Mời các bạn góp ý project Sentiment Analysis sử dụng Tf-Idf áp dụng cho ngôn ngữ tiếng việt
Bài đăng này đã không được cập nhật trong 5 năm
Mở đầu :
- Text mining ( lấy thông tin từ text) là một lĩnh vựng rộng và áp dụng trong nhiều lĩnh vực khác nhau. Một số ứng dụng có thể kể đến là : sentiment analysis, document classification, topic classification, text summarization, machine translation. Trong bài hôm nay ta sẽ tìm hiểu về sentiment analysis.Phân tích cảm xúc(sentiment analysis) được hiểu đơn giản là đánh giá 1 câu nói, tweet là tích cực (pos) hay tiêu cưc(neg). Chẳng hạn lấy một ví dụ, bạn mở một cửa hàng bán đồ ăn mà muốn biết trên mạng xã hội người ta nói gì về quán ăn của bạn. Bạn bắt đầu vào face, instagram hay tweeter để thu thập các commnent liên quan đến quán ăn của bạn. Bạn bắt đầu đoc thì có người khen người chê, vấn đề xảy ra là bây giờ số comment nó tăng lên 1000 hay 10000 bạn có đủ sức đọc các comment đó hay không.Bạn bắt đầu nghĩ ra sẽ build một model làm việc đó cho bạn. Ta bắt tay vào công việc.
- Thuật toán sử dung : mình sẽ sử dụng logistic regression kết hợp với kỹ thuật tf-idf
- Library : pyvi(một thư viện xử lý tiếng việt), sklearn
- Các bước thực hiện :
- Chuẩn bị dữ liệu
- Tiền xử lý dữ liệu
- Build model
- Funny một tí
Chuẩn bị dữ liệu
Dữ liệu text có ở khắp mọi nơi từ facebook đến các website đâu đâu cũng có.Mình sẽ lấy dữ liệu từ trang tripnow.vn một trang web con của foody.vn chuyên về đánh giá các cửa hàng. Để đơn giản mình chỉ lấy comment ở các cửa hàng ở TP.hcm và trên mỗi comment đó có star thang đo từ 1-10 mình sẽ lấy nó làm căn cứ đánh giá comment là pos or neg.
- Bắt đầu chiến dịch cà web nào (crawler). Mình sẽ sử dụng selenium để cà dữ liệu text.
#load thu vien
import numpy as np
import selenium
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
#open list name
with open("name.txt") as f:
names = f.read()
list_name = names.split("\n")
#crawler data
driver = webdriver.Chrome()
path = "https://www.tripnow.vn"
texts = []
scores = []
for name in range(len(list_name)):
path_link = path + list_name[name] + "/binh-luan"
driver.get(path_link)
actions = webdriver.ActionChains(driver)
count = 0
while (count<30):
load_more = driver.find_element_by_xpath("//div/*[@ng-click='LoadMore()']")
actions.move_to_element(load_more).perform()
load_more.click()
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
count += 1
time.sleep(3)
text = driver.find_elements_by_xpath("//div/span[@ng-bind-html='Model.Description']")
score = driver.find_elements_by_xpath("//li/div/div/div/span[@class='ng-binding']")
for tx,sc in zip(text,score):
comment = tx.text
scoring = sc.text
texts.append(comment)
scores.append(scoring)
- Giải thích code một tí
- Để tránh code dài mình lưu các tên cửa hàng ở file name.txt
- Mỗi cửa hàng có rất nhiều comment (có thể vài trăm) nhưng mình chỉ lấy 300 comment ở mỗi cửa hàng vì máy mình tương đối yếu load nhiều máy chạy không nổi.
