, 3, 1, bias=False)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = SupermaskLinear(9216, 128, bias=False)
self.fc2 = SupermaskLinear(128, 10, bias=False)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
Tiến hành copy weight của pre-trained model vào model mới
ga_model = GANet().to(device)
ga_module_list = [module for module in ga_model.modules() if isinstance(module, SupermaskConv) or isinstance(module, SupermaskLinear)]
# Update weight of ga model with original trained model
for i, weight in enumerate(original_weights):
ga_module_list[i].weight = weight
Xây dựng thuật toán GA
Build Agent
class Agent:
def __init__(self, params):
self.params = params
self.fitness = 0
def set_fitness(self, fitness):
self.fitness = fitness
Khởi tạo quần thể
# Init population
def init_pop(pop_size=100):
population = []
for _ in range(pop_size):
params = []
for shape in module_shape:
scores = nn.Parameter(torch.Tensor(shape))
nn.init.kaiming_uniform_(scores, a=math.sqrt(5))
params.append(scores)
agent = Agent(params=params)
population.append(agent)
return population
Update scores từng agent cho ga_model
def change_scores(module_list, agent):
for i, m_scores in enumerate(agent.params):
module_list[i].scores = m_scores
Đột biến
def mutation(agent, mut_rate=0.1):
params = []
for param in agent.params:
out = param.clone()
# flat_out and out share the same memory
flat_out = out.flatten().to(device)
# Get index mutation
indexes = np.where(np.random.uniform(low=0, high=1, size=(len(flat_out))) < mut_rate)
replace_values = np.random.uniform(low=-1, high=1, size=(len(flat_out)))[indexes]
# Mutation
flat_out.index_copy_(0, torch.LongTensor(indexes[0]).to(device), torch.FloatTensor(replace_values).to(device))
params.append(nn.Parameter(out))
return Agent(params=params)
Lai ghép - tái tổ hợp
def recombine_agent(agent_1, agent_2):
params_1 = []
params_2 = []
for i, param in enumerate(agent_1.params):
param_1 = param.clone()
param_2 = agent_2.params[i].clone()
# Flatten
flat_1 = param_1.flatten().to(device)
flat_2 = param_2.flatten().to(device)
# Define children
child_1 = torch.zeros(len(flat_1))
child_2 = torch.zeros(len(flat_1))
# Select cross point
cross_pt = random.randint(0, len(flat_1))
# Swap
child_1[cross_pt:len(flat_1)] = flat_1[cross_pt:len(flat_1)]
child_1[0:cross_pt] = flat_2[0:cross_pt]
child_2[cross_pt:len(flat_1)] = flat_2[cross_pt:len(flat_1)]
child_2[0:cross_pt] = flat_1[0:cross_pt]
# Append to params
params_1.append(nn.Parameter(child_1.reshape(module_shape[i])))
params_2.append(nn.Parameter(child_2.reshape(module_shape[i])))
return Agent(params_1), Agent(params_2)
Đánh giá quần thể
from tqdm import tqdm
def evaluate_population(pop):
avg_fit = 0
for agent in tqdm(pop):
change_scores(ga_module_list, agent)
fit = test(ga_model.to(device), device)
agent.fitness = fit
avg_fit += fit
avg_fit /= len(pop)
return pop, avg_fit
Next generation
def next_generation(pop, size=100, mut_rate=0.01):
new_pop = []
while len(new_pop) < size:
parents = random.choices(pop, k=2, weights=[x.fitness for x in pop])
offspring_ = recombine_agent(parents[0],parents[1])
offspring = [mutation(offspring_[0], mut_rate=mut_rate), mutation(offspring_[1], mut_rate=mut_rate)]
new_pop.extend(offspring) #add offspring to next generation
return new_pop
Định nghĩa data test
