Kỹ thuật quản lý Context trong AI
1. Sequential Processing (Xử lý tuần tự)
Giới thiệu
Sequential Processing là kỹ thuật cơ bản nhất trong xử lý ngôn ngữ tự nhiên, nơi mô hình xử lý văn bản theo thứ tự từ đầu đến cuối mà không có bất kỳ tối ưu hóa nào về bộ nhớ hay context.
Cách thức hoạt động
- Mô hình đọc toàn bộ input từ token đầu tiên đến token cuối cùng
- Mỗi token được xử lý theo thứ tự tuyến tính
- Không có cơ chế loại bỏ hay nén thông tin cũ
- Context window có kích thước cố định
Ưu điểm
- Triển khai đơn giản: Không cần thuật toán phức tạp
- Dễ debug: Luồng xử lý rõ ràng, dễ theo dõi
- Không mất thông tin: Giữ nguyên toàn bộ context trong giới hạn cho phép
Nhược điểm
- Chi phí rất cao: Phải xử lý toàn bộ context mỗi lần
- Giới hạn độ dài: Không thể xử lý văn bản quá dài
- Không hiệu quả: Lãng phí tài nguyên tính toán
Sơ đồ minh họa
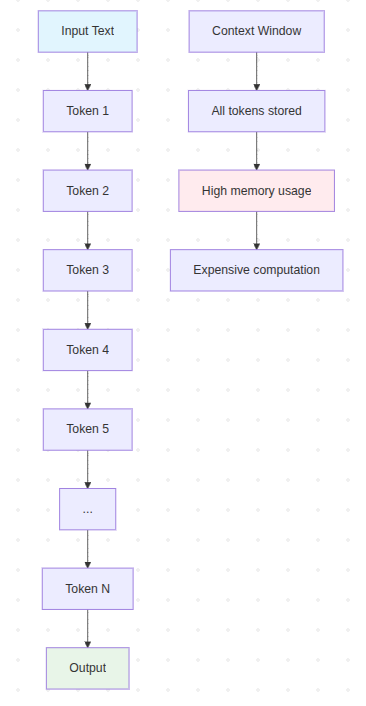
graph TD
A[Input Text] --> B[Token 1]
B --> C[Token 2]
C --> D[Token 3]
D --> E[Token 4]
E --> F[Token 5]
F --> G[...]
G --> H[Token N]
H --> I[Output]
J[Context Window] --> K[All tokens stored]
K --> L[High memory usage]
L --> M[Expensive computation]
style A fill:#e1f5fe
style I fill:#e8f5e8
style L fill:#ffebee
Ví dụ thực tế
# Pseudo-code minh họa Sequential Processing
def sequential_processing(text):
tokens = tokenize(text)
context = []
for token in tokens:
context.append(token) # Lưu tất cả tokens
if len(context) > MAX_CONTEXT_LENGTH:
raise ContextLengthError("Context quá dài!")
# Xử lý toàn bộ context
output = model.process(context)
return output
Khi nào sử dụng
- Ứng dụng đơn giản với văn bản ngắn
- Khi cần độ chính xác cao và không quan tâm đến hiệu suất
- Giai đoạn prototype và testing
- Khi tài nguyên tính toán không phải là vấn đề
2. Sliding Window (Cửa sổ trượt)
Giới thiệu
Sliding Window là kỹ thuật tối ưu hóa đầu tiên, giúp xử lý văn bản dài bằng cách duy trì một "cửa sổ" có kích thước cố định và trượt qua văn bản.
