Một số tips giảm chi phí khi sử dụng service S3 - Amazon
Bài đăng này đã không được cập nhật trong 5 năm
Chào mọi người, sau một số ngày được cho ăn cho học đàng hoàng  thì mình cũng cho vào đầu được một chút kiến thức
thì mình cũng cho vào đầu được một chút kiến thức  .
.
Vậy thì hôm này, mình muốn ngoi lên để chia sẻ về một số thứ mình học được, hi vọng sẽ giúp ích được cho mọi người.
Let's get it !!
Trong bài viết này của mình, chúng ta sẽ cùng bàn luận về những cách để làm giảm chi phí khi sử dụng S3 của Amazon.
Đầu tiên, hãy cùng xem xét các yếu tố ảnh hưởng đến chi phí sử dung hàng tháng mà bạn sẽ phải trả cho Amazon S3 :
- Kích thước của dữ liệu được lưu trữ mỗi tháng (GB).
- Yêu cầu và truy xuất dữ liệu (ví dụ: PUT, COPY, POST, LIST, GET, SELECT hoặc các request khác).
- Số lần chuyển đổi giữa các class khác nhau.
- Kích thước truy xuất dữ liệu và số lượng yêu cầu.
- Phí transfer dữ liệu.
Một trong những yếu tố quan trọng nhất mà chúng ta cần phải để ý về chi phí đó chính là các lớp lưu trữ. Mỗi class lưu trữ đều có một mức giá khác nhau, vì vẫy hãy chắc chắn rằng mình nhớ và hiểu các lớp lữu trữ cũng như các trường hợp sử dụng của chúng. Cùng điểm qua một chút nhé :
Amazon S3 cung cấp cho người dùng 5 lớp lưu trữ khác nhau :
- S3 Standard
- S3 Intelligent - Tiering
- S3 Standard - Infrequent Access
- S3 One Zone - Infrequent Access
- S3 Glacier
- S3 Glacier Deep Archive
Mỗi một S3 object đều có thể được assigned với một class, chính vì vậy trong một buckket, chúng ta có thể thấy đồng thời có nhiều objects với lớp tương ứng của chúng.
Vì mình học trên Linux Academy được dạy ở region N.Virginia nên mình show luôn bảng giá hiện tại cho mọi người xem nhé :
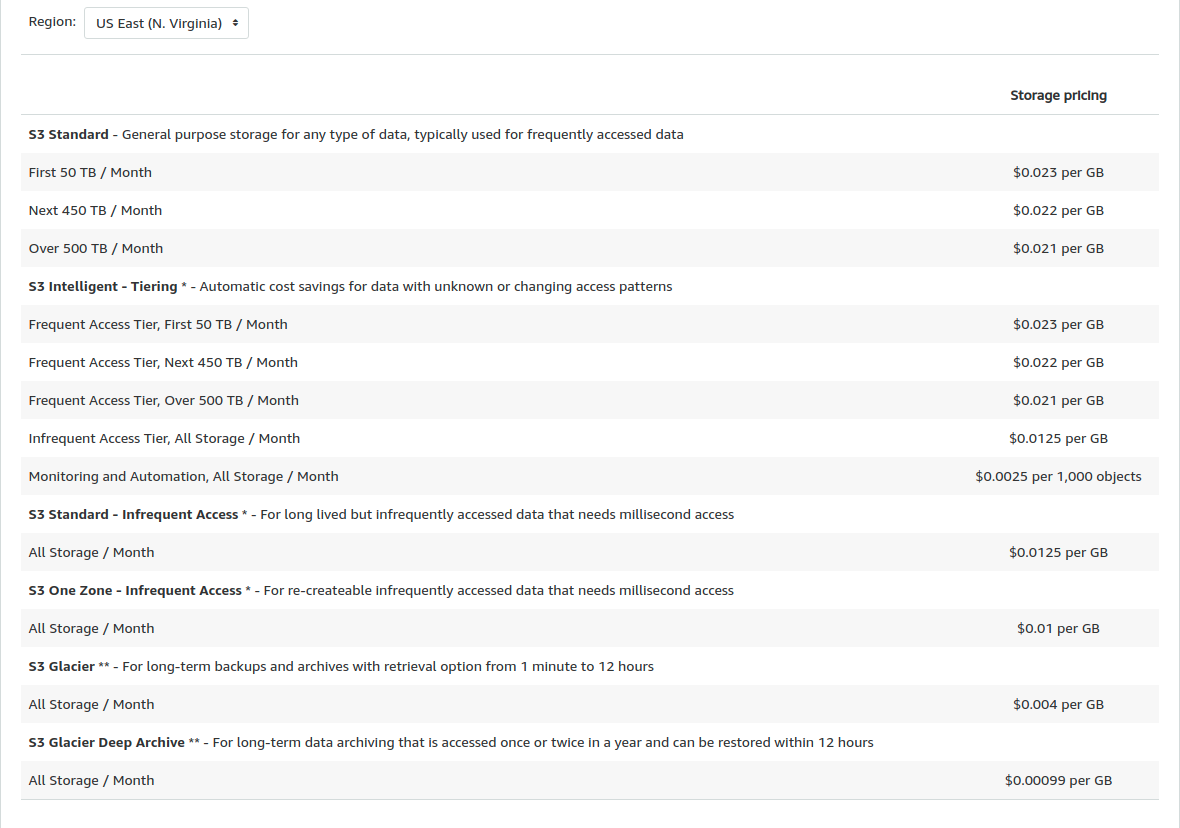
Lớp S3 Standard thường được sử dụng cho các dữ liệu được truy cập thường xuyên. Mặc dù chi phí cho mỗi Gb cao, nhưng không phải trả tiền cho số lượng các requets. Vì vậy lớp lưu trữ này phù hợp nhất cho các objects được đọc hoặc ghi nhiều lần mỗi tháng.