- Comment được lấy từ //div/span[@ng-bind-html='Model.Description] và lưu vào biến texts
- Score được lấy từ //li/div/div/div/span[@class='ng-binding'] và lưu vào biến scores
- Mình cho nó chạy tầm 2 tiếng thu được tầm 6000 comment và được lưu dưới dạng text
![]()

Tiền xử lý dữ liệu
- Trước tiên ta tìm hiểu kỹ thuật TF-IDF nó là viết tắt của từ Term frequency invert document frequency.Nó là một kỹ thuật feature extraction dùng trong text mining và information retrieval. Trước khi có tf-idf người ta dùng one-hot-encoding để embedding words sang vector. Nhưng kỹ thuật này gặp một số hạn chế là :
- Những từ thường xuyên xuất hiện sẽ không có nhiều thông tin nhưng vẫn có tỉ trọng(weight) ngang với các từ khác.vd : stop word chẳng hạn hay chúng ta phân tích vềquán ăn nào đó thì từ "quán ăn" xuất hiện ở tất cả document.Chúng ta cần giảm tỉ trọng về mặt thông tin nó xuống vì thông tin không mang nhiều giá trị.
- Những từ hiếm(rare word) or key word không có sự khác biệt về tỉ trọng thông tin
- Để khắc phục hạn chế này tf-idf đã ra đời.Tf-idf bao gồm 2 thành phần là tf(term frequency) và idf(inverse document frequency).
- tf đo lường tỉ trọng tần suất từ w có trong document d.Vì document thường có lenght khác nhau nên để normalization ta chia nó cho number word trong document d.
- N là tổng số document trong dataset.Tỉ số được xem là inverse document frequency. Nếu một từ xuất hiện nhiều ở các document thì tỉ số này sẽ gần 1.Và ngược lại một từ ít xuất hiện hơn tỉ số này sẽ cao hơn 1. Điều này giúp giảm tỉ trọng của những từ thường xuyên suất hiện và tăng tỉ trọng những từ ít xuất hiện trong document hơn (lưu ý N luôn lớn hơn hoặc bằng documnet in word w appear).
- Một vấn đề là khi N rất lớn mà documnet in word w appear rất nhỏ thì tỉ số này rất lơn cho nên là người dùng log transform để giảm giá trị tỉ số ránh gây khó khăn trong việc tính toán ( lưu ý log nó làm giảm giá trị theo cấp lũy thừa). Khi đó công thức idf cuối cùng sẽ là :
- Ví dụ : Một document 100 word chứa word cat 3 lần. . Giả sử có 10000 document mà word cat xuất hiện trong 1000 document. .
- Ta bắt đầu xử lý dữ liệu. Đầu tiên là load dữ liệu
#import library
import numpy as np
import pandas as pd
from pyvi import ViTokenizer
import glob
from collections import Counter
from string import punctuation
#load data
paths = glob.glob("./comment/*.txt")
comments = []
for path in paths :
with open(path,encoding="utf-8") as file:
text= file.read()
text_lower = text.lower()
text_token = ViTokenizer.tokenize(text_lower)
comments.append(text_token)
file.close()
- Dữ liệu sẽ được tách từ bằng ViTokenizer.tokenize sau đó được lưu dưới biến comment.
stop_word = []
with open("stop_word.txt",encoding="utf-8") as f :
text = f.read()
for word in text.split() :
stop_word.append(word)
f.close()
punc = list(punctuation)
stop_word = stop_word + punc
print(stop_word)
- Tiếp theo là xây dựng stop_word và punctuation
![]()

sentences = []
for comment in comments:
sent = []
for word in comment.split(" ") :
if (word not in stop_word) :
if ("_" in word) or (word.isalpha() == True):
sent.append(word)
sentences.append(" ".join(sent))
- Làm sạch data loại bỏ stop_word , những từ không phải alphabet được remove
- Tiếp theo ta embedding text thành vector sử dụng if-idf với function TfidfVectorizer trong `sklearn'
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer(min_df=5,max_df= 0.8,max_features=3000,sublinear_tf=True)
tf.fit(sentences)
X = tf.transform(sentences)
- Hàm TfidfVectorizer có các tham số chúng ta cần chú ý là:
- min_df : loại bỏ những từ nào từ vocabulary có tần suất suất hiện nhỏ hơn min_df ( tính theo count)
- max_df " loại bỏ những từ nào từ vocabulary có tần suất xuất hiện lớn hơn max_df ( tính theo %)
- sublinear_tf: Scale term frequency bằng logarithmic scale
- stop_words loại bỏ stop word, chúng ta đã làm trước đó nên không cần tham số này
- max_features lựa chọn số character vào vocabulary
- vocabulary nếu chúng ta đã xây dựng vocabulury trước đó thì không cần max_features
- token_pattern là regular expression để chọn word vào vocabulary
- Xử lý label : ta sẽ đưa ra một threshold để quyết định 1 comment là pos hay neg. Ta chọn threshold là 6, khi score < 6 thì comment được xem là neg và ngược lại là pos
from sklearn.preprocessing import Binarizer
binaray = Binarizer(threshold=6)
y = binaray.fit_transform(y_score)
y = np.array(y).flatten()
- Nhận xét dữ liệu của chúng ta là không tốt lắm vì số neg = 691 trên tổng số comment là 6000. Như vậy chỉ có 10% là neg khi đó dữ liệu sẽ unbalance . Cũng dễ hiểu vì đa số quán ăn trên trang tripnow.vn là ngon hoặc là foody.vn thuê người comment chẳng hạn. Vì cả 2 label neg và pos có thể xem là quan trọng như nhau. không có biến nào trội hơn nên model của chúng ta trên data này có lẽ sẽ không tốt. Hơn nữa score này chỉ mang tính chất tượng trưng nên không dám chắc nó là tiêu chí phân loại neg và pos tốt.
