Laravel: Url preview like Facebook with PHP Goutte
Bài đăng này đã không được cập nhật trong 4 năm
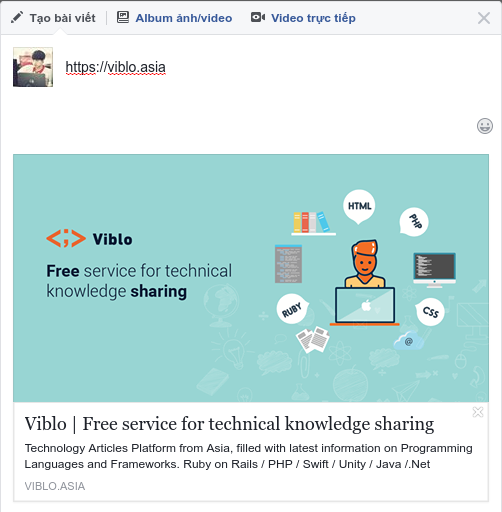
- Đây chính là chức năng xem trước url khi post bài của Facebook, thậm chí trong phần bình luận hay nhắn tin Facebook cũng cũng cấp tính năng này.
1. Vấn đề
Input:
- Thực hiện chức năng xem trước url khi người dùng viết bài hay bình luận có chứa url trong nội dung.
Output:
- Xem trước được url khi viết bài hay bình luận tương tự như Facebook, cụ thể bản xem trước phải chứa các thông tin cơ bản như url, title, description, ảnh nếu có
2. Giải pháp
- Ý tưởng: Mỗi khi người dùng viết bài ta sẽ kiểm tra xem trong nội dung bài viết có chứa url hay không, nếu có ta sẽ thực hiện lấy thông tin của website từ url đó rồi hiện thị xem trước. Ở đây mình sử dụng Laravel và thư viện
Goutteđể crawler data (lấy dữ liệu từ trang web) - Thực hiện:
- Cài đặt package Goutte bằng composer
composer require fabpot/goutte - Trước tiên để sử dụng Goutte ta cần get được url từ bài viết bằng
ajaxnhư sau:$('.post').change(function() { var content = $(this).val(); $.ajax({ url: '/previewUrl/', type: 'GET', data: { content: content, }, success: function (response) { // } }); }); - Trên server ta sẽ dùng hàm
preg_match_allcủa php để check content có chứa url hay không:public function previewUrl() { $content = request()->content; $urls = preg_match_all('#\bhttps?://[^,\s()<>]+(?:\([\w\d]+\)|([^,[:punct:]\s]|/))#', $content, $match); $results = []; if ($urls > 0) { $url = $match[0][0]; // } } $match[0]là mảng các url trong các bài viết, nhưng nếu các bạn để ý thì sẽ thấy Facebook chỉ hiển thị xem trước của url đầu tiên trong bài viết, nên ở đây ta lấy url đầu tiên$match[0][0]- Sử dụng Goutte crawler data: ta cần include thư viện Goutte, định nghĩa object Client và thực hiện gửi request đến website cần lấy thông tin, ta sẽ thu được một object
$crawlernhư sau:use Goutte\Client; $url = $match[0][0]; $client = new Client(); $crawler = $client->request('GET', $url); - Trước khi thực hiện get data ta cần đảm bảo url là hợp lệ, tức là status code trả về phải là 200, kiểm tra như sau:
$status_code = $client->getResponse()->getStatus(); if ($status_code == 200) { //process the documents } - Tiếp theo ta sẽ lấy các thông tin cần thiết như
title,description,imagetừ các thẻ meta tag, ở đây ta có thể dùng hàm get_meta_tags của php, nhưng hàm này chỉ get được data từ các thẻ meta, vì thế ta sẽ dùngGoutteđể đảm bảo get được data từ các thẻ khác. - Ta lấy
titlenhư sau:$crawler->filterXPath('html/head/title')->text(); // hay như sau: // $crawler->filter('title')->text(); - Hoặc ta cũng có thể làm như sau:
$crawler->filterXpath('//meta[@name="title"]')->attr('content'); - Tương tự với
descriptionvàimage:$description = $crawler->filterXpath('//meta[@name="description"]')->attr('content'); $image = $crawler->filterXpath('//meta[@name="og:image"]')->attr('content'); - Thông thường để tối ưu hóa nhất cho việc SEO web thì các website sẽ có đầy đủ các thẻ meta như
title,description,image.. nhưng để tránh trường hợp website không có đầy đủ các thẻ sẽ phát sinh lỗi, ta sẽ thêm đoạn check xem có meta tag hay không trước khi get data:if ($crawler->filterXpath('//meta[@name="description"]')->count()) { $description = $crawler->filterXpath('//meta[@name="description"]')->attr('content'); } - Trường hợp website không có thẻ meta image nhưng ta lại vẫn muốn hiện thị một image bất kỳ trong website thay vì không hiển thị gì, khi đó ta sẽ tìm một image khác như sau:
