🗄️🧠 Locking & Concurrency: Database Ngăn Chặn Ghi Đè Dữ Liệu Như Thế Nào? - Database System Design P8
Locking & Concurrency: Database Ngăn Chặn “Ghi Đè Dữ Liệu” Như Thế Nào?
1. Mở đầu: Câu chuyện từ một "Lost Update" đắt giá
Hãy tưởng tượng bạn đang vận hành một hệ thống Ví điện tử với hàng triệu người dùng. Một kịch bản tưởng chừng đơn giản xảy ra: Người dùng X có số dư 1.000.000 VNĐ. Tại cùng một microsecond, hai tiến trình đồng thời kích hoạt:
- Request A: Thanh toán hóa đơn điện 400.000 VNĐ.
- Request B: Nhận tiền hoàn từ một giao dịch cũ 200.000 VNĐ.
Cả hai request cùng đọc số dư cũ là 1.000.000 VNĐ. Request A tính toán xong và ghi đè số dư mới 600.000 VNĐ vào database. Ngay sau đó, Request B cũng hoàn tất tính toán dựa trên con số 1.000.000 VNĐ ban đầu và ghi đè số dư là 1.200.000 VNĐ.
Kết quả: Khoản thanh toán 400.000 VNĐ của người dùng biến mất hoàn toàn khỏi dòng tiền, dù ứng dụng báo giao dịch thành công. Đây chính là Lost Update (Mất cập nhật) – lỗi kinh điển có thể "giết chết" uy tín của một sản phẩm tài chính. Lỗi này gần như không bao giờ xuất hiện khi bạn test một mình ở môi trường Local, nhưng nó sẽ phá hủy dữ liệu một cách tàn nhẫn khi hệ thống scale lớn.
Tại TechCraft, chúng tôi luôn nhắc nhở: Database không chỉ là nơi lưu trữ; nó là "hệ thống giữ sự thật của toàn bộ sản phẩm". Để giữ được sự thật đó giữa tâm bão hàng vạn request đồng thời, chúng ta phải hiểu về Locking.
2. Niềm tin phổ biến: "Chỉ cần Transaction là đủ"
Trong giới lập trình, có một giả định cực kỳ nguy hiểm: "Chỉ cần bọc mọi thứ trong BEGIN và COMMIT là dữ liệu sẽ tự động an toàn trước race condition."
Đây là một "Black Box mental model" – coi database như một cái thùng chứa thụ động thay vì một bộ điều phối đồng thời chủ động. Thực tế, Transaction (ACID) là điều kiện cần, nhưng Locking mới là xương sống bảo vệ tính toàn vẹn dữ liệu bên trong cái khung đó.
Senior Lens: Tại sao Transaction vẫn để xảy ra Lost Update? Bởi vì hầu hết các Database hiện đại (như PostgreSQL, SQL Server) mặc định sử dụng Isolation Level là Read Committed. Ở mức độ này, Database cho phép các Transaction đọc dữ liệu đã commit, nhưng nó không ngăn cản Transaction khác sửa đổi dòng dữ liệu đó ngay sau khi bạn vừa đọc xong. Nếu bạn không dùng Locking đúng cách, lời hứa về tính "Isolation" chỉ là lớp vỏ bọc mỏng manh.
3. Bản chất của Locking: "Hợp đồng an toàn" của hệ thống
Locking không phải là một tính năng đi kèm để tối ưu; nó là một "hợp đồng an toàn" ràng buộc giữa database và các tiến trình truy cập. Nó tồn tại vì một nguyên lý tối thượng: Dữ liệu không thể chỉ đúng một nửa.
Tại sao một hệ thống trưởng thành không thể sống thiếu cơ chế khóa?
- Bảo vệ tính duy nhất của sự thật: Đảm bảo tại một thời điểm, chỉ có những thay đổi hợp lệ được ghi nhận.
- Điều phối tài nguyên dùng chung: Ngăn chặn các tiến trình "dẫm chân" lên nhau trong môi trường đa người dùng.
