MySQL Fulltext Search
Bài đăng này đã không được cập nhật trong 7 năm
Có lẽ chủ đề này đã có quá nhiều bài viết trên viblo và những kênh khác nhưng mình vẫn mạnh dạn trình bày lại những gì mình đã tìm hiểu và thu thập được trong quá trình chuẩn bị present khi còn ở EDU.
I. Đặt vấn đề
Vấn đề 1
Giả sử ta có 1 bảng dữ liệu như sau
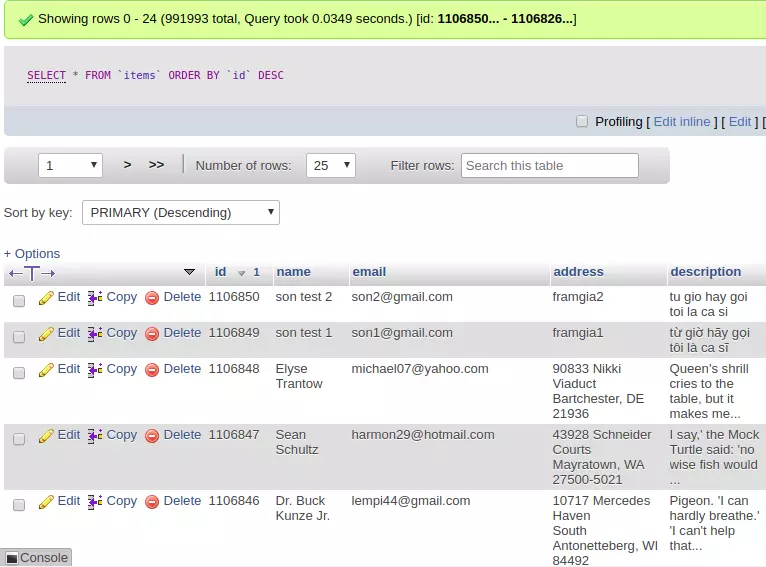
Gỉa sử bây giờ chúng ta muốn tìm 2000 items có description bắt đầu bằng từ Queen.
Và chắc chắn đây là câu lệnh quen thuộc mà chúng ta thường sử dụng SELECT * FROM items WHERE description LIKE 'Queen%' LIMIT 2000 . Khoan hãy xem kết quả, chúng ta hay xem hiệu năng của câu lệnh mang lại bằng việc thêm từ khóa EXPLAIN vào trước câu lệnh trên. Sẽ mang lại cho ta kết quả như sau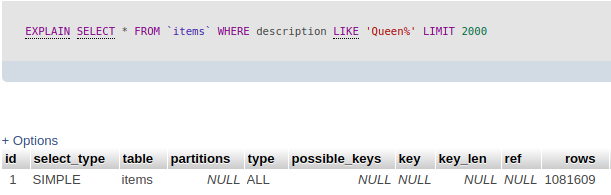 Về cơ bản khi bạn nhìn vào bảng dữ liệu này thì hãy chú ý một vài cột như:
Về cơ bản khi bạn nhìn vào bảng dữ liệu này thì hãy chú ý một vài cột như:
- Type: All (Sau khi thực hiện câu lệnh MySQL sẽ duyệt qua toàn bộ bản ghi để lấy ra dữ liệu - thể hiện ở cột rows MySQL đã quét hơn 1M data, nếu trong table có 10M, 100M thì thật là...thất bại)
- Còn một vài trường như
- table : Table liên quan đến output data.
- type : Mức độ từ tốt nhất đến chậm nhất như sau: system, const, eq_ref, ref, range, index, all
- possible_keys : Đưa ra những Index có thể sử dụng để query
- key : và Index nào đang được sử dụng
- key_len : Chiều dài của từng mục trong Index
- ref : Cột nào đang sử dụng Bạn có thể tham khảo thêm tại đây
Vấn đề 2
Trong bản ghi có 1 câu như thế này, giả sử bạn không thể nhớ hết được cả câu này, mà chỉ nhớ được 3 từ thôi. thì ta sẽ làm thế nào để tìm được các bản ghi đó? Nếu sử dụng câu lệnh như lúc đầu thì nó có chạy được hay không?
