Một câu SQL thực sự được xử lý như thế nào bên trong database
1. Khi bạn chạy một câu SQL, điều gì xảy ra?
Khi database nhận một câu SQL, nó không thực thi ngay. Query thường đi qua các bước chính sau.
1.1 Parsing (phân tích cú pháp)
Database kiểm tra:
- cú pháp SQL có hợp lệ không
- bảng và cột có tồn tại không
- quyền truy cập có hợp lệ không
Ví dụ:
SELECT * FROM tasks WHERE id = 1;
Nếu viết sai:
SELECTE * FROM tasks
query sẽ dừng ngay ở bước này.
1.2 Query Optimization (tối ưu query)
Sau khi câu SQL hợp lệ, Query Optimizer sẽ tìm cách thực thi hiệu quả nhất.
Ví dụ, giả sử bảng có composite index (a, b).
CREATE INDEX idx_ab ON table(a, b);
Bây giờ xét hai query:
SELECT * FROM table WHERE a = x AND b = y;
SELECT * FROM table WHERE b = y AND a = x;
Câu hỏi là:
Hai query này có khác nhau về performance không?
Câu trả lời là không, vì optimizer sẽ chuẩn hóa điều kiện trước khi tạo execution plan. Vì vậy thứ tự điều kiện trong WHERE thường không ảnh hưởng đến performance.
Optimizer hiểu rằng:
a = x AND b = y
và
b = y AND a = x
là cùng một điều kiện logic.
Execution plan thường giống nhau, ví dụ:
Index Scan using idx_ab
Điều thực sự quan trọng ở đây không phải thứ tự điều kiện, mà là thứ tự cột trong index.
Ví dụ index (a, b):
Query này tận dụng index tốt:
WHERE a = x
hoặc
WHERE a = x AND b = y
Nhưng query này có thể index không hiệu quả nếu:
WHERE b = y
Vì index được sắp theo a → b, nên database cần biết giá trị a trước.
1.3 Execution (thực thi query)
Sau khi optimizer chọn được execution plan, database bắt đầu thực thi.
Ví dụ execution plan có thể là:
Index Scan
→ Filter
→ Return rows
Database sẽ thực hiện:
- đọc dữ liệu từ index
- truy cập table heap
- thực hiện filter / join / sort
1.4 Return result
Sau khi xử lý xong, database trả kết quả về cho client.
2. Tại sao query lần 2 thường nhanh hơn?
Một hiện tượng rất phổ biến:
lần 1 → query chậm
lần 2 → query nhanh hơn
Nguyên nhân chính thường nằm ở database caching.
2.1 Database đọc dữ liệu theo page
Database không đọc từng dòng dữ liệu riêng lẻ.
Thay vào đó, dữ liệu được lưu và đọc theo page (block dữ liệu).
Một page thường có kích thước khoảng 8KB (PostgreSQL)
Ví dụ một bảng có thể được lưu như sau:
Page 1 → rows 1..100
Page 2 → rows 101..200
Page 3 → rows 201..300
2.2 Điều gì xảy ra ở lần query đầu tiên?
Giả sử chạy query:
SELECT * FROM tasks WHERE id = 500;
Nếu page chứa row 500 chưa có trong RAM, database phải:
Disk → load page vào RAM → tìm row
Disk I/O là phần chậm nhất trong toàn bộ quá trình.
2.3 Điều gì xảy ra ở lần query thứ hai?
Sau lần query đầu tiên, page đó thường vẫn nằm trong buffer cache (RAM).
Vì vậy lần thứ hai:
RAM → tìm row
Không cần đọc disk nữa.
Sự khác biệt:
Disk access ≈ milliseconds
RAM access ≈ microseconds
Đó là lý do query lần 2 thường nhanh hơn đáng kể.
2.4 Minh họa trực quan
Giả sử bảng tasks có dữ liệu nằm trên disk:
Disk
├── Page 1
├── Page 2
├── Page 3
Lần query đầu:
Disk → load Page 2 → RAM
Lần query sau:
RAM → đọc Page 2 trực tiếp
Không cần truy cập disk nữa.
2.5 Đây là lý do benchmark có thể sai lệch
Nếu bạn benchmark query:
lần 1 → 50 ms
lần 2 → 5 ms
không có nghĩa query đã được tối ưu 10 lần.
Có thể đơn giản là data đã được cache trong RAM.
Vì vậy khi phân tích performance query, cần hiểu rõ cơ chế caching của database. Nếu chỉ chạy query bình thường, kết quả có thể bị ảnh hưởng bởi cache và không phản ánh đúng chi phí thực thi.
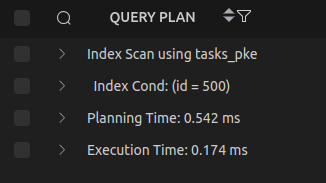
Một cách phổ biến là sử dụng EXPLAIN ANALYZE.
Ví dụ:
EXPLAIN ANALYZE
SELECT *
FROM tasks
WHERE id = 500;
Lệnh EXPLAIN ANALYZE sẽ:
- Phân tích cú pháp (parsing) để kiểm tra câu SQL có hợp lệ hay không
- Tối ưu query (query optimization) để tạo execution plan
- Thực thi query thật theo execution plan đã chọn
- Hiển thị execution plan mà database sử dụng
- Hiển thị planning time (thời gian database tạo execution plan)
- Hiển thị execution time (thời gian thực thi query)
3. Dữ liệu cache trong database có bị outdate không?
Một câu hỏi thường gặp là:
Nếu database cache dữ liệu trong RAM, thì khi dữ liệu thay đổi, dữ liệu cache có bị outdate không?
Câu trả lời là:
Không, vì database có cơ chế đảm bảo tính nhất quán (consistency).
Database sử dụng buffer cache để lưu các page dữ liệu từ disk vào RAM. Đây là cache nội bộ do database quản lý.
Khi dữ liệu được update, ví dụ:
UPDATE tasks SET title = 'new' WHERE id = 500;
Database sẽ:
- cập nhật dữ liệu ngay trong memory (buffer cache)
- ghi log (WAL / redo log)
- sau đó mới flush xuống disk
Điểm quan trọng là:
Page trong RAM sẽ được cập nhật theo dữ liệu mới
Vì vậy khi query lại:
SELECT * FROM tasks WHERE id = 500;
Database vẫn đọc từ RAM, nhưng đây là dữ liệu đã được update, không phải dữ liệu cũ.
All rights reserved
