Một số bài toán khi làm việc với dữ liệu lớn mà bạn cần biết
Bài đăng này đã không được cập nhật trong 6 năm
I. Lời mở đầu
 Đến một ngày đẹp trời, khi dữ liệu người dùng ngày một lớn lên. Chúng ta cần có cách giải quyết tối ưu để dữ liệu không bị lọt và hoàn thành yêu cầu.
Bạn có thể sử dụng bộ dữ liệu này để test: https://github.com/datacharmer/test_db
Đến một ngày đẹp trời, khi dữ liệu người dùng ngày một lớn lên. Chúng ta cần có cách giải quyết tối ưu để dữ liệu không bị lọt và hoàn thành yêu cầu.
Bạn có thể sử dụng bộ dữ liệu này để test: https://github.com/datacharmer/test_db
II. Nội dung
-
Làm thế nào để gửi 1 triệu email?
Cài đặt dịch vụ mail sendgrid:
- Thêm vào composer.json rồi chạy composer update
"require": { "s-ichikawa/laravel-sendgrid-driver": "~2.0" },hoặc chạy command với composer
composer require s-ichikawa/laravel-sendgrid-driverThêm service provider của sendgrid vào config/app.php
'providers' => [ Sichikawa\LaravelSendgridDriver\SendgridTransportServiceProvider::class ];Để gửi được nhiều mail liên tục trong 1 ngày (khoảng 1 triệu emails) thì các bạn đầu tiên sẽ phải đăng ký dịch vụ gửi mail của sendgrid để tránh bị spam mail.
![]() Cấu hình .env
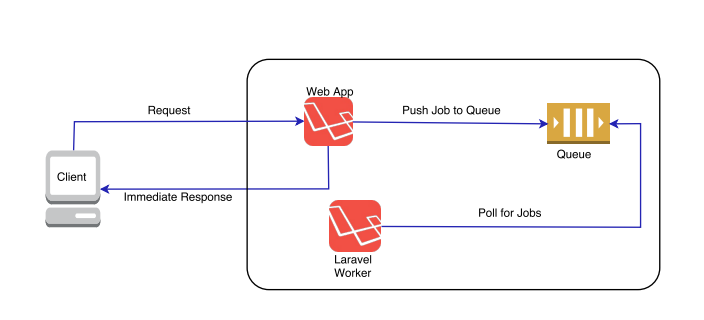
Cấu hình .envMAIL_DRIVER=sendgrid SENDGRID_API_KEY='YOUR_SENDGRID_API_KEY'Sau khi đã có dịch vụ gửi mail hệ thống đã chắn chắn rằng có thể bắt đầu gửi mail. Quay trở lại với bài toán gửi 1 triệu mails. Để hệ thống có thể gửi 1 triệu mails, trong quá trình code các bạn hãy tạo ra các queues để send mail và dùng supervior để giám sát cũng như tạo ra nhiều worker để xử lý các queues đó.
![]() Các bạn hãy chia nhỏ dữ liệu người dùng rồi chia đều vào các queues là mailer1, mailer2,...
Các bạn hãy chia nhỏ dữ liệu người dùng rồi chia đều vào các queues là mailer1, mailer2,...php artisan queue:work --queue=mailer1 --tries=3 php artisan queue:work --queue=mailer2 --tries=3Và tạo ra nhiều laravel worker để có thể xử lý hết các queues đó ví dụ: laravel-worker1, laravel-worker2,... Gửi mail sử dụng queues hay laravel worker như thế nào bạn có thể tìm hiểu chi tiết tại đây: https://viblo.asia/p/ban-biet-gi-ve-laravel-queue-phai-chang-doi-cho-la-hanh-phuc-djeZ1DWYKWz
-
Làm thế nào để tăng tốc độ tìm kiếm?
- Đánh chỉ mục (index): Index là một cấu trúc dữ liệu giúp xác định nhanh chóng các records trong table.
Hiểu một cách đơn giản thì nếu không có index thì SQL phải scan toàn bộ table để tìm được các records có liên quan. Dữ liệu càng lớn, tốc độ query sẽ càng chậm.
- Ưu điểm: Ưu điểm của index là tăng tốc độ tìm kiếm records theo câu lệnh WHERE. Không chỉ giới hạn trong câu lệnh SELECT mà với cả xử lý UPDATE hay DELETE có điều kiện WHERE.