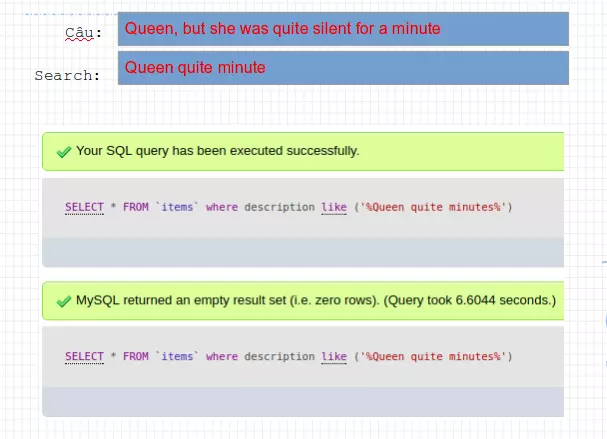
Rõ rang là Không. Và còn rất nhiều mặt hạn chế của Search cổ truyền. Vậy tổng kết lại ta được một list hạn chế như sau:
- Tốc độ chậm.
- Không tìm được từ đồng nghĩa
- Không tìm được các từ viết tắt phổ biến như: Trung Học Phổ Thông (THPT)
- Không tìm được tìm kiếm cách từ như ví dụ trên.
- Không search được do lỗi chính tả...
Vậy để hạn chế các vấn đề trên, MySQL đã hỗ trợ thêm cho chúng ta
MySQL Fulltext Search.
II. MySQL Fulltext Search
Full text searchlà kĩ thuật tìm kiếm toàn văn cho phép người dùng tìm kiếm các mẩu thông tin khớp với một chuỗi trên một hay một số cột nhất định- Một chỉ mục toàn văn trong MySQL là một chỉ mục có kiểu FULLTEXT. Các chỉ mục FULLTEXT chỉ được dùng với các bảng có thể được tạo ra từ các cột CHAR, VARCHAR, hay TEXT.
- Sử dụng cơ chế ranking (ranking dựa trên mức độ phù hợp của kết tài liệu tìm thấy, tài liệu trả về càng phù hợp thì có số rank càng cao)
2.1 Inverted Index
Điều làm nên sự khác biệt giữa FTS và các kĩ thuật search thông thường chính là Inverted index.
- là kĩ thuật đánh index theo đơn vị term
- nhằm mục đich map giữa các term với các bản ghi chưa term đó.
- Vậy việc tạo index theo term như trên có lợi thế nào?
Hãy giả sử bạn muốn query cụm từ "Son, is, Developer", thì thay vì việc phải scan từng document một, bài toán tìm kiếm document chứa 3 term trên sẽ trở thành phép toán union của 3 tập hợp
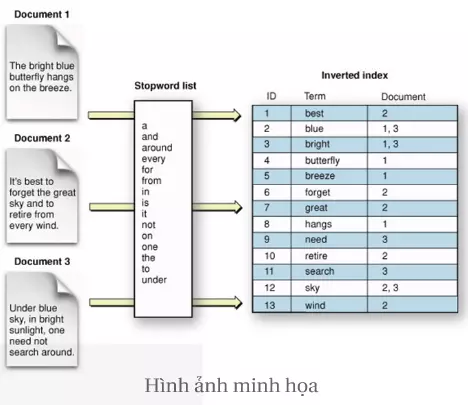
Ví dụ:
D1 = "Son is Developer"
D2 = "Developer PHP"
D3 = "Son is Developer and Student"
Inverted Index:
"Son" => {D1,D3}
"is" => {D1, D3}
"Developer" => {D1, D2, D3}
"PHP" => {D2}
"and" => {D3}
"Student" => {D3}
Query cụm “Son, is, Developer” thì ta sẽ có biểu thức union:
{D1,D3} union {D1,D3} union {D1, D2 ,D3} = {D1}
=> việc tìm kiếm trở nên nhanh hơn nhiều thay vì việc phải scan toàn bộ table để tìm ra tài liệu có chứa từ đó
- Thực hiện FTS
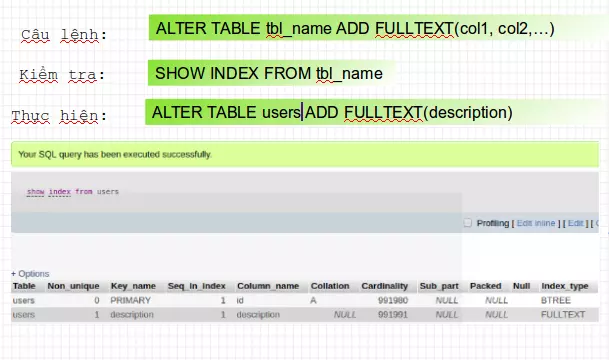
- Để thực hiện được FTS chúng ta cần lưu ý về cách đánh chỉ mục Fulltext:
- Nếu đánh chỉ mục cho 2 cột thì khi search chúng ta cũng phải điền cả 2 cột
- Thư tự đánh thế nào thì thứ tự search cũng phải vậy.