- Quản lý sự đánh đổi: Ép hệ thống phải lựa chọn giữa việc "đợi để đúng" hoặc "nhanh nhưng sai".
4. Phân tích kỹ thuật: Shared Lock vs. Exclusive Lock
Mọi Backend Engineer cần nắm vững hai loại khóa cơ bản nhất để kiểm soát hành vi của Database:
- Shared Lock (S - Khóa chia sẻ): Dùng cho thao tác Đọc. Cho phép nhiều người cùng giữ khóa để đọc dữ liệu, nhưng tuyệt đối không ai được sửa.
- Exclusive Lock (X - Khóa độc quyền): Dùng cho thao tác Ghi (Update/Delete). Chỉ một người duy nhất được giữ khóa. Khi một tiến trình giữ khóa X, tất cả những người khác (kể cả đọc hay ghi) đều phải xếp hàng chờ.
Ma trận tương thích (Lock Compatibility Matrix):
| Shared (S) | Exclusive (X) | |
|---|---|---|
| Shared (S) | Compatible (Hợp lệ) | Conflict (Xung đột) |
| Exclusive (X) | Conflict (Xung đột) | Conflict (Xung đột) |
Senior Insight: Database tự động quản lý các khóa này, nhưng rắc rối thường đến từ việc Query không tối ưu. Một Transaction kéo dài (long-running) do chứa logic nghiệp vụ nặng hoặc gọi API bên thứ ba sẽ giữ các khóa này quá lâu. Điều này không chỉ làm chậm database mà còn dẫn đến thảm họa cạn kiệt tài nguyên hệ thống (Connection Pool exhaustion).
5. Trade-off: Cái giá của sự an toàn
Trong Production, không có gì là miễn phí. Locking là một sự đánh đổi khốc liệt:
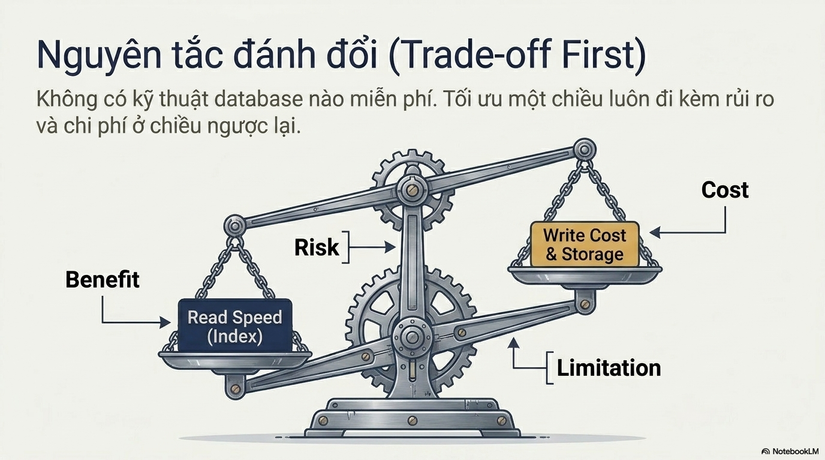
- Benefit (Lợi ích): Correctness (Tính đúng đắn). Dữ liệu luôn nhất quán, không có Lost Update, không có dữ liệu rác.
- Cost (Chi phí): Throughput giảm và Latency tăng. Mỗi giây một request phải chờ lock là một giây tài nguyên bị lãng phí.
- Systemic Risk (Rủi ro hệ thống): Đây là điểm các Senior quan tâm nhất. Khi
Lock Wait Timetăng cao, các Thread/Worker trong ứng dụng sẽ bị treo để chờ kết nối database. Kết quả là Connection Pool bị chiếm dụng toàn bộ, khiến toàn bộ App Server "chết đứng" (Cascading Failure) chỉ vì một vài dòng dữ liệu bị khóa quá lâu.
6. Khi "Ổ khóa" phản chủ: Lock Contention và Deadlock
Lock Contention (Tranh chấp khóa)
Xảy ra khi hàng vạn request cùng tranh giành một "ổ khóa" trên một dòng dữ liệu duy nhất (Hot Row).