Cách thức hoạt động
- Duy trì một context window có kích thước cố định (VD: 2048 tokens)
- Khi thêm token mới, loại bỏ token cũ nhất
- Chỉ xử lý tokens trong cửa sổ hiện tại
- Giảm đáng kể chi phí tính toán
Ưu điểm
- Hiệu quả chi phí: Giảm đáng kể memory và computation
- Xử lý văn bản dài: Có thể xử lý input không giới hạn
- Triển khai đơn giản: Dễ implement và maintain
Nhược điểm
- Mất ngữ cảnh cũ: Không nhớ thông tin ở đầu cuộc trò chuyện
- Discontinuity: Có thể mất mạch logic giữa các phần
Sơ đồ minh họa
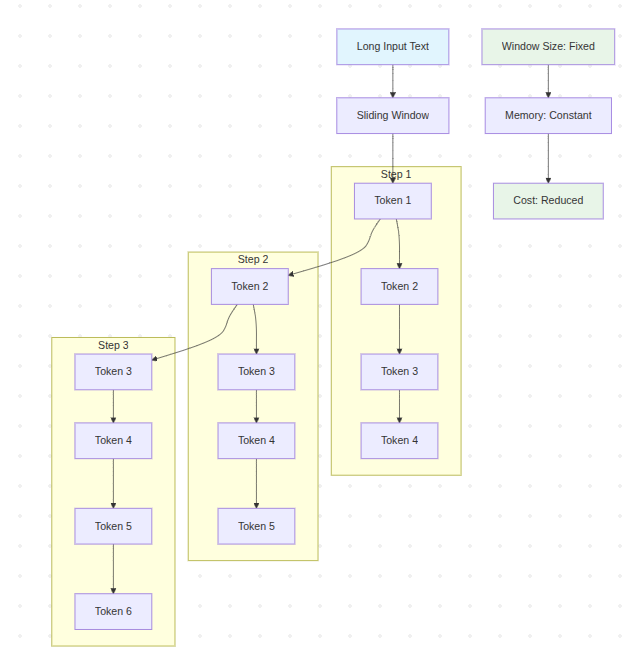
graph TD
A[Long Input Text] --> B[Sliding Window]
subgraph "Step 1"
C[Token 1] --> D[Token 2]
D --> E[Token 3]
E --> F[Token 4]
end
subgraph "Step 2"
G[Token 2] --> H[Token 3]
H --> I[Token 4]
I --> J[Token 5]
end
subgraph "Step 3"
K[Token 3] --> L[Token 4]
L --> M[Token 5]
M --> N[Token 6]
end
B --> C
C --> G
G --> K
O[Window Size: Fixed] --> P[Memory: Constant]
P --> Q[Cost: Reduced]
style A fill:#e1f5fe
style O fill:#e8f5e8
style Q fill:#e8f5e8
Ví dụ thực tế
from collections import deque
def sliding_window_processing(text, window_size=2048):
tokens = tokenize(text)
window = deque(maxlen=window_size)
outputs = []
for token in tokens:
window.append(token)
# Xử lý window hiện tại
if len(window) == window_size:
output = model.process(list(window))
outputs.append(output)
return outputs
Khi nào sử dụng
- Ứng dụng chat với cuộc trò chuyện dài
- Xử lý document lớn
- Khi cần cân bằng giữa hiệu suất và chất lượng
- Hệ thống có giới hạn về tài nguyên
3. Summarization (Tóm tắt)
Giới thiệu
Summarization là kỹ thuật nén thông tin cũ thành các summary ngắn gọn, giúp giảm token usage trong khi vẫn bảo tồn thông tin quan trọng.
Cách thức hoạt động
- Khi context gần đầy, tóm tắt phần đầu thành summary
- Kết hợp summary với context gần đây
- Sử dụng LLM để tạo summary chất lượng cao
- Có thể tạo summary đa cấp (hierarchical)
Ưu điểm
- Tiết kiệm token: Giảm đáng kể số token cần xử lý
- Bảo tồn thông tin: Giữ lại essence của cuộc trò chuyện
- Linh hoạt: Có thể điều chỉnh độ chi tiết của summary
Nhược điểm