- Nhược điểm: Khi sử dụng index thì tốc độ của những xử lý ghi dữ liệu (Insert, Update, Delete) sẽ bị chậm đi. Vì ngoài việc thêm hay update thông tin data thì MYSQL cũng cần update lại thông tin index của bảng tương ứng. Tốc độ xử lý bị chậm đi cũng tỷ lệ thuận với số lượng index được xử dụng trong bảng. Do vậy với những table hay có xử lý insert, update hoặc delete và cần tốc độ xử lý nhanh thì không nên được đánh index. Ngoài ra việc đánh index cũng sẽ tốn resource của server như thêm dung lượng cho CSDL.
- Đánh index 1 trường: Đây là cách khá thông thường khi chúng ta lựa chọn 1 column được sử dụng nhiều khi tìm kiếm và đánh index cho nó. Nhưng có một lưu ý đó là nếu số lượng giá trị unique hay giá trị khác NULL trong column đó quá thấp so với tổng số records của bảng thì việc đánh index lại không có ý nghĩa lắm. Sẽ khá là kỳ lạ nếu những trường như gender hay age lại được đánh index ngay cả khi được tìm kiếm nhiều.
- Đánh index nhiều trường: Với trường hợp đánh index trên nhiều columns thì index chỉ có hiệu quả khi search theo thứ tự các trường của index. Giả sử có table Customer:
CREATE TABLE Customer(
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
key(last_name, first_name, dob) );
Thứ tự cột index trong câu lệnh trên là last_name, first_name và dob. Vậy nếu điều kiện tìm kiếm như dưới thì index sẽ được sử dụng.
- Sử dụng index:
SELECT * FROM Customer WHERE last_name=’Peter’ AND first_name=’Smith’
- Trường hợp không sử dụng được index:
SELECT * FROM Customer WHERE first_name=’Smith’ AND bod=’1992/04/11’;
SELECT * FROM Customer WHERE first_name=’Smith’ AND last_name=’Peter’
- Sử dụng elacticsearch với laravel:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Sử dung thêm engine để hỗ trợ việc query cho elacticsearch:
babenkoivan/scout-elasticsearch-driver: 4.0
Tạo index:
php artisan elastic:create-index App\\Elasticsearch\\Indexes\\PostsIndex
php artisan scout:import App\\Models\\Post
- Làm thế nào để export 1 triệu bản ghi ra excel?
![]()
Cài đăt:
composer require maatwebsite/excel
Đăng ký service provider:
'providers' => [
....
Maatwebsite\Excel\ExcelServiceProvider::class,
],
Đây là cách export file excel thông thường
Excel::load('file.xls', function($reader) {
// Getting all results
$results = $reader->get();
// ->all() is a wrapper for ->get() and will work the same
$results = $reader->all();
});
Tuy nhiên với dữ liệu lớn ta không thể cùng 1 lúc export tất cả mà phải chia nhỏ data thành nhiều phần rồi export và tạo ra nhiều file khác nhau và có thể sử dụng stream của php để bỏ các data đã export ra excel,... Tham khảo đoạn code sau:
// $excel_data contains some data regarding the project, nothing relevant here
$output = Excel::create('myproject-' . $excel_data->project->name . '-'.date('Y-m-d H:i:s') . '-export', function($excel) use($excel_data) {
// Set the title
$excel->setTitle($excel_data->project->name . ' Export');
$excel->sheet('Data', function($sheet) use($excel_data) {
$rowPointer = 1;
$query = DB::table('task_metas')
->where([
['project_id', '=', $excel_data->project->id],
['deleted_at', '=', null]
])
->orderBy('id');
$totalRecords = $query->count();
// my server can't handle a request that returns more than 20k rows so I am chunking the results in batches of 15000 to be on the safe side
$query->chunk(15000, function($taskmetas) use($sheet, &$rowPointer, $totalRecords) {
// Iterate over taskmetas
foreach ($taskmetas as $taskmeta) {
// other columns and header structure omitted for clarity
$sheet->setCellValue('A' . $rowPointer, $rowPointer);
$sheet->setCellValue('B' . $rowPointer, $taskmeta->id);
$sheet->setCellValue('C' . $rowPointer, $taskmeta->url);
// Move on to the next row
$rowPointer++;
}
// logging the progress of the export
activity()
->log("wrote taskmeta to row " . $rowPointer . "/" . $totalRecords);
unset($taskmetas);
});
});
});
$output->download('xlsx');
III. Tạm kết
Chắc rằng sau bài viết này các bạn đã có đôi chút kiến thức để làm việc với dữ liệu lớn rồi đúng không. Hy vọng được sự góp ý của các bạn để có thể test thêm nhiều trường hợp cũng như yêu cầu hơn nữa

All rights reserved
