Latency
Bài đăng này đã không được cập nhật trong 5 năm
Latency là gì ?
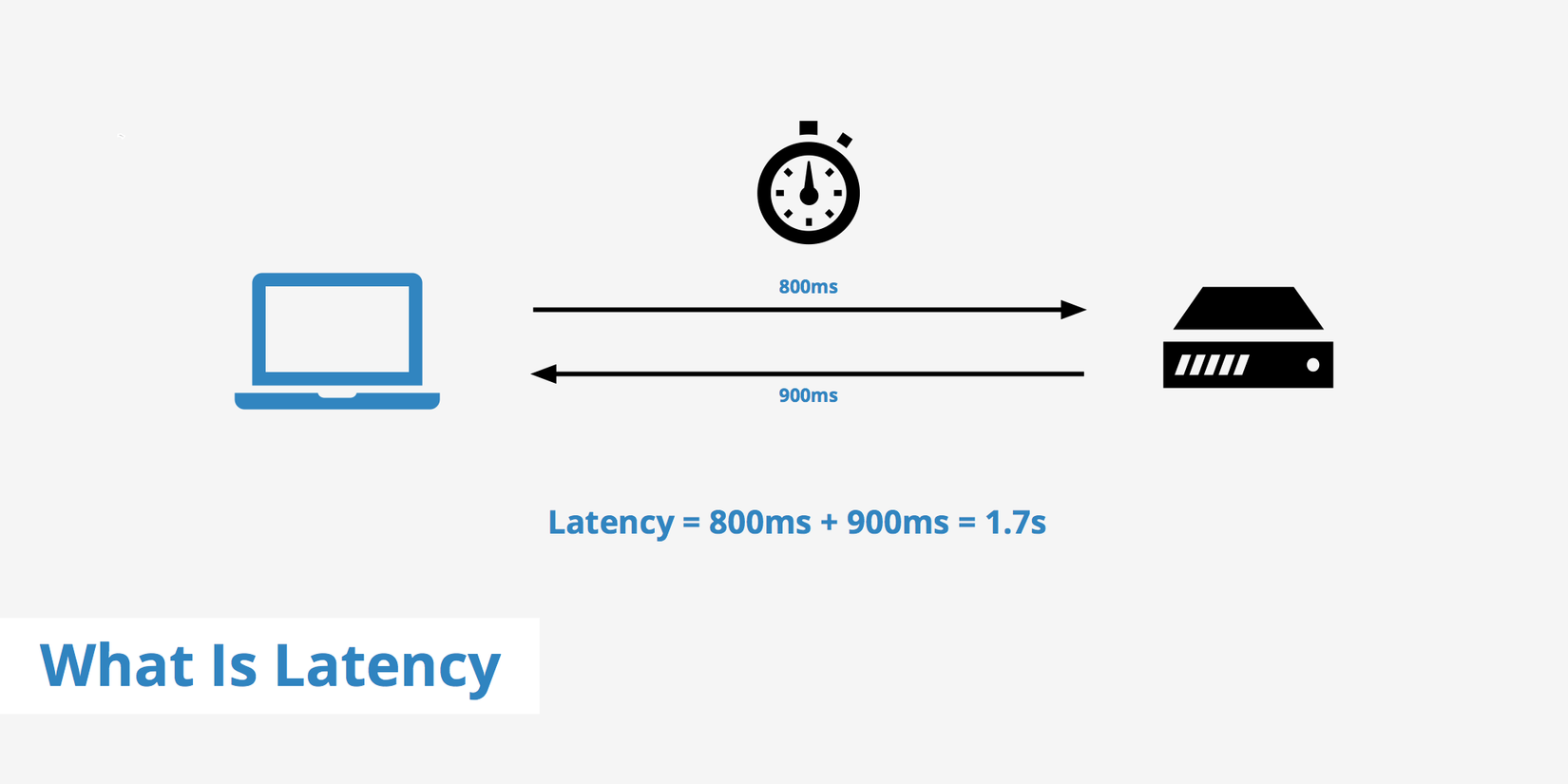
Theo 1 cách hiểu đơn giản latency được định nghĩa là thời gian để một hoạt động xảy ra. Điều này cũng có nghĩa bất kì hoạt động nào cũng có độ trễ của nó, một triệu hành động thì có một triệu latency. Do đó latency không thể đo như là số lượng đầu việc/thời gian. Điều mà chúng ta quan tâm đó là việc latency hoạt động như thế nào. Để làm điều này có ý nghĩa, chúng ta phải mô tả hoàn thiện sự phân phối của latency. Trước khi sang phần tiếp theo, hãy cùng mình ôn tập lại các khái niệm thống kê cơ bản.