- Mất chi tiết: Một số thông tin cụ thể có thể bị mất
- Chất lượng summary: Phụ thuộc vào khả năng tóm tắt của model
- Overhead: Cần thêm computational cost để tạo summary
Sơ đồ minh họa
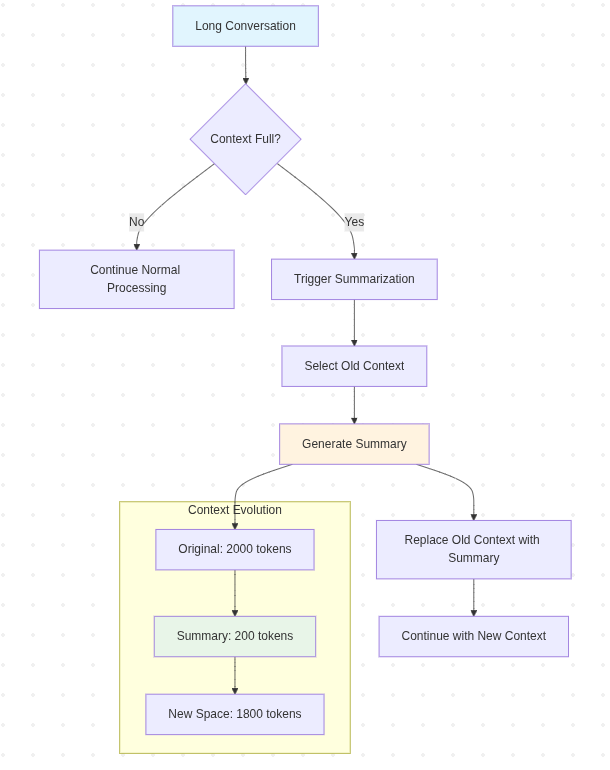
graph TD
A[Long Conversation] --> B{Context Full?}
B -->|No| C[Continue Normal Processing]
B -->|Yes| D[Trigger Summarization]
D --> E[Select Old Context]
E --> F[Generate Summary]
F --> G[Replace Old Context with Summary]
G --> H[Continue with New Context]
subgraph "Context Evolution"
I[Original: 2000 tokens] --> J[Summary: 200 tokens]
J --> K[New Space: 1800 tokens]
end
F --> I
style A fill:#e1f5fe
style F fill:#fff3e0
style J fill:#e8f5e8
Ví dụ thực tế
def summarization_processing(messages, max_context=2000):
current_context = []
for message in messages:
current_context.append(message)
# Kiểm tra context length
if count_tokens(current_context) > max_context:
# Tách old context và recent context
old_context = current_context[:-10] # Trừ 10 tin nhắn gần nhất
recent_context = current_context[-10:]
# Tóm tắt old context
summary = model.summarize(old_context)
# Tái cấu trúc context
current_context = [summary] + recent_context
return model.process(current_context)
Khi nào sử dụng
- Cuộc trò chuyện dài với nhiều chủ đề
- Khi cần giữ tổng quan nhưng tiết kiệm token
- Ứng dụng customer service
- Document analysis với summary layers
4. Retrieval-Based Context (RAG)
Giới thiệu
Retrieval-Based Context hay RAG (Retrieval-Augmented Generation) là kỹ thuật advanced tìm kiếm và truy xuất thông tin relevant từ knowledge base để bổ sung vào context.
Cách thức hoạt động
- Tạo vector embeddings cho toàn bộ knowledge base
- Khi có query, tìm kiếm các chunks relevant nhất
- Inject retrieved information vào context
- Model xử lý với context được augment
Ưu điểm
- Context cực kỳ relevant: Chỉ lấy thông tin cần thiết
- Scalable: Có thể xử lý knowledge base rất lớn
- Up-to-date: Dễ cập nhật knowledge base
- Giảm hallucination: Có nguồn thông tin cụ thể
Nhược điểm
- Implementation phức tạp: Cần vector database, embedding model
- Dependency: Phụ thuộc vào chất lượng retrieval