- Lưu ý: Fulltext là trường hợp đặc biệt của đánh index trong bảng
Ví dụ như sau
2.2 IN NATURAL LANGUAGE MODE(mặc định)
- Chế độ sort mặc định theo mức độ phù hợp (relevance rank)
- Công thức tính điểm cho mức độ phù hợp
- Được tính theo công thức:
w = (log(dtf)+1)/sumdtf * U/(1+0.0115*U) log((N-nf)/nf)(tất nhiên các bạn không cần quan tâm công thức loằng ngoằng này vì MySQL đã làm hết cho ta thông qua những câu lệnh)
Giải thích về công thức như sau: Nếu 1 tư khóa xuất hiện nhiều lần trong 1 bản ghi thì điểm weight của từ khóa đó sẽ tăng lên và ngược lại nếu từ khóa xuất hiện trong nhiều bản ghi thì điểm weight sẽ bị giảm đi.
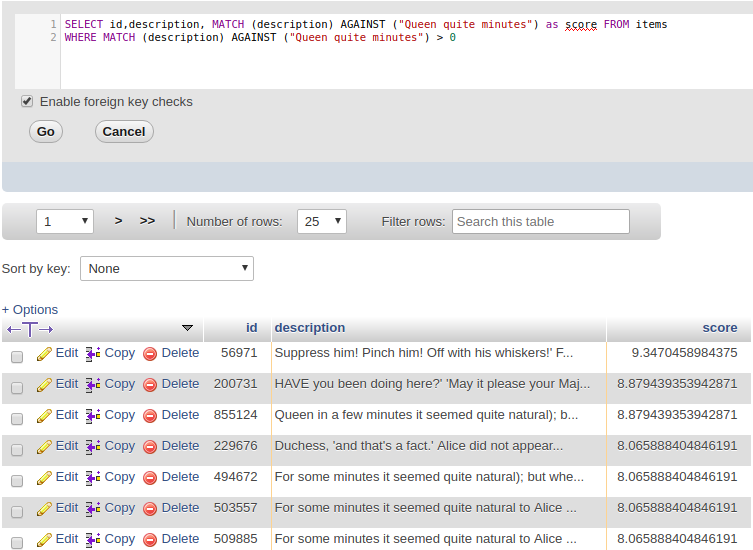 Với câu lệnh như trên: MATCH…AGAINST sẽ trả về điểm ranking dạng số thực dựa trên mức độ phù hợp của kết quả tìm thấy, kết quả trả về càng phù hợp thì có số rank càng cao
Với câu lệnh như trên: MATCH…AGAINST sẽ trả về điểm ranking dạng số thực dựa trên mức độ phù hợp của kết quả tìm thấy, kết quả trả về càng phù hợp thì có số rank càng cao
- Bạn còn nhớ câu search cách từ với kiểu
search cổ truyềnlúc đầu chứ?
Giờ ta sẽ so sánh với FTS nhé?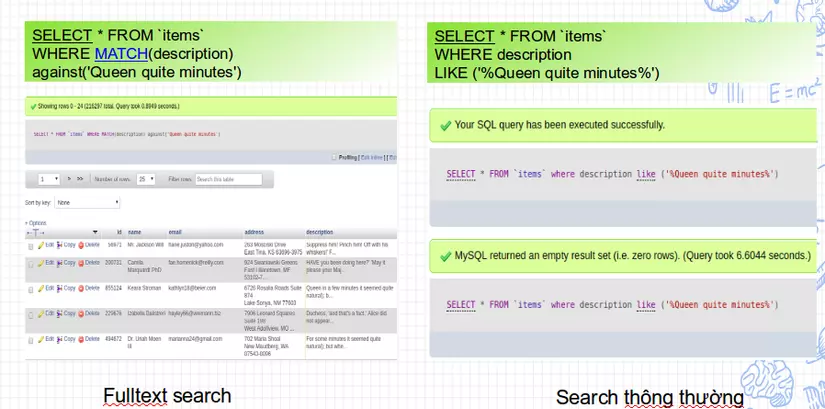 => Passed
=> Passed
2.3 IN BOOLEAN MODE
- Search theo từ khóa tìm kiếm
- Dùng toán từ ‘+’ hoặc ‘-’ để quyết định từ nào sẽ được trả về kết quả.