Do không sử dụng tập train nên chỉ cần load data test để đánh giá
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(
os.path.join("./data", "mnist"),
train=False,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
),
batch_size=10000,
shuffle=True
)
Xây dựng hàm test
def test(model, device):
model.eval()
with torch.no_grad():
output = model(test_data)
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct = pred.eq(test_target.view_as(pred)).sum().item()
out = correct / len(test_data)
return out
Hyperparams
batch_size = 1024
momentum = 0.9
wd = 0.0005
lr = 0.01
epochs = 20
sparsity = 0.3
log_interval = 1000
seed = 1507
Huấn luyện
num_generations = 10000
population_size = 100
pop = init_pop(population_size)
mutation_rate = 0.1 # 0.1% mutation rate
pop_fit = []
pop = init_pop(population_size) #initial population
for gen in range(num_generations):
# trainning
pop, avg_fit = evaluate_population(pop)
print('Generation {} with pop_fit {}'.format(gen, avg_fit))
pop_fit.append(avg_fit) #record population average fitness
new_pop = next_generation(pop, size=population_size, mut_rate=mutation_rate)
pop = new_pop
Một vài kết quả
100%|██████████| 100/100 [00:05<00:00, 18.65it/s]
Generation 0 with pop_fit 0.49528699999999987
100%|██████████| 100/100 [00:05<00:00, 19.14it/s]
Generation 1 with pop_fit 0.5210469999999999
100%|██████████| 100/100 [00:05<00:00, 19.04it/s]
Generation 2 with pop_fit 0.554441
100%|██████████| 100/100 [00:05<00:00, 19.19it/s]
Generation 3 with pop_fit 0.550083
100%|██████████| 100/100 [00:05<00:00, 19.06it/s]
Generation 4 with pop_fit 0.5807529999999997
100%|██████████| 100/100 [00:05<00:00, 18.60it/s]
Generation 5 with pop_fit 0.5960270000000002
100%|██████████| 100/100 [00:05<00:00, 19.20it/s]
Generation 6 with pop_fit 0.6354899999999999
100%|██████████| 100/100 [00:05<00:00, 18.87it/s]
Generation 7 with pop_fit 0.6630680000000001
100%|██████████| 100/100 [00:05<00:00, 18.96it/s]
Generation 8 with pop_fit 0.6598939999999999
100%|██████████| 100/100 [00:05<00:00, 19.11it/s]
Generation 9 with pop_fit 0.6729839999999999
100%|██████████| 100/100 [00:05<00:00, 18.28it/s]
Generation 10 with pop_fit 0.6746130000000001
100%|██████████| 100/100 [00:05<00:00, 19.19it/s]
Generation 11 with pop_fit 0.6668120000000001
100%|██████████| 100/100 [00:05<00:00, 19.05it/s]
Generation 12 with pop_fit 0.6691490000000002
100%|██████████| 100/100 [00:05<00:00, 18.85it/s]
Generation 13 with pop_fit 0.6474719999999999
100%|██████████| 100/100 [00:05<00:00, 19.12it/s]
Generation 14 with pop_fit 0.6627349999999999
100%|██████████| 100/100 [00:05<00:00, 18.79it/s]
Generation 15 with pop_fit 0.6822900000000003
100%|██████████| 100/100 [00:05<00:00, 18.74it/s]
Generation 16 with pop_fit 0.6807899999999999
100%|██████████| 100/100 [00:05<00:00, 19.00it/s]
Generation 17 with pop_fit 0.7026549999999999
100%|██████████| 100/100 [00:05<00:00, 18.45it/s]
Generation 18 with pop_fit 0.6868509999999998
100%|██████████| 100/100 [00:05<00:00, 19.11it/s]
Generation 19 with pop_fit 0.7088399999999999
100%|██████████| 100/100 [00:05<00:00, 18.90it/s]
Generation 20 with pop_fit 0.7220369999999999
100%|██████████| 100/100 [00:05<00:00, 19.04it/s]
Generation 21 with pop_fit 0.713581
100%|██████████| 100/100 [00:05<00:00, 19.00it/s]
Generation 22 with pop_fit 0.7366479999999997