- Latency: Thêm bước search có thể làm chậm
Sơ đồ minh họa
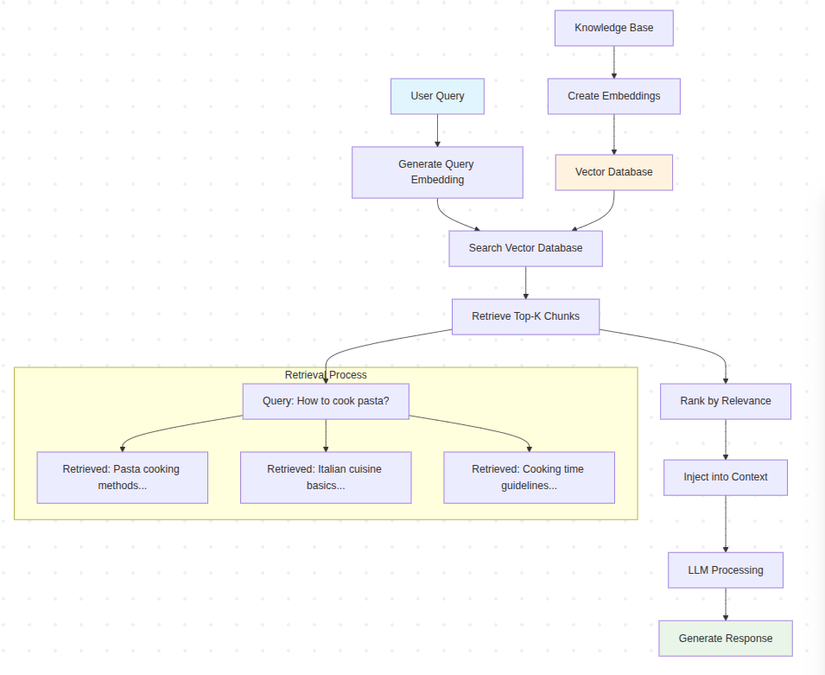
graph TD
A[User Query] --> B[Generate Query Embedding]
B --> C[Search Vector Database]
C --> D[Retrieve Top-K Chunks]
D --> E[Rank by Relevance]
E --> F[Inject into Context]
F --> G[LLM Processing]
G --> H[Generate Response]
I[Knowledge Base] --> J[Create Embeddings]
J --> K[Vector Database]
K --> C
subgraph "Retrieval Process"
L[Query: "How to cook pasta?"]
M[Retrieved: "Pasta cooking methods..."]
N[Retrieved: "Italian cuisine basics..."]
O[Retrieved: "Cooking time guidelines..."]
end
D --> L
L --> M
L --> N
L --> O
style A fill:#e1f5fe
style H fill:#e8f5e8
style K fill:#fff3e0
Ví dụ thực tế
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
class RAGSystem:
def __init__(self, knowledge_base):
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
self.knowledge_base = knowledge_base
self.build_index()
def build_index(self):
# Tạo embeddings cho knowledge base
embeddings = self.encoder.encode(self.knowledge_base)
# Tạo FAISS index
self.index = faiss.IndexFlatL2(embeddings.shape[1])
self.index.add(embeddings.astype('float32'))
def retrieve(self, query, top_k=5):
# Encode query
query_embedding = self.encoder.encode([query])
# Search
distances, indices = self.index.search(
query_embedding.astype('float32'), top_k
)
# Return relevant chunks
return [self.knowledge_base[i] for i in indices[0]]
def generate_response(self, query):
# Retrieve relevant context
relevant_chunks = self.retrieve(query)
# Build context
context = "Context:\n" + "\n".join(relevant_chunks)
full_prompt = f"{context}\n\nQuestion: {query}\nAnswer:"
# Generate response
return llm.generate(full_prompt)
Khi nào sử dụng
- Ứng dụng Q&A với knowledge base lớn
- Customer support với manual/documentation
- Research assistant
- Khi cần thông tin factual và up-to-date
5. Memory-Augmented Transformers
Giới thiệu
Memory-Augmented Transformers là kỹ thuật advanced sử dụng external memory để lưu trữ và truy xuất thông tin quan trọng, giúp model "nhớ" được các facts và events quan trọng.