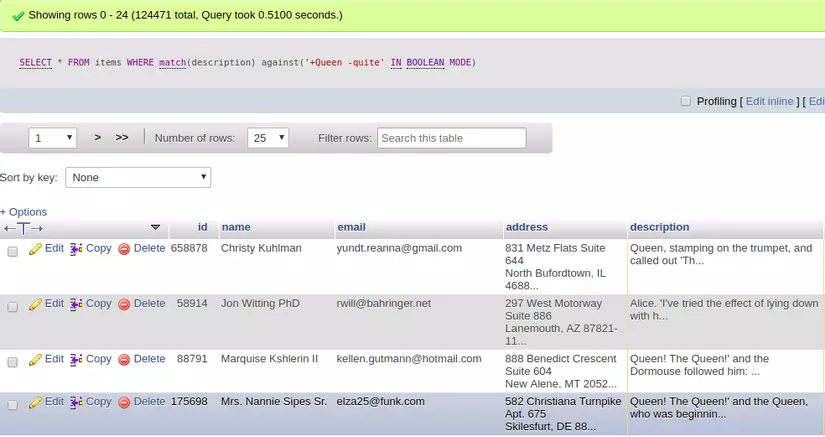 Và đây là danh sách các cách sử dụng wilcard của IBM trong FTS
Và đây là danh sách các cách sử dụng wilcard của IBM trong FTS

2.4 Query Expansion
Theo mình chế độ này có lẽ là những điểm hay nhất nhưng cũng là hạn chế (hạn chế bởi vì nó chưa thể hiên thực sự hết khả năng của nó đáng ra phải mang lại trong quá trình mình tìm hiểu)
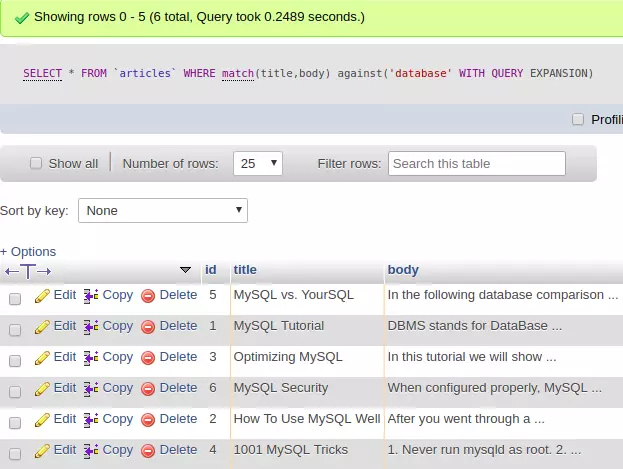
- MySQL sẽ thực hiện search 2 lần, trong lần search thứ 2 MySQL sẽ tìm kết hợp cụm từ tìm kiếm gốc với những từ thích hợp nổi bật so với từ khóa gốc. Mặt khác đây chính là cái hay nhất trong fulltext search
- Tìm được từ đồng nghĩa
- Tìm được từ viết tắt
- Sửa lỗi chính tả
- đánh lại trọng số weight
- Để so sánh với mức độ lợi hại của Query Expansion thì mình có tìm hiểu về SQLServer thì thấy có 2 hàm của SQLServer là Hàm CONTAINS và Hàm FREETEXT mang lại giá trị tương đối cao với các giá trị trả về sát với định nghĩa về FTS. các bạn có thể tim hiểu thêm tại đây
Phần cuối: Mở rộng
- Lỡ tìm hiểu về đánh index đặc biệt là fulltext rồi chẳng nhẽ ta không đi tiếp đến đánh index bình thường?