Lớp thứ ba trong bảng là S3 Standard-IA (S3 Standard - Infrequent Access) . Lớp này có giá lưu trữ thấp hơn, nhưng chi phí truy cập lại cao hơn. Theo AWS, nó dành cho dữ liệu lưu trữ lâu dài nhưng không thường xuyên được truy cập vào các dữ liệu cần truy cập tức thì .
S3 Standard-IA nên được sử dụng nếu object được truy cập trung bình ít hơn một lần/tháng. Tại sao ? Bởi vì đó là tần suất mà cả S3 Standard và S3 Standard-IA đều có chi phí chung tương đương nhau. Và đó cũng là khoảng thời gian tối thiểu được khuyến nghị để giữ các object ở lớp S3 Standard-IA. Nếu được giữ dưới 30 ngày, thì phần còn lại sẽ bị tính phí.
Thông thường, rất khó để biết tần suất được truy cập của object. AWS đã tạo S3 Intelligent-Tiering để giải quyết vấn đề này. Lớp này tự động di chuyển dữ liệu giữa các lớp S3 Standard và S3 Standard-IA. Và điều đó giảm thiểu chi phí của S3 cho object. Nếu một object đang được giữ hơn 30 ngày, lớp** S3 Intelligent-Tiering** sẽ rẻ hơn S3 Standard và S3 Standard-IA. Trong trường hợp này thì đây nên là lựa chọn đầu tiên của bạn.
Lớp S3 One Zone-IA tương tự như S3 Standard-IA. Tuy nhiên, thay vì lưu trữ dữ liệu trong 3 (hoặc nhiều) AZ (Availability Zone) , dữ liệu chỉ được lưu trữ trong một AZ. Chính vì vậy, dữ liệu có thể không có sẵn nếu truy cập đến AZ không thành công. Nên sử dụng S3 One Zone-IA nếu chấp nhận được rủi ro.
2 lớp cuối cùng trong bảng là S3 Glacier và S3 Glacier Deep Archive . Chúng có giá mỗi GB thấp nhất. Nhưng chi phí truy cập cao. Do đó chúng được sử dụng cho mục đích lưu trữ.
Các object trên Glacier không có sẵn ngay lập tức. Nếu muốn truy cập đến bất kỳ một nội dung của một object trong Glacier, chúng ta sẽ phải đợi cho đến khi quá trình truy xuất kết thúc. Đối với chế độ truy xuất hàng loạt, khoảng thời gian này có thể lên đến từ 5 đến 12 giờ. Với chế độ truy xuất khác, có thể nhanh hơn nhưng đắt hơn. Vì lý do này, Glacier chỉ nên được sử dụng cho các đối tượng hiếm khi được truy cập. Ví dụ: Glacier khá lý tưởng cho việc sao lưu, lưu trữ bất kỳ dữ liệu dài hạn nào không được truy cập thường xuyên .
Sự khác biệt giữa S3 Glacier và S3 Glacier Deep Archive là Deep Archive dành cho các object thậm chí còn được ít truy cập hơn. Ví dụ: Các object được truy cập 6 (hoặc hơn) tháng một lần. Chi phí lưu trữ của S3 Glacier Deep Archive thấp hơn. Object trong lớp này cần được lưu trữ ít nhất 180 ngày. Nếu không, khoảng thời gian tối thiểu đó sẽ bị tính phí.