- Ví dụ: Sự kiện Flash Sale cho một sản phẩm có số lượng giới hạn. Mọi request đều tập trung vào
UPDATE products SET quantity = quantity - 1 WHERE id = 1. - Hệ quả: Hàng đợi chờ lock dài dằng dặc, API timeout hàng loạt dù CPU database vẫn thấp.
Deadlock (Khóa chết)
Kịch bản kinh điển "Anh chờ tôi, tôi chờ anh" khiến hệ thống đứng yên hoàn toàn.
- Transaction 1 chiếm khóa trên Bảng A.
- Transaction 2 chiếm khóa trên Bảng B.
- Transaction 1 yêu cầu khóa trên Bảng B (phải chờ T2).
- Transaction 2 yêu cầu khóa trên Bảng A (phải chờ T1).
Root Cause Analysis: Deadlock thường xảy ra do thứ tự cập nhật dữ liệu không đồng nhất.Playbook xử lý: Luôn áp dụng quy tắc "Consistent Update Order". Ví dụ: Luôn cập nhật Bảng A trước Bảng B trong toàn bộ codebase, hoặc luôn sắp xếp (Sort) danh sách ID theo thứ tự tăng dần trước khi thực hiện Batch Update.
7. Tư duy Senior: Thiết kế hệ thống sống chung với Lock
Thay vì sợ hãi Locking, hãy học cách điều khiển nó thông qua các quyết định kiến trúc:
- Chiến lược "Keep transactions short": Tuyệt đối không đưa logic tính toán nặng, xử lý file, hoặc gọi API external vào bên trong block transaction. Transaction chỉ nên chứa các câu lệnh SQL thực thi nhanh nhất có thể.
- Sử dụng Lock Timeout: Luôn cấu hình timeout cho các yêu cầu lấy khóa. Thà trả về lỗi nhanh (Fail Fast) để client retry còn hơn là để request treo vô hạn làm sập Connection Pool.
- Optimistic Locking: Với các hệ thống read-heavy, hãy cân nhắc dùng cơ chế "versioning" (kiểm tra version lúc ghi) thay vì dùng khóa vật lý (Pessimistic Locking) để tăng tối đa Throughput.
8. Kết luận: Bước đệm sang MVCC
Locking là cơ chế bảo vệ sự thật, nhưng nó vô cùng "đắt đỏ" vì nguyên lý: Người ghi chặn người đọc, người đọc chặn người ghi (S xung đột với X). Trong các hệ thống quy mô lớn, việc block các request đọc chỉ vì có một tiến trình đang ghi là một rào cản lớn cho scalability.
Liệu có cách nào để Đọc và Ghi diễn ra cùng lúc mà không cần phải block nhau?
Câu trả lời nằm ở MVCC (Multi-Version Concurrency Control) – kỹ thuật "phân thân" dữ liệu để tối ưu hóa sự đồng thời. Đây chính là bí mật giúp các Database hiện đại như PostgreSQL hay MySQL đạt được hiệu năng kinh ngạc mà vẫn giữ được tính đúng đắn. Chúng ta sẽ giải mã cơ chế này trong tập tiếp theo.
🤝 Đồng hành cùng TechCraft
TechCraft là nơi chia sẻ kiến thức về Backend Engineering, Database, Distributed Systems và Production Architecture thông qua các bài viết, video và những series được xây dựng theo lộ trình.
Nếu bạn yêu thích cách tiếp cận này, hãy tiếp tục đồng hành cùng TechCraft trên các nền tảng bên dưới.
Và nếu muốn học chuyên sâu hơn, Dev Insider sẽ là nơi tập trung toàn bộ các nội dung premium được cập nhật liên tục mỗi tuần.
🚀 Dev Insider
https://www.patreon.com/techcraft_official/posts/vi-sao-dev-ra-161163881?collection=2220113
📘 Facebook
https://www.facebook.com/techcraft.official
🎥 YouTube
https://www.youtube.com/@techcraft.official
🎵 TikTok
https://www.tiktok.com/@techcraft.official
Think Beyond Code. Build Better Systems.
All rights reserved