Cách thức hoạt động
- Sử dụng external memory bank để lưu trữ thông tin
- Mechanism để write/read từ memory
- Attention mechanism để quyết định thông tin nào cần nhớ
- Selective forgetting để tránh memory overflow
Ưu điểm
- Nhớ facts quan trọng: Không bị mất thông tin critical
- Selective memory: Chỉ nhớ những gì quan trọng
- Long-term consistency: Duy trì consistency qua nhiều turns
Nhược điểm
- Chi phí cao: Cần additional calls để manage memory
- Complexity: Implementation và tuning phức tạp
- Memory management: Cần strategy để quản lý memory
Sơ đồ minh họa
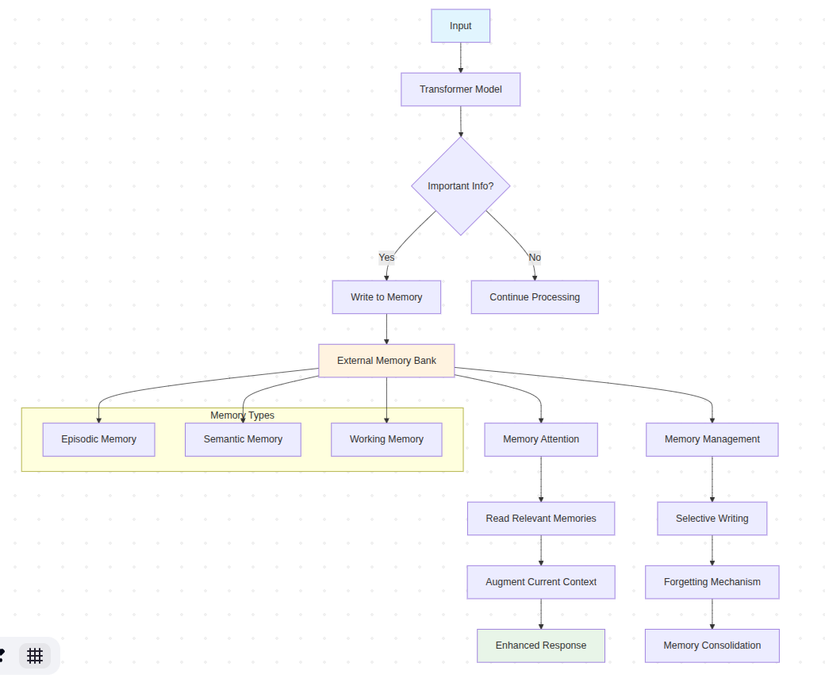
graph TD
A[Input] --> B[Transformer Model]
B --> C{Important Info?}
C -->|Yes| D[Write to Memory]
C -->|No| E[Continue Processing]
D --> F[External Memory Bank]
F --> G[Memory Attention]
G --> H[Read Relevant Memories]
H --> I[Augment Current Context]
I --> J[Enhanced Response]
K[Memory Management] --> L[Selective Writing]
L --> M[Forgetting Mechanism]
M --> N[Memory Consolidation]
F --> K
subgraph "Memory Types"
O[Episodic Memory]
P[Semantic Memory]
Q[Working Memory]
end
F --> O
F --> P
F --> Q
style A fill:#e1f5fe
style J fill:#e8f5e8
style F fill:#fff3e0
Ví dụ thực tế
class MemoryAugmentedTransformer:
def __init__(self):
self.episodic_memory = {} # Lưu events
self.semantic_memory = {} # Lưu facts
self.working_memory = [] # Context hiện tại
self.memory_threshold = 0.8 # Threshold để lưu memory
def process_input(self, input_text):
# Phân tích input
importance_score = self.calculate_importance(input_text)
# Lưu vào memory nếu quan trọng
if importance_score > self.memory_threshold:
self.store_memory(input_text, importance_score)
# Retrieve relevant memories
relevant_memories = self.retrieve_memories(input_text)
# Augment context
augmented_context = self.working_memory + relevant_memories
# Generate response
response = self.generate_response(augmented_context)
return response
def store_memory(self, text, importance):
memory_type = self.classify_memory_type(text)
if memory_type == "episodic":
self.episodic_memory[len(self.episodic_memory)] = {
'content': text,
'importance': importance,
'timestamp': time.time()
}
elif memory_type == "semantic":
key = self.extract_key_concept(text)
self.semantic_memory[key] = text
def retrieve_memories(self, query):
# Tìm kiếm trong cả episodic và semantic memory
relevant_memories = []
# Search episodic memory
for memory in self.episodic_memory.values():
if self.calculate_similarity(query, memory['content']) > 0.7:
relevant_memories.append(memory['content'])
# Search semantic memory
for concept, content in self.semantic_memory.items():
if concept in query.lower():
relevant_memories.append(content)
return relevant_memories[:5] # Top 5 memories
Khi nào sử dụng
- Ứng dụng cần nhớ thông tin user lâu dài
- Personal assistant
- Educational applications
- Complex reasoning tasks
6. Hierarchical Context Management
Giới thiệu
Hierarchical Context Management tổ chức thông tin theo cấu trúc phân cấp, với các levels khác nhau của abstraction và detail.