Ôn tập các khái niệm về thông kê
Mean, Median, Mode

Mean
Giả sử chúng ta có dãy số 1, 2, 3. Ta có cách tính mean của 1 dãy số như sau(tổng các số hạng trong dãy số/ số số hạng trong dãy số ) => Mean = (1+2+3)/3 = 2
Median
Giả sử chúng ta có dãy số 5, 1, 2, 8 ,30. Ta có cách tính median như sau. Đầu tiên hãy sắp xếp dãy số đã cho theo thứ tự tăng dần từ trái qua phải. Sau đó duyệt các giá trị đồng thời từ 2 bên ta sẽ có 2 trường hợp xảy ra:
- Số số hạng là lẻ => sau khi duyệt đến 1 thời điểm nào đó sẽ còn 1 số chưa duyệt => số đó là giá trị median
- Số số hạng là chẳn => sau khi duyệt đến 1 thời điểm nào đó còn 2 số chưa duyệt => ta tính mean của 2 số đó => đó là giá trị median cần tìm
Với dãy số ban đầu ta có giá trị median theo cách làm trên là 5.
Mode
Giả sử chúng ta có dãy số 1, 3, 5, 5, 7, 8. Giá trị mode là giá trị của số hạng xuất hiện nhiều nhất trong dãy => Giá trị mode trong dãy chúng ta đưa ra ở trên là 5
Nếu 1 dãy có 2 mode => dãy đó gọi là bimodal Nếu dãy có nhiều hơn 2 mode => dãy đó gọi là multi-modal
Phân phối chuẩn(Normal Distribution)
Phân phối chuẩn là 1 dạng phân phối xác suất mà trong đó đồ thị dữ liệu là một dạng đối xứng qua mean. Nó chỉ ra rằng dữ liệu ở gần giá trị mean có xu hướng xảy ra thường xuyên hơn so với dữ liệu ở xa mean.
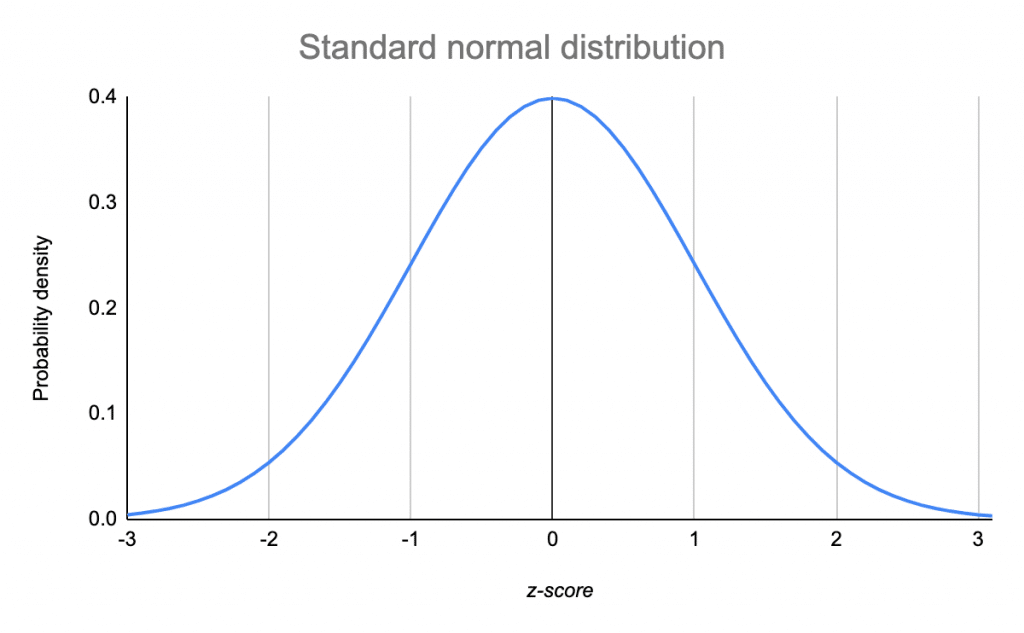
Tiếp tục với latency
Latency có xu hướng multi-modal, 1 phần của điều này do 'trục trặc'('hisccups') trong thời gian phản hổi. Trục trặc có thể xảy ra vì bất kì lí do gì, việc dừng GC, context-switches, việc bị interrupt, reindex trong database. Những trục trặc đó không bao giờ giống với phân phối chuẩn.