- Chia dữ liệu để training và testing tỷ lệ test là 30%
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=10,shuffle=True)
Build model
Ta dùng logistic regression để training model.
model = LogisticRegression()
model.fit(X_train,y_train)
y_pre = model.predict(X_test)
print(classification_report(y_test,y_pre))
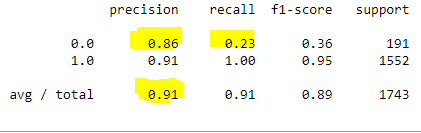
- Accuracy là 91% nhưng recall chỉ có 23% tương đối thấp. Có nghĩa là trong 191 comment neg ta chỉ dự đoán chính xác khoảng 44 comment
- Bây giờ ta thử predict một số câu.
text =[["quán nấu dở quá"],["đồ ăn bình_thường"],["quán nấu ngon"]]
for i in text:
test = tf.transform(i)
print(model.predict(test))
==>> [0] [1] [1]
- Không tốt lắm ha do dữ liệu unbalance quá với lại score chưa chuẩn để phân loại
Funny một tí
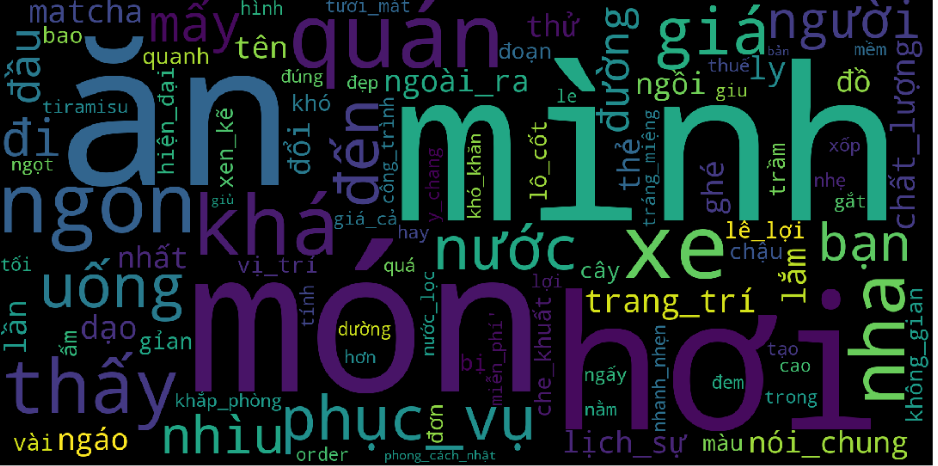
Ta sẽ xem những từ nào được sử dụng nhiều nhất trong document và xây dựng wordcloud của nó.
import wordcloud
import matplotlib.pyplot as plt
%matplotlib inline
cloud = np.array(sentences).flatten()
plt.figure(figsize=(20,10))
word_cloud = wordcloud.WordCloud(max_words=100,background_color ="black",
width=2000,height=1000,mode="RGB").generate(str(cloud))
plt.axis("off")
plt.imshow(word_cloud)
All rights reserved