Cách thức hoạt động
- Tạo hierarchy của context: global → topic → local
- Mỗi level có độ chi tiết khác nhau
- Dynamic routing giữa các levels
- Intelligent context switching
Ưu điểm
- Hybrid approach: Kết hợp nhiều strategies
- Sophisticated: Xử lý complex scenarios
- Flexible: Adapt theo tình huống
Nhược điểm
- Phức tạp: Khó implement và maintain
- Tuning: Cần fine-tuning nhiều parameters
- Overhead: Management complexity
Sơ đồ minh họa
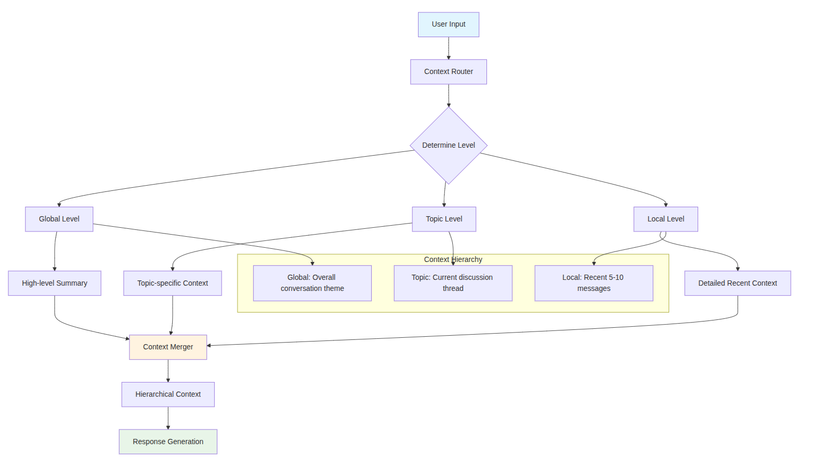
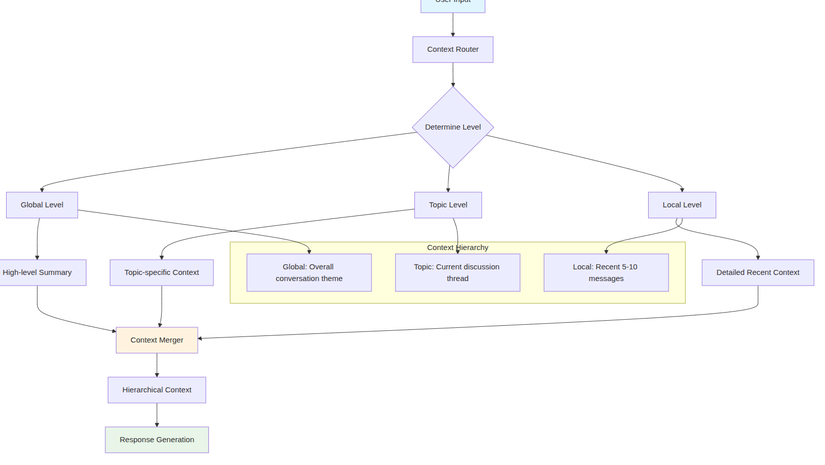
graph TD
A[User Input] --> B[Context Router]
B --> C{Determine Level}
C --> D[Global Level]
C --> E[Topic Level]
C --> F[Local Level]
D --> G[High-level Summary]
E --> H[Topic-specific Context]
F --> I[Detailed Recent Context]
G --> J[Context Merger]
H --> J
I --> J
J --> K[Hierarchical Context]
K --> L[Response Generation]
subgraph "Context Hierarchy"
M[Global: Overall conversation theme]
N[Topic: Current discussion thread]
O[Local: Recent 5-10 messages]
end
D --> M
E --> N
F --> O
style A fill:#e1f5fe
style L fill:#e8f5e8
style J fill:#fff3e0
Khi nào sử dụng
- Complex multi-topic conversations
- Enterprise applications
- Advanced AI assistants
- Research và development
7. Graph-Based Context
Giới thiệu
Graph-Based Context modeling thông tin như một graph với nodes (entities) và edges (relationships), giúp hiểu được mối quan hệ phức tạp giữa các thông tin.