Sơ sơ về các lớp là như vậy giờ mình đến phần lưu ý nhé :
1. Chọn đúng lớp khi khởi tạo object :
Bước đầu tiên của chúng ta chính là phân tích các kiểu truy cập cho dữ liệu. Chúng ta sẽ phải suy nghĩ về cách sử dụng dự định cho mỗi object mới sẽ được tạo trong S3. Mỗi object trong S3 phải có một mẫu truy cập cụ thể và có một lớp S3 phù hợp nhất với nó. Chúng ta không thể xác một định lớp mặc định cho mỗi nhóm trong S3 nhưng có thể gán nó cho mỗi object.
Khi xác định được lớp tốt nhất cho từng object mới trong S3, việc chúng ta cần làm là đặt lớp này trong khi upload object này lên Amazon S3. Có thể được thực hiện bằng AWS CLI, AWS Console hoặc AWS SDK. Do đó, mỗi object mới sẽ có đúng lớp. Đây có thể là cách tốt nhất để tiết kiệm chi phí và hiệu quả nhất về mặt thời gian.
2. Điều chỉnh lớp S3 hợp lí cho các object hiện có :
Bây giờ khi đã đặt đúng lớp cho các object mới (sẽ được tạo), chúng ta có thể tập trung vào các đối tượng đã được tạo. Quy trình tương tự như quy trình được mô tả ở phần 1. Bắt đầu với việc phân tích các mẫu truy cập dữ liệu cho object hiện có . Sau đó, quyết định lớp tốt nhất cho mỗi object. Và cuối cùng, gán lớp đó cho object. Điều này sẽ cho phép chúng ta tối ưu hóa mọi nhóm S3 và giảm chi phí sử dụng S3.
Làm thế nào để kiểm tra xem điều này đã hoạt động hay chưa ? Chúng ta có thể sử dụng AWS Cost Explorer để kiểm tra chi phí S3 hàng ngày. AWS hiển thị mức tiêu thụ cho từng dịch vụ, bao gồm cả Amazon S3.
Có chút lưu ý là có thể tốn nhiều thời gian để cập nhật mọi lớp cho object sau khi nó đã được tạo. Đó là lý do tại sao chúng ta phải xác định được các lớp trước khi các object được tạo. Tùy thuộc vào số lượng object mà bạn có, nó có thể là một khoảng thời gian đáng kể để thay đổi lướp cho object. Chúng ta nên tập trung vào các object lớn (hoặc được truy cập rất thường xuyên) để cập nhật các lớp lưu trữ của chúng trước.
Chúng ta cũng có thể sử dụng S3 Storage Class Analysis . Đây là một công cụ để phân tích các kiểu truy cập của các object S3. Nó giám sát các object trong một bucket, hiển thị lượng dữ liệu được lưu trữ trong nhóm, lượng dữ liệu được truy xuất và tần suất dữ liệu được truy cập. Lưu ý rằng chúng ta sẽ ohari trả một khoản phí nhỏ để sử dụng công cụ này. Nhưng ngược lại, chúng ta có thểbiết được rằng các object có được truy cập thường xuyên hay không. Sau khi bạn biết được các dữ liệu này, chúng ta có thể cập nhật lớp lưu trữ S3 cho phù hợp. Ví dụ: nếu bạn phát hiện ra rằng hầu hết các object trong một nhóm chỉ được truy cập một lần mỗi năm (và bạn không cần truy cập ngay lập tức), thì nên điều chỉnh lớp lưu trữ của các object này thành S3 Glacier Deep Archive.
3. Xóa các object S3 không sử dụng
Chúng ta phải trả tiền cho số lượng dữ liệu được lưu trữ trên S3. Vì vậy, nếu loại bỏ các object không sử dụng , chi phí cũng giảm đi đáng kể.
Vậy, làm cách nào để kiểm tra nội dung của nhóm S3 ?
Ví dụ: Chúng ta có thể liệt kê các objects trên mỗi nhóm. Thao tác này sẽ hiển thị tên object (hoặc khóa ) mà không cần tải xuống nội dung của object. Chúng ta có thể sử dụng AWS Console, AWS CLI hoặc SDK.
4. Sử dụng S3 Lifecycle :
Amazon S3 cung cấp một công cụ để tự động thay đổi lớp lưu trữ của bất kỳ object nào. Ví dụ: bạn có thể chuyển đổi từ lớp S3 Standard sang S3 Glacier sau một số ngày tạo object. Do đó bạn có thể chuyển từng object sang lớp lưu trữ phù hợp nhất. Điều này sẽ chuyển giúp giảm chi phí.
S3 Lifecycle hoạt động như thế nào? Chúng ta đặt quy tắc cho mỗi nhóm. Mỗi quy tắc có một giai đoạn chuyển tiếp. Nó đếm số ngày kể từ khi object được tạo (hoặc xóa). Và sau khoảng thời gian này, quy tắc cũng chuyển lớp lưu trữ cho object . Lưu ý rằng chúng ta luôn có thể chuyển các object sang lớp lưu trữ lâu dài hơn nhưng không thể chuyển đổi sang lớp lưu trữ ngắn hạn.