100%|██████████| 100/100 [00:05<00:00, 19.00it/s]
Generation 23 with pop_fit 0.7478739999999998
100%|██████████| 100/100 [00:05<00:00, 18.96it/s]
Generation 24 with pop_fit 0.7208869999999997
100%|██████████| 100/100 [00:05<00:00, 19.06it/s]
Generation 25 with pop_fit 0.7302569999999998
100%|██████████| 100/100 [00:05<00:00, 18.97it/s]
Generation 26 with pop_fit 0.7252170000000003
100%|██████████| 100/100 [00:05<00:00, 18.76it/s]
Generation 27 with pop_fit 0.7199049999999997
100%|██████████| 100/100 [00:05<00:00, 19.07it/s]
Generation 28 with pop_fit 0.730054
100%|██████████| 100/100 [00:05<00:00, 18.33it/s]
Generation 29 with pop_fit 0.738942
100%|██████████| 100/100 [00:05<00:00, 18.94it/s]
Generation 30 with pop_fit 0.7318150000000001
100%|██████████| 100/100 [00:05<00:00, 19.08it/s]
Generation 31 with pop_fit 0.7219880000000001
100%|██████████| 100/100 [00:05<00:00, 18.45it/s]
Generation 32 with pop_fit 0.7238969999999999
100%|██████████| 100/100 [00:05<00:00, 19.07it/s]
Generation 33 with pop_fit 0.7283080000000001
100%|██████████| 100/100 [00:05<00:00, 18.71it/s]
Generation 34 with pop_fit 0.71085
100%|██████████| 100/100 [00:05<00:00, 19.10it/s]
Generation 35 with pop_fit 0.7257509999999999
100%|██████████| 100/100 [00:05<00:00, 19.06it/s]
Generation 36 with pop_fit 0.726268
100%|██████████| 100/100 [00:05<00:00, 17.18it/s]
Generation 37 with pop_fit 0.7375379999999998
100%|██████████| 100/100 [00:05<00:00, 19.07it/s]
Generation 38 with pop_fit 0.7513240000000004
100%|██████████| 100/100 [00:05<00:00, 18.53it/s]
Generation 39 with pop_fit 0.7483460000000001
100%|██████████| 100/100 [00:05<00:00, 19.11it/s]
Generation 40 with pop_fit 0.7527380000000001
100%|██████████| 100/100 [00:05<00:00, 18.99it/s]
Generation 41 with pop_fit 0.7640440000000001
100%|██████████| 100/100 [00:05<00:00, 18.77it/s]
Generation 42 with pop_fit 0.7598250000000002
100%|██████████| 100/100 [00:05<00:00, 19.01it/s]
Generation 43 with pop_fit 0.7414619999999998
100%|██████████| 100/100 [00:05<00:00, 18.78it/s]
Generation 44 with pop_fit 0.7588380000000001
100%|██████████| 100/100 [00:05<00:00, 19.01it/s]
Generation 45 with pop_fit 0.7678069999999999
100%|██████████| 100/100 [00:05<00:00, 17.95it/s]
Generation 46 with pop_fit 0.7691239999999996
100%|██████████| 100/100 [00:05<00:00, 17.38it/s]
Generation 47 with pop_fit 0.793402
100%|██████████| 100/100 [00:05<00:00, 18.59it/s]
Generation 48 with pop_fit 0.7898880000000004
100%|██████████| 100/100 [00:05<00:00, 17.82it/s]
Generation 49 with pop_fit 0.7741570000000004
100%|██████████| 100/100 [00:05<00:00, 18.31it/s]
Generation 50 with pop_fit 0.780985
100%|██████████| 100/100 [00:05<00:00, 18.55it/s]
Generation 51 with pop_fit 0.781711
100%|██████████| 100/100 [00:05<00:00, 18.78it/s]
Generation 52 with pop_fit 0.7949269999999999
100%|██████████| 100/100 [00:05<00:00, 19.02it/s]
Generation 53 with pop_fit 0.790513
100%|██████████| 100/100 [00:05<00:00, 18.21it/s]
Generation 54 with pop_fit 0.779757
100%|██████████| 100/100 [00:05<00:00, 18.11it/s]
Generation 55 with pop_fit 0.7727679999999999
100%|██████████| 100/100 [00:05<00:00, 18.93it/s]
Generation 56 with pop_fit 0.7883189999999998
100%|██████████| 100/100 [00:05<00:00, 19.09it/s]
Generation 57 with pop_fit 0.791412
100%|██████████| 100/100 [00:05<00:00, 18.74it/s]
Generation 58 with pop_fit 0.794981