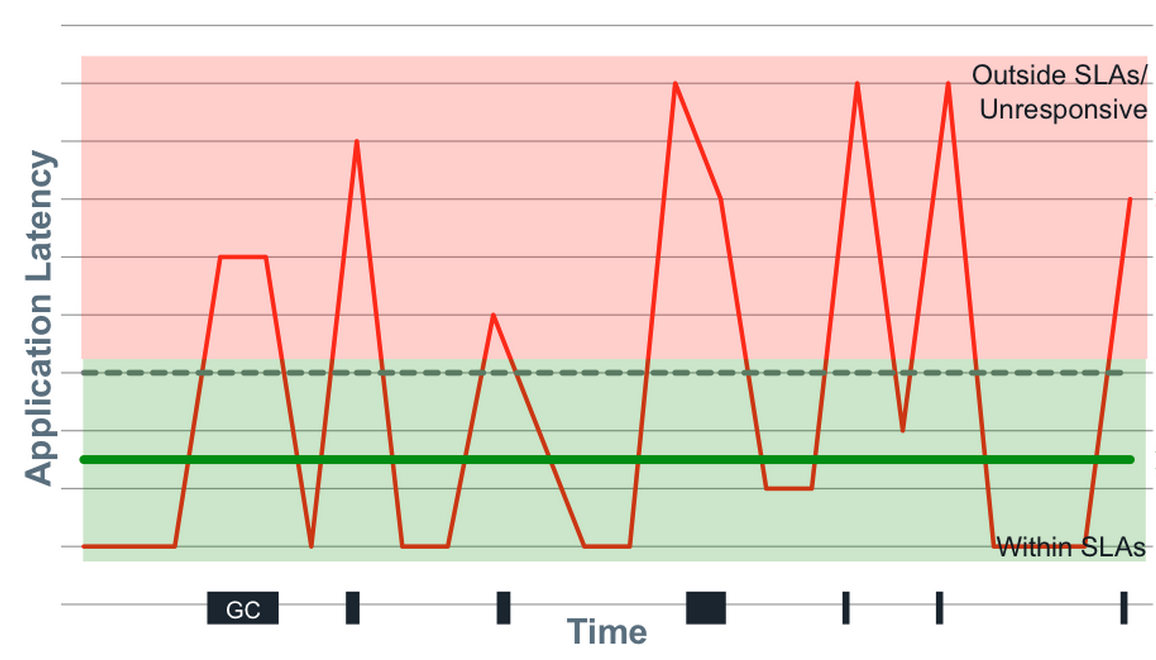
Chúng ta sẽ mô tả sự phân bố của các độ trễ này như thế nào một cách ý nghĩa? Chúng ta sẽ phải nhìn vào percentiles. Một cái bẫy mà nhiều người thằng gặp phải đó là 'trường hợp chung' (the comman case). Vấn đề ở đây đó là có nhiều latency sẽ cư xử khác với những trường hợp chung.
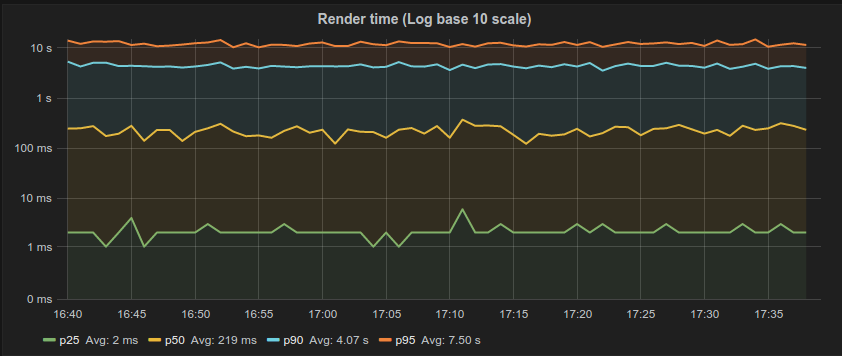
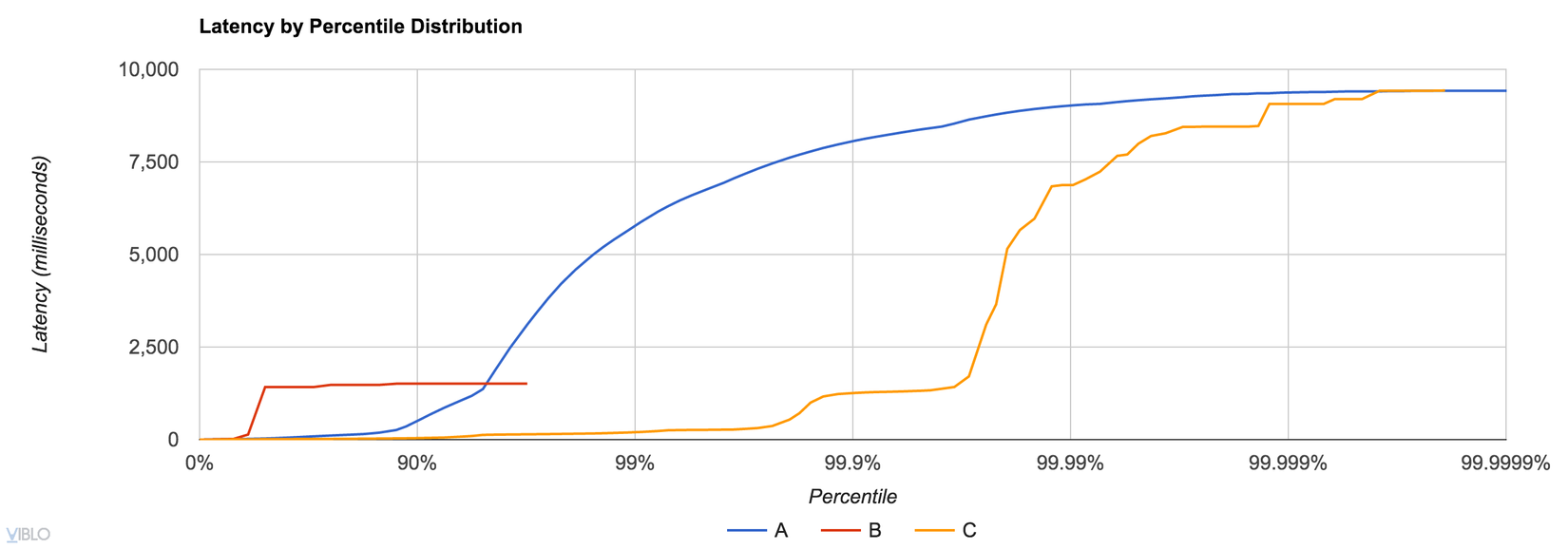
Đó cũng là một phần vấn đề của các công cụ. Nhiều công cụ chúng ta sử dụng không làm tốt trong việc capture và hiển thị dữ liệu. Ví dụ phần lớn đồ thị độ trễ được sản xuất bởi Grafana, như hình bên dưới, vễ mặt cơ bản là vô giá trị.
Latency không bao giờ theo một phân phối chuẩn, hoặc Poisson, do đó nhìn vào các giá trị như average, median, thậm chí là độ lệch chuẩn là vô dụng. Trước khi chúng ta sang phần kế tiếp hãy cũng ôn lại một số khái niệm xác suất thống kê mình vừa nêu để hiểu tại sao latency thường không phân bổ theo các dạng như vậy.
Bao nhiêu nines?
Vậy chúng ta thực sự cần bao nhiêu nines để nhìn vào ? 99th percentile theo định nghĩa là độ trễ mà 99% sự quan sát sẽ dưới mức này. Nếu chúng ta có một nút công cụ tìm kiếm, một node lưu trữ khóa-giá trị, một node cơ sở dữ liệu hoặc một node CDN, thì cơ hội chúng ta thực sự đạt đến 99th percentile là bao nhiêu?
Gil mô tả một số dữ liệu trong thế giới thực mà anh ấy thu thập được, cho biết có bao nhiêu trang web mà chúng ta truy cập thực sự thực sự đạt đến 99th percentile, được hiển thị trong bảng bên dưới. Cột thứ hai đếm số lượng yêu cầu HTTP được tạo bởi một lần truy cập trang web. đạt đến 99th percentile. Ngoại trừ google.com, mọi trang đều có xác suất nhìn thấy 99th percentile từ 50% trở lên.
 Điểm mà Gil đưa ra là 99th percentile phần lớn các trang web của bạn sẽ thấy. Nó không phải là "hiếm."
Điểm mà Gil đưa ra là 99th percentile phần lớn các trang web của bạn sẽ thấy. Nó không phải là "hiếm."