- Đó là đánh index kiểu B-tree, về định nghĩa thì nghe hơi loằng ngoằng thế này
B-Tree là cậy tự cân bằng (self-balancing), nghĩa là khi thêm hoặc xoá 1 node thì cây sẽ có những action để đảm bảo chiều cao của cây càng thấp càng tốt. Mỗi node cha có giá trị lớn hơn node con này và nhỏ hơn node con khác. Nó sẽ tìm con trỏ bên phải bằng cách nhìn vào dữ liệu ở node pages, các node page có chứa dữ liệu của các node con. Bạn có thể xem qua ảnh gif mà mình sưu tầm được, nó rất là hay.
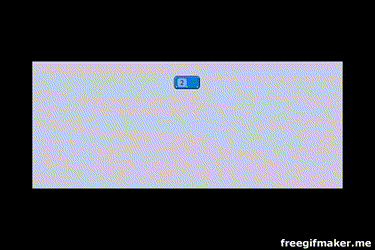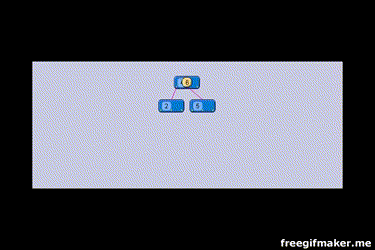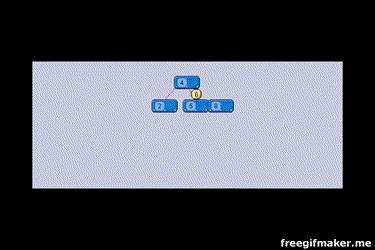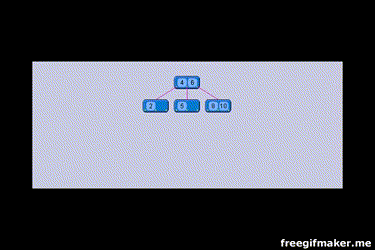
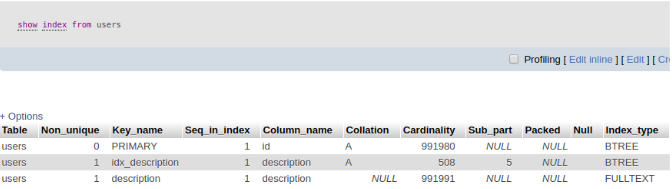
Cách đánh index như sau ALTER TABLE users ADD INDEX idx_description(description(5))
và sau đó cũng sử dụng SHOW INDEX FROM TABLE để kiểm tra và ta được kết quả sau.
Giờ ta sẽ lại so sánh với câu search like lúc ban đầu và so sánh về tốc độ cũng như hiệu năng của câu lệnh sau khi được đánh index.
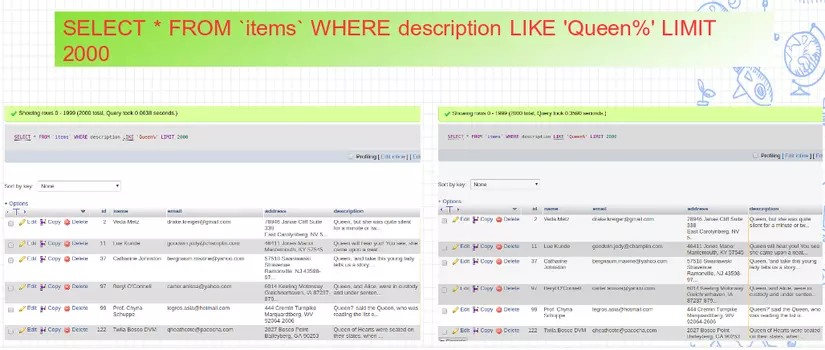 Hiệu năng
Hiệu năng

Chú ý :
- Các chỉ mục không nên được sử dụng trong các bảng nhỏ.
- Các chỉ mục không nên được sử dụng trên các cột mà chứa một số lượng lớn giá trị NULL.
- Không nên dùng chỉ mục trên các cột mà thường xuyên bị sửa đổi (Insert, Update…)
Tổng kết
- Đây là phân trình bày chi tiết và dễ thực hiện nhất để các bạn có thẻ nắm được phần nào về FTS cũng như là cách đánh index. Rõ ràng hiện nay có rất nhiều package hỗ trợ tìm kiếm rất tốt như: algolia (tính phí), elasticsearch...nhưng việc tìm hiểu những điều cơ bản vẫn có gì đó hay ho hơn. Bài viết mang tính chất tham khảo. Mọi người có vấn đề gì cùng góp ý nhé. Cảm ơn mọi người.
All rights reserved