Cách thức hoạt động
- Extract entities và relationships từ text
- Build knowledge graph
- Traverse graph để tìm relevant information
- Update graph với thông tin mới
Ưu điểm
- Hiểu relationships: Nắm được mối quan hệ phức tạp
- Reasoning: Có thể suy luận logic
- Rich context: Thông tin được kết nối có ý nghĩa
Nhược điểm
- Khó populate: Cần effort để build graph
- Maintenance: Cập nhật graph phức tạp
- Performance: Graph operations có thể chậm
Sơ đồ minh họa
graph TD
A[Text Input] --> B[Entity Extraction]
B --> C[Relationship Extraction]
C --> D[Knowledge Graph]
D --> E[Graph Traversal]
E --> F[Relevant Subgraph]
F --> G[Context Generation]
G --> H[Response]
subgraph "Knowledge Graph"
I[Person: John]
J[Company: ABC Corp]
K[Role: Manager]
L[Project: XYZ]
I --> J
I --> K
J --> L
K --> L
end
D --> I
subgraph "Graph Operations"
M[Add Node]
N[Add Edge]
O[Update Properties]
P[Remove Outdated]
end
D --> M
style A fill:#e1f5fe
style H fill:#e8f5e8
style D fill:#fff3e0
Ví dụ thực tế
import networkx as nx
from typing import Dict, List, Tuple
class GraphBasedContext:
def __init__(self):
self.graph = nx.DiGraph()
self.entity_types = {}
def extract_entities(self, text):
# Sử dụng NER model để extract entities
# Trả về: [(entity, type), ...]
pass
def extract_relationships(self, text, entities):
# Extract relationships giữa entities
# Trả về: [(entity1, relationship, entity2), ...]
pass
def update_graph(self, text):
entities = self.extract_entities(text)
relationships = self.extract_relationships(text, entities)
# Add entities as nodes
for entity, entity_type in entities:
self.graph.add_node(entity, type=entity_type)
self.entity_types[entity] = entity_type
# Add relationships as edges
for subj, rel, obj in relationships:
self.graph.add_edge(subj, obj, relation=rel)
def find_relevant_context(self, query):
query_entities = self.extract_entities(query)
relevant_nodes = set()
# Find direct matches
for entity, _ in query_entities:
if entity in self.graph:
relevant_nodes.add(entity)
# Add neighbors
neighbors = list(self.graph.neighbors(entity))
relevant_nodes.update(neighbors[:5]) # Top 5 neighbors
# Create subgraph
subgraph = self.graph.subgraph(relevant_nodes)
# Convert to context
context_parts = []
for node in subgraph.nodes():
node_info = f"{node} (type: {self.entity_types.get(node, 'unknown')})"
context_parts.append(node_info)
# Add relationships
for neighbor in subgraph.neighbors(node):
edge_data = subgraph[node][neighbor]
relation = edge_data.get('relation', 'related_to')
context_parts.append(f" {relation} {neighbor}")
return "\n".join(context_parts)
Khi nào sử dụng
- Knowledge-intensive applications
- Complex domain với nhiều entities
- Khi cần reasoning về relationships
- Research và analysis tools
8. Compression & Consolidation
Giới thiệu
Compression & Consolidation là kỹ thuật nén và hợp nhất thông tin để tối ưu hóa token usage trong khi vẫn giữ được essence của information.