Đo lường latency
Độ trễ không tồn tại trong chân không. Đo thời gian phản hồi là điều quan trọng, nhưng bạn cần xem xét nó trong bối cảnh cuả việc tải. Nhưng làm thế nào để chúng ta đo lường đúng điều này? Khi bạn gần như rảnh rỗi, mọi thứ gần như hoàn hảo, vì vậy rõ ràng là điều đó không hữu ích cho lắm. Khi bạn đạp vào kim loại, mọi thứ sẽ rơi ra. Điều này phần nào hữu ích vì nó cho chúng ta biết chúng ta có thể đi nhanh như thế nào trước khi bắt đầu nhận được những cuộc điện thoại tức giận.
Tuy nhiên, việc nghiên cứu hành vi của độ trễ khi bão hòa cũng giống như việc xem xét hình dạng của tấm cản ô tô của bạn sau khi bọc nó quanh một cột. Điều duy nhất quan trọng khi bạn đánh vào cột là bạn đã đánh vào cột. Không có ích gì khi cố gắng thiết kế một chiếc ốp lưng tốt hơn, nhưng chúng tôi có thể thiết kế cho tốc độ mà chúng tôi mất kiểm soát. Mọi thứ sẽ trở nên bão hòa, vì vậy việc xem xét ngoài việc xác định phạm vi hoạt động của bạn sẽ không hữu ích lắm.
Điều quan trọng hơn là kiểm tra tốc độ giữa không tải và chạm cột. Xác định SLA của bạn và vẽ các yêu cầu đó, sau đó chạy các kịch bản khác nhau bằng cách sử dụng các tải khác nhau và các cấu hình khác nhau. Điều này cho chúng tôi biết liệu chúng tôi có đang đáp ứng SLA của mình hay không cũng như số lượng máy chúng tôi cần cung cấp để làm như vậy. Nếu bạn không làm điều này, bạn không biết mình cần bao nhiêu máy.
Làm thế nào để chúng ta nắm bắt dữ liệu này? Trong một thế giới lý tưởng, chúng ta có thể lưu trữ thông tin cho mọi yêu cầu, nhưng điều này thường không thực tế. HdrHistogram là một công cụ cho phép bạn nắm bắt độ trễ và giữ lại độ phân giải cao. Nó cũng bao gồm các phương tiện để điều chỉnh sự thiếu sót phối hợp và lập biểu đồ phân phối độ trễ. Phiên bản gốc của HdrHistogram được viết bằng Java, nhưng có các phiên bản cho nhiều ngôn ngữ khác.
Tổng kết
Để hiểu độ trễ, bạn phải xem xét toàn bộ phân phối. Thực hiện điều này bằng cách vẽ đường cong phân phối độ trễ. Chỉ đơn giản nhìn vào 95th percential hoặc thậm chí 99th là không đủ. Vấn đề về độ trễ đuôi. Tệ hơn nữa, giá trị trung bình không đại diện cho trường hợp “phổ biến”, trung bình thậm chí còn ít hơn. Không có chỉ số duy nhất xác định hành vi của độ trễ. Hãy chú ý đến các công cụ giám sát và đo điểm chuẩn của bạn cũng như dữ liệu mà chúng báo cáo. Bạn không thể phân tích trung bình.
Hãy nhớ rằng độ trễ không phải là thời gian phục vụ. Nếu bạn vẽ biểu đồ dữ liệu của mình với sự thiếu sót có phối hợp, đường cong thường có sự gia tăng nhanh và cao. Chạy kiểm tra “CTRL + Z” để xem bạn có gặp sự cố này không. Một bài kiểm tra không bỏ qua có một đường cong mượt mà hơn nhiều. Rất ít công cụ thực sự sửa lỗi này.
Độ trễ cần được đo trong điều kiện tải, nhưng liên tục chạy xe của bạn vào cột trong mỗi bài kiểm tra là không hữu ích. Đây không phải là cách bạn đang chạy trong sản xuất và nếu đúng như vậy, bạn có thể cần cung cấp thêm máy móc. Sử dụng nó để thiết lập giới hạn của bạn và kiểm tra thông lượng bền vững ở giữa để xác định xem bạn có đáp ứng SLA của mình hay không. Có rất nhiều công cụ còn thiếu sót, nhưng HdrHistogram là một trong số ít công cụ không có. Nó hữu ích cho việc đo điểm chuẩn và vì biểu đồ có tính chất phụ gia và HdrHistogram sử dụng nhóm nhật ký, nó cũng có thể hữu ích để thu thập dữ liệu khối lượng lớn trong quá trình sản xuất.
Tham khảo
All rights reserved
