Machine learning: Trích xuất đặc trưng văn bản - Part 1
Bài đăng này đã không được cập nhật trong 7 năm
**Giới thiệu ngắn về Mô Hình Không Gian Vector - Vector Spacec Model (VSM) **
Trong thu thập thông tin hay khai thác văn bản, khái niệm tần số xuất hiện - tần số tài liệu nghịch đảo ( tf-idf) là một phương pháp nổi tiếng để tính toán mức độ quan trọng của một từ trong một tài liệu. Tf-idf là một cách rất thú vị để chuyển thông tin dưới dạng văn bản sang mô hình khôn gian vector( VSM), hay những đặc trưng thưa thớt. Chúng ta sẽ thảo luận về vấn đề này sau. Trước hết, hãy cố gắng hiểu tf-idf và VSM là gì?
VSM là một phần rất phức tạp, xem ví dụ từ bài viết The most influential paper Gerard Salton Never Wrote. Tổng hợp lại, VSM là một mô hình đại số biểu diễn thông tin dưới dạng văn bảng thành một vector, các thành phần của vector này có thể biểu diễn sự quan trọng của khái niệm (tf-idf) hay sự xuất hiện của từ đó trong tài liệu. Điều quan trọng cần lưu ý là VSM cổ điển được Salton đề xuất kết hợp các tham số / thông tin cục bộ và toàn cầu (theo nghĩa là nó sử dụng cả cụm từ phân lập được phân tích cũng như toàn bộ bộ sưu tập tài liệu. VSM được giải thích là một không gian nơi mà văn bản được biểu diễn như là vector thay thế cho dạng biểu diễn văn bản ban đầu. VSM biểu diễn đặc trưng được trích xuât từ văn bản.
Cùng xác định VSM và tf-idf với những ví dụ cụ thể, mình sẽ dùng python trong ví dụ củ thể.
Không gian vector
Bước đầu tiên trong chuyển văn bản sang không gian vector là tạo một thư mục để biểu diễn tài liệt. Để thực hiện, bạn cần chọn tất cả các từ trong tài liệu và chuyển nó sang một chiều trong không gian vector, nhưng bạn biết rằng có một số loại của từ mà được biểu diễn trong hầu hết các văn bản và việc chúng ta đang làm là trích xuất những đặc trưng quan trọng của văn bản nên những từ như "the, is, at, on..." sẽ không giúp chung ta nhiều nên chúng ta sẽ bỏ qua chúng khi trích xuất.
Hãy lấy đoạn văn bản bên dưới để xác định không gian tài liệu của chúng ta:
Train Document Set - Tập huấn luyện:
d1: The sky is blue.
d2: The sun is bright.
Test Document Set- Tập kiểm tra:
d3: The sun in the sky is bright.
d4: We can see the shining sun, the bright sun.
Bây giờ, việc chúng ta cần làm là tạo ra một từ điển chỉ số của những từ trong tập dữ liệu huấn huyện. Dùng d1 và d2 từ tập huấn luyện, chúng ta sẽ có từ điện chỉ số như trong hình kí hiệu 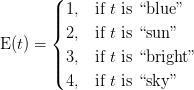
Chú ý rằng những từ như "is" và "the" bị bỏ qua như được trích dẫn trước đó. Bây giờ chúng ta có một từ điển chỉ số, chúng ta có thể chuyển văn bản kiểm tra thành một không gian vector nơi mà mỗi từ của vector được chỉ rõ như là tự vựng chỉ số. Bây giờ chúng ta sẽ chùng term-frequency để biểu diễn mỗi từ trong không gian vector của chúng ta. TF là thước đo số lần xuất hiện của từ trong từ điển E(t). Chúng ta xác định TF bằng một hàm đếm:
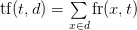
Nơi mà fr(x,t) là một hàm đơn giản:
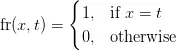 Vì về, hàm tf(t,d) sẽ trả về số lần từ t xuất hiện trong văn bản d. Ví dụ, tf("sun, d4)= 2 vì từ "sun" xuất hiện hai lần trong d4. Bây giờ bạn đã hiểu cách hoạt động của tf, bây giờ chúng ta sẽ tạo một vector văn bản, được biểu diễn bởi phương trình dưới:
Vì về, hàm tf(t,d) sẽ trả về số lần từ t xuất hiện trong văn bản d. Ví dụ, tf("sun, d4)= 2 vì từ "sun" xuất hiện hai lần trong d4. Bây giờ bạn đã hiểu cách hoạt động của tf, bây giờ chúng ta sẽ tạo một vector văn bản, được biểu diễn bởi phương trình dưới:
Mỗi chiều của vector văn bản được biểu diễn bằng tần xuất của từ. Ví dụ, biểu diễn số lần xuất hiện của từ ("blue") trong văn bản .
Một ví dụ củ thể của văn bản và được biểu diễn như vector:
từ công thức, ta có:
Từ kết quả ta thấy, trong văn bản không có từ "blue", những từ "sun", "bright" và "sky" xuất hiện 1 lần. Tương tự với
Bởi vì dữ liệu là tập hợp của các văn bản, mỗi văn bản được biểu diễn dưới dạng vector nên chúng ta kết hợp chúng thành một ma trận kích thước D x F trong đó D là số văn bản ta có và F kích thước của tập từ vựng.
All rights reserved