Cũng có thể đặt quy tắc vòng đời cho toàn bộ nhóm hoặc dựa trên tiền tố. Vì vậy, chúng ta không cần phải chuyển đổi từng object của mình. S3 Lifecycle Management là một trong những công cụ hữu ích nhất để tiết kiệm chi phí trên S3.
5. Chú ý khi object s3 hết hạn :
Amazon S3 Lifecycle Management cũng có thể set chính sách hết hạn.Khi một object hết hạn, AWS sẽ tự động xóa.
Nếu bạn giữ các file logs (hoặc bất kỳ dữ liệu tạm thời nào khác) dưới dạng đối tượng S3, nên đặt thời hạn cho chúng. Chúng ta có thể set cácfile logs hết hạn sau 30 ngày kể từ ngày tạo, và chúng sẽ tự động bị xóa.
6. Nén các objects S3 :
Chúng ta nên nén bất kỳ object nào trước khi upload lên. Chỉ cần tạo một tệp nén (ví dụ: ZIP, GZIP ,...), tệp này sẽ có size nhỏ hơn tệp gốc. Sau đó upload tệp nén lên S3. Lượng dữ liệu được sử dụng trong S3 sẽ thấp hơn. Khi đó chi phí sử dugnj của Amazon S3 sẽ giảm xuống.
Lưu ý rằng, để xem file gốc, bạn sẽ phải tải xuống và giải nén nó. Nhưng bù lại chúng ta có thể tiết kiệm rất nhiều dung lượng trong S3.
7. Đóng gói các objects S3 :
Chúng ta cũng trả tiền cho số lượng hoạt động được thực hiện trong Amazon S3. Nếu bạn phải tải xuống nhiều đối tượng S3 đồng thời, bạn nên đóng gói chúng vào một đối tượng lớn (ví dụ: TAR, ZIP hoặc tương đương).
Một số lớp lưu trữ có phí dung lượng tối thiểu cho các đối tượng. Ví dụ: phí dung lượng tối thiểu cho mỗi đối tượng đối với S3 Standard-IA và S3 One Zone - Infrequent Access là 128KB, và mức phí tối thiểu cho dung lượng mỗi object cho các lớp S3 Glacier và S3 Glacier Deep Archive là 40 Kb.
Chính vì vậy một object nhỏ 1 KB (có lớp S3 Standard-IA) sẽ bị tính là 128 KB. Đóng gói nhiều tệp với nhau sẽ tận dụng được tối thiểu chi phí.
9. Giới hạn cho Object Versions:
Object Versions S3 là một công cụ rất hữu ích. Mỗi khi bạn thay đổi nội dung của một Object, AWS sẽ lưu trữ lại cả phiên bản trước của nó. Nhưng điều gì xảy ra nếu chúng ta có một Object 1 MB với 100 phiên bản, chúng ta sẽ phải trả cho 100 MB dung lượng lưu trữ.
Nhưng bạn có thể sử dụng lifecycle policies để tự động xóa các phiên bản trước đó sau một thời gian.
10. Sử dụng Bulk Retrieval Mode cho S3 Glacier :
Amazon S3 Glacier có 3 kiểu truy xuất:
S3 Glacier Deep Archive có 2 kiểu truy xuất:
Retrieval time : có nghĩa là S3 tạo một nội dung của object nhanh như thế nào. Chúng ta truy xuất các object càng nhanh thì chi phí cho hoạt động truy xuất càng tốn kém. Nếu có thể chờ đợi một vài giờ để truy xuất, chúng ta có thể tiết kiệm nhiều tiền hơn. Vì vậy, hãy cố gắng sử dụng Bulk Retrieval Mode nếu có thể.
- Thay đổi Region Một số Regions đắt hơn nhiều so với những Regions khác. Vì vậy giá cho các dịch vụ Amazon S3 cũng khác nhau. Vì vậy, chúng ta nên cân nhắc chuyển sang khu vực có giá thấp hơn.
Một yếu tố khác cần cân nhắc chính là chi phí truyền dữ liệu giữa các vùng AWS. Dữ liệu được gửi cùng khu vực thì miễn phí, nhưng việc gửi dữ liệu đến khu vực khác thì sẽ tính chi phí trên Gb nhé.
Tổng kết :
Trên đây là một số các tip nhỏ để giảm chi phí sử dụng services S3 của Amazon.
Nếu mọi người thấy bài viết này hay thì hãy Upvote, Like và Share để mình có thêm động lực làm nhiều bài viết khác nhó.
Many thanksssss
All rights reserved