if ($crawler->filter('img')->count()) { $image = $crawler->filter('img')->attr('src'); } - Ngoài cá phương thức
filter,filterXpath,..Gouttecòn cung cấp thêm nhiều phương thức khác hữu ích trong việc crawler data, để tìm hiểu kỹ hơn ta có thể tham khảo documment BrowserKit, DomCrawler - Đến đây phần xử lý server đã xong, ta sẽ có method
previewUrl()như sau:public function previewUrl() { $content = request()->content; $urls = preg_match_all('#\bhttps?://[^,\s()<>]+(?:\([\w\d]+\)|([^,[:punct:]\s]|/))#', $content, $match); $results = []; if ($urls > 0) { $url = $match[0][0]; $client = new Client(); try { $crawler = $client->request('GET', $url); $statusCode = $client->getResponse()->getStatus(); if ($statusCode == 200) { $title = $crawler->filter('title')->text(); if ($crawler->filterXpath('//meta[@name="description"]')->count()) { $description = $crawler->filterXpath('//meta[@name="description"]')->attr('content'); } if ($crawler->filterXpath('//meta[@name="og:image"]')->count()) { $image = $crawler->filterXpath('//meta[@name="og:image"]')->attr('content'); } elseif ($crawler->filterXpath('//meta[@name="twitter:image"]')->count()) { $image = $crawler->filterXpath('//meta[@name="twitter:image"]')->attr('content'); } else { if ($crawler->filter('img')->count()) { $image = $crawler->filter('img')->attr('src'); } else { $image = 'no_image'; } } $results['title'] = $title; $results['url'] = $url; $results['host'] = parse_url($url)['host']; $results['description'] = isset($description) ? $description : ''; $results['image'] = $image; } catch (/Exception $e) { // log } } } if (count($results) > 0) { return response()->json(['success' => true, 'data' => $results]); } return response()->json(['success' => false, 'data' => $results]); } - Đoạn
try .. catch ..ta cần thêm vào để tránh trường hợp người dùng nhập url không hợp lệ sẽ phát sinh lỗicURL error 6: Could not resolve host - Phần còn lại ta chỉ cần tạo ra một view để hiển thị ra các data đã get được, chẳng hạn như sau:
$('.post').change(function() { var content = $(this).val(); $.ajax({ url: '/previewUrl/', type: 'GET', data: { content: content, }, success: function (response) { if (response.success) { var data = response.data; var preview = '<div class="row">' + '<div class="col-md-3">' + '<div style="background: #999;">' + '<img src="' + data.image + '" width="150" height="auto">' + '</div>' + '</div>' + '<div class="col-md-9">' + '<div class="row url-title">' + '<a href="' + data.url + '">' + data.title + '</a>' + '</div>' + '<div class="row url-link">' + '<a href="' + data.url + '">' + data.host + '</a>' + '</div>' + '<div class="row url-description">' + data.description + '</div>' + '</div>' + '</div>'; $('.urlPreview .row').remove(); $('.urlPreview').append(preview); } } }); }); - Kết quả thu được như sau:

- Trên đây là cách mình dùng
Goutteđể giải quyết vấn đề, ngoài ra bạn cũng có thể tham khảo cách sau: Extract URL content like Facebook with PHP and jQuery
- Cài đặt package Goutte bằng composer
Tài liệu tham khảo Simple web spider with PHP Goutte https://github.com/FriendsOfPHP/Goutte
All rights reserved