100%|██████████| 100/100 [00:05<00:00, 18.28it/s]
Generation 59 with pop_fit 0.7836850000000003
100%|██████████| 100/100 [00:05<00:00, 18.66it/s]
Generation 60 with pop_fit 0.7869880000000002
100%|██████████| 100/100 [00:05<00:00, 19.13it/s]
Generation 61 with pop_fit 0.793687
100%|██████████| 100/100 [00:05<00:00, 18.90it/s]
Generation 62 with pop_fit 0.7843660000000001
100%|██████████| 100/100 [00:05<00:00, 18.26it/s]
Generation 63 with pop_fit 0.7861880000000006
100%|██████████| 100/100 [00:05<00:00, 18.99it/s]
Generation 64 with pop_fit 0.7954170000000002
100%|██████████| 100/100 [00:05<00:00, 18.70it/s]
Generation 65 with pop_fit 0.807838
100%|██████████| 100/100 [00:05<00:00, 19.09it/s]
Generation 66 with pop_fit 0.8058349999999997
100%|██████████| 100/100 [00:05<00:00, 17.87it/s]
Generation 67 with pop_fit 0.812714
100%|██████████| 100/100 [00:05<00:00, 18.62it/s]
Generation 68 with pop_fit 0.8091359999999999
100%|██████████| 100/100 [00:05<00:00, 18.19it/s]
Generation 69 with pop_fit 0.8095650000000002
100%|██████████| 100/100 [00:05<00:00, 19.25it/s]
Generation 70 with pop_fit 0.8086880000000002
100%|██████████| 100/100 [00:05<00:00, 17.88it/s]
Generation 71 with pop_fit 0.8138010000000002
100%|██████████| 100/100 [00:05<00:00, 18.97it/s]
Generation 72 with pop_fit 0.8169339999999998
100%|██████████| 100/100 [00:05<00:00, 18.20it/s]
Generation 73 with pop_fit 0.8242490000000001
100%|██████████| 100/100 [00:05<00:00, 19.17it/s]
Generation 74 with pop_fit 0.8266410000000001
100%|██████████| 100/100 [00:05<00:00, 19.12it/s]
Generation 75 with pop_fit 0.8304610000000002
100%|██████████| 100/100 [00:05<00:00, 19.22it/s]
Generation 76 with pop_fit 0.8254399999999997
100%|██████████| 100/100 [00:05<00:00, 19.07it/s]
Generation 77 with pop_fit 0.8176640000000001
100%|██████████| 100/100 [00:05<00:00, 19.21it/s]
Generation 78 with pop_fit 0.8264109999999996
100%|██████████| 100/100 [00:05<00:00, 19.32it/s]
Generation 79 with pop_fit 0.8273800000000001
100%|██████████| 100/100 [00:05<00:00, 19.27it/s]
Generation 80 with pop_fit 0.83148
100%|██████████| 100/100 [00:05<00:00, 17.61it/s]
Generation 81 with pop_fit 0.8278819999999999
100%|██████████| 100/100 [00:05<00:00, 18.97it/s]
Generation 82 with pop_fit 0.826982
100%|██████████| 100/100 [00:05<00:00, 18.91it/s]
Generation 83 with pop_fit 0.8198989999999998
100%|██████████| 100/100 [00:05<00:00, 19.11it/s]
Generation 84 with pop_fit 0.8339390000000002
100%|██████████| 100/100 [00:05<00:00, 18.41it/s]
Generation 85 with pop_fit 0.8264149999999997
100%|██████████| 100/100 [00:05<00:00, 17.95it/s]
Generation 86 with pop_fit 0.8333849999999999
100%|██████████| 100/100 [00:05<00:00, 17.06it/s]
........
100%|██████████| 100/100 [00:05<00:00, 18.24it/s]
Generation 337 with pop_fit 0.8917819999999995
100%|██████████| 100/100 [00:05<00:00, 18.97it/s]
Generation 338 with pop_fit 0.8906439999999998
100%|██████████| 100/100 [00:05<00:00, 19.03it/s]
Generation 339 with pop_fit 0.8893889999999998
100%|██████████| 100/100 [00:05<00:00, 19.16it/s]
Generation 340 with pop_fit 0.8890430000000005
100%|██████████| 100/100 [00:05<00:00, 19.13it/s]
Generation 341 with pop_fit 0.8893149999999999
100%|██████████| 100/100 [00:05<00:00, 18.87it/s]
Generation 342 with pop_fit 0.8903490000000001
All rights reserved
