Một số biểu thức regex không căn bản (nhưng hữu ích)
Bài đăng này đã không được cập nhật trong 8 năm
Chắc hẳn các bạn không còn xa lạ gì với khái niệm Regular Expression. Việc sử dụng Regular Expression đem lại rất nhiều thuận tiện cũng như hiệu quả trong việc xử lý chuỗi và tách chuỗi, giúp những đoạn code xử lý chuỗi của chúng ta ngắn gon hơn rất nhiều (mặc dù sẽ gây khó hiểu cho những ai không có kiến thức về regex (yaoming)).
Có rất nhiều biểu thức regex cho chúng ta sử dụng. Ngoài các biểu thức quen thuộc thì hnay chúng ta hãy cùng tìm hiểu những biểu thức nhiều khả năng là mới lạ với nhiều người nhưng việc nắm bắt được chúng thì sẽ khá là hữu ích. Hy vọng sau bài này các bạn có thể sử dụng regex expression thành thục hơn phục vụ cho nhu cầu công việc để những biểu thức regex trở nên thú vị thay vì là những chuỗi ký tự loằng ngoằng phức tạp đáng sợ.
- Match nth subpartern
\n
\gn
?n (n là một số)
Thường được gọi là backreference, biểu thức này sẽ khớp với sự lặp lại của văn bản được ghi lại trong một subparttern trước đó.
n là vị trí subparttern lặp lại tính từ subparttern đầu tiên (trong ví dụ dưới đây là 2).
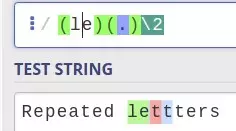
\g{n}
\g<n>
\g'n'
Tương tự như \gn. Tuy nhiên sẽ rất hữu ích trong trường hợp muốn bắt một chuỗi mà phía sau n là 1 số khác

(?+n)
khớp với sự lặp lại của văn bản được ghi lại trong subparttern thứ n tính từ subparttern hiện tại.
- Naming for subparttern
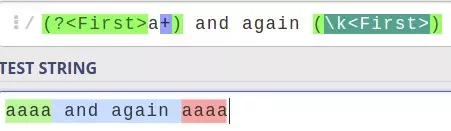
(?<First>a+)
(?'First'a+)
(?P<First>a+)
=> subparttern trên sẽ có tên là First. Và ta có thể gọi lại subparttern này ở chỗ nào đó trong cả parttern của chúng ta để làm việc.
Việc đặt tên cho subparttern có ưu điểm là dễ gợi nhớ. Ta hoàn toàn có thể gọi lại 1 subparttern ở một chỗ khác bằng cách sử dụng \n hoặc \gn như ở trên. Nhưng rõ ràng việc đặt một tên cho subparttern có tính gợi nhớ hơn nhiều so với con số 1, 2, 3...Nó tương tự như việc ta đặt tên cho các hằng số khi code vậy.
Và một ưu điểm khác là tên subparttern thì cố định, còn chỉ số 1, 2, 3...ở trên có thể thay đổi khi ta thêm hoặc bớt các subparttern vào biểu thức regex. Khi đó ta sẽ phải lần mò để thay đổi các giá trị này cho đúng. Điều này rất dễ gây nhầm lẫn, mà một khi nhầm lẫn thì công sức đi mò mẫm để tìm ra giá trị đúng là khá mệt nhất là khi thêm hoặc bớt nhiều subparttern một lúc. Nếu đặt tên cho subparttern thì mỗi khi thêm bớt subparttern ta không cần care đến các subparttern đã được đặt tên nữa (whew).
- Match subparrtern
name
\k<name>
\k'name'
\k{name}
\g<name>
\g'name'
\g{name}
?P>name
?&name
Khớp với subparttern được đặt tên là name. subparttern tên là name không quan trọng ở trước hay sau subparttern hiện tại. Lưu ý tính năng này là thử nghiệm trong JavaScript và có thể không được trình duyệt của bạn hỗ trợ.
?P=named_group
Cũng tương tự như trên nhưng 'named_group' phải được define trước đó (phải ở trước subparttern hiện tại).
- Match nth relative previous subparrtern
\g{-n}
Nhắc lại subparrtern thứ n trước vị trí hiện tại của \g{-n}. \g{-1} sẽ là subparrtern cuối cùng trước \g.

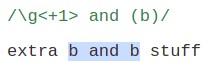
- Recurse nth relative upcoming subparrtern
\g<+n>
\g'+n'
Nhắc lại subparrtern thứ n tính từ vị trí hiện tại của \g<+n>. \g<+2> là subparrtern thứ hai sau \g,...
- Positive lookahead
(?=...)
Xác nhận rằng subpattern đã cho được khớp ở đây, nhưng các ký tự trong subpattern không xuất hiện trong kết quả.

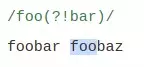
- Negative lookahead
(?!...)
Xác nhận rằng subpattern đã cho KHÔNG được khớp ở đây, các ký tự trong subpattern cũng không xuất hiện trong kết quả.
- Positive lookbehind
(?<=...)
Xác nhận rằng subpattern đã cho sẽ khớp, kết thúc tại vị trí hiện tại trong biểu thức. Subpattern phải có chiều rộng cố định. các ký tự trong subpattern cũng không xuất hiện trong kết quả.
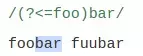
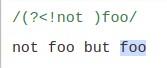
- Negative lookbehind
(?<!...)
Xác nhận rằng subpattern đã cho sẽ không khớp và kết thúc tại vị trí hiện tại trong biểu thức. Subpattern phải có chiều rộng cố định. các ký tự trong subpattern cũng không xuất hiện trong kết quả.
- Letters and digits
[[:alnum:]]
Khớp với bất kỳ chữ cái hoặc chữ số nào. Tương đương với [A-Za-z0-9].
- Letters
[[:alpha:]]
Khớp với bất kỳ chữ cái nào. Tương đương với [A-Za-z].
- ASCII CODES 0-127
[[:ascii:]]
Khớp với bất kỳ ký tự ASCII nào.

- Control characters
[[:cntrl:]]
Khớp các ký tự được sử dụng để kiểm soát trình bày văn bản, bao gồm ký tự xuống dòng, ký tự rỗng, tab và ký tự exit. Tương đương với [\x00-\x1F\x7F].
- Space or tab only
[[:blank:]]
Khớp ký tự space và tab (nhưng không khớp với ký tự new line). Tương đương với [ ]
- Reset match
\K
Đặt vị trí đã cho trong regex là vị trị bắt đầu mới của regex. Điều này có nghĩa rằng không có gì trước \K xuất hiện trong kết quả tổng thể.

Trên đây là các parrtern mình cảm thấy thú vị sau một thời gian làm việc với Regular Expression. Hy vọng nó có thể giúp các bạn cảm thấy regex dễ hiểu và thú vị hơn.
Tham khảo https://regex101.com
All rights reserved
