Materialized View In Cassandra, Part: 4
Bài đăng này đã không được cập nhật trong 4 năm
The most challenging task for newbies of Cassandra is the shifting when you move from a normalized relational data model (RDMS) to a typical Cassandra data model which is totally denormalized. You need to fetch data from a number of tables to serve a query, which could be a deadly thing in respect of performance as its always be said that "Read is always costly in Cassandra". Also, this automatically leads to a lot of data replication and a lot of extra coding. Fortunately 3.x versions of Cassandra can help you with duplicating data mutations by allowing you to construct views on existing tables.SQL developers learning Cassandra will find the concept of primary keys very familiar. That is Materialized View (MV) Materialized views suit for high cardinality data. The data in a MV is arranged serially based on the view's primary key. You can create MV for each of your primary keys.
Requirements for a materialized view:
- The columns of the source table's primary key must be part of the materialized view's primary key.
- Only one new column can be added to the materialized view's primary key. Static columns are not allowed.
Example
The following table is the original, or source, table for the materialized view examples in this section.
CREATE TABLE framgia_employee (cid UUID PRIMARY KEY, name text, age int, birthday date, platform text);
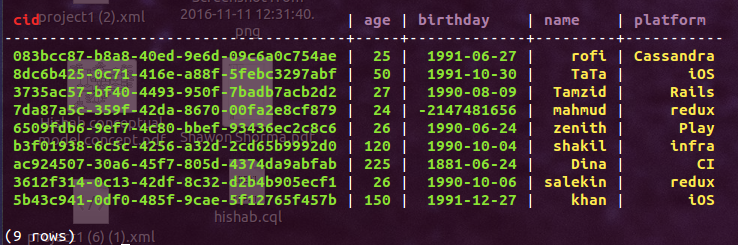
This table holds values for the name, age, birthday, and platform of work of some framgia employees.
The framgia_employee_mv table can be the basis of a materialized view that uses platform in the primary key as per the following way.
CREATE MATERIALIZED VIEW employee_by_platform
... AS SELECT age, birthday, name, platform
... FROM framgia_employee
... WHERE platform IS NOT NULL and cid IS NOT NULL
... PRIMARY KEY (platform, cid);
Lets checkout how it looks like
SELECT age, birthday, name FROM employee_by_platform WHERE platform = 'CI';

Lets check another example of Materialize View of framgia_empoloyee table using age parameter.
CREATE MATERIALIZED VIEW employee_by_age
... AS SELECT age, birthday, name
... FROM framgia_employee
... WHERE age IS NOT NULL and cid IS NOT NULL
... PRIMARY KEY (age, cid);
And query on it
select * FROM employee_by_age WHERE age = 26;
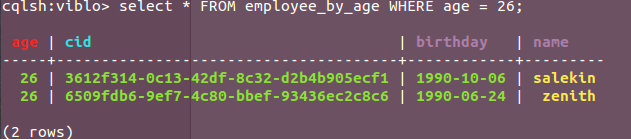
That's simple it is....(smile)
When another INSERT is executed on framgia_employee, Cassandra updates the source table and both of these materialized views. When data is deleted from framgia_employee, Cassandra deletes the same data from any related materialized views.
Materialized views permit fast follow of the data using the normal Cassandra read path. However, materialized views do not have the same write performance as normal table writes. Cassandra performs an additional read-before-write to update each materialized view. To complete an update, Cassandra performs a data consistency check on each replica. A write to the source table incurs latency. The performance of deletes on the source table also suffers. If a delete on the source table affects two or more contiguous rows, this delete is tagged with one tombstone. But these same rows may not be contiguous in materialized views derived from the source table. If they are not, Cassandra creates multiple tombstones in the materialized views.
Cassandra can only write data directly to source tables, not to materialized views. Cassandra updates a materialized view asynchronously after inserting data into the source table, so the update of materialized view is delayed. Cassandra performs a read repair to a materialized view only after updating the source table.
Some other Syntax
a. Alter Syntax
ALTER MATERIALIZED VIEW [ keyspace_name. ] view_name
( WITH property [ AND property ] [ . . . ] ]
b. Describe Syntax
DESCRIBE MATERIALIZED VIEW
c. Drop Syntax
DROP MATERIALIZED VIEW [ IF EXISTS ] [ keyspace_name. ] view_name
All rights reserved