Cách thức hoạt động
- Identify redundant information
- Merge similar concepts
- Compress verbose descriptions
- Maintain key information integrity
Ưu điểm
- Cực kỳ tiết kiệm token: Tối ưu hóa tối đa token usage
- Maintain essence: Giữ được thông tin quan trọng
- Scalable: Có thể áp dụng recursive
Nhược điểm
- Mất nuance: Có thể mất đi subtle details
- Compression artifacts: Thông tin có thể bị distorted
- Complexity: Cần sophisticated compression logic
Sơ đồ minh họa
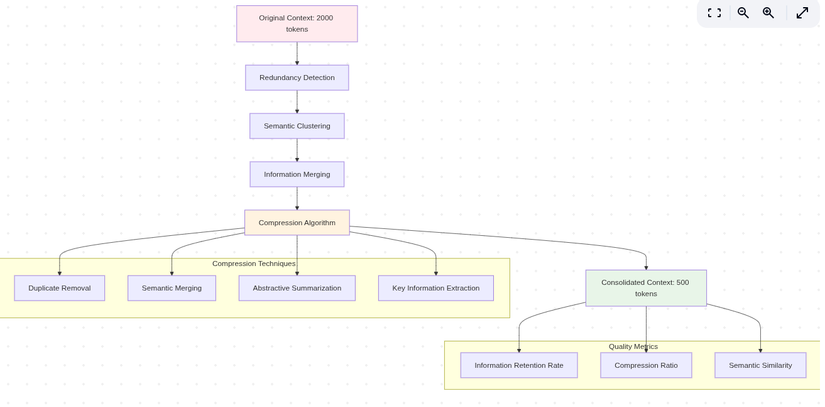
graph TD
A[Original Context: 2000 tokens] --> B[Redundancy Detection]
B --> C[Semantic Clustering]
C --> D[Information Merging]
D --> E[Compression Algorithm]
E --> F[Consolidated Context: 500 tokens]
subgraph "Compression Techniques"
G[Duplicate Removal]
H[Semantic Merging]
I[Abstractive Summarization]
J[Key Information Extraction]
end
E --> G
E --> H
E --> I
E --> J
subgraph "Quality Metrics"
K[Information Retention Rate]
L[Compression Ratio]
M[Semantic Similarity]
end
F --> K
F --> L
F --> M
style A fill:#ffebee
style F fill:#e8f5e8
style E fill:#fff3e0
Ví dụ thực tế
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import numpy as np
class CompressionConsolidation:
def __init__(self):
self.vectorizer = TfidfVectorizer(max_features=1000)
self.similarity_threshold = 0.8
def compress_context(self, messages):
# Step 1: Remove exact duplicates
unique_messages = self.remove_duplicates(messages)
# Step 2: Semantic clustering
clusters = self.semantic_clustering(unique_messages)
# Step 3: Consolidate each cluster
consolidated = []
for cluster in clusters:
consolidated_message = self.consolidate_cluster(cluster)
consolidated.append(consolidated_message)
# Step 4: Final compression
compressed = self.final_compression(consolidated)
return compressed
def remove_duplicates(self, messages):
seen = set()
unique = []
for msg in messages:
msg_hash = hash(msg.strip().lower())
if msg_hash not in seen:
seen.add(msg_hash)
unique.append(msg)
return unique
def semantic_clustering(self, messages):
if len(messages) <= 1:
return [messages]
# Vectorize messages
tfidf_matrix = self.vectorizer.fit_transform(messages)
# Determine optimal number of clusters
n_clusters = min(len(messages) // 2, 10)
# Perform clustering
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
clusters = kmeans.fit_predict(tfidf_matrix)
# Group messages by cluster
grouped = {}
for i, cluster_id in enumerate(clusters):
if cluster_id not in grouped:
grouped[cluster_id] = []
grouped[cluster_id].append(messages[i])
return list(grouped.values())
def consolidate_cluster(self, cluster_messages):
if len(cluster_messages) == 1:
return cluster_messages[0]
# Find common themes
all_words = " ".join(cluster_messages).split()
word_freq = {}
for word in all_words:
word_freq[word] = word_freq.get(word, 0) + 1
# Extract key information
key_info = []
for msg in cluster_messages:
# Extract unique information from each message
unique_parts = self.extract_unique_info(msg, cluster_messages)
key_info.extend(unique_parts)
# Combine into consolidated message
consolidated = " | ".join(set(key_info))
return consolidated
def extract_unique_info(self, message, all_messages):
# Simple extraction - in practice, use more sophisticated NLP
words = message.split()
unique_words = []
for word in words:
if len(word) > 3: # Skip short words
count_in_others = sum(1 for other in all_messages if other != message and word in other)
if count_in_others < len(all_messages) - 1:
unique_words.append(word)
return unique_words[:10] # Top 10 unique words
def final_compression(self, messages):
# Apply final compression techniques
compressed = []
for msg in messages:
# Remove redundant phrases
compressed_msg = self.remove_redundancy(msg)
# Shorten if too long
if len(compressed_msg) > 100:
compressed_msg = compressed_msg[:100] + "..."
compressed.append(compressed_msg)
return compressed
def remove_redundancy(self, text):
# Remove repeated phrases and words
words = text.split()
seen = set()
result = []
for word in words:
if word.lower() not in seen:
seen.add(word.lower())
result.append(word)
return " ".join(result)
Khi nào sử dụng
- Khi có rất nhiều redundant information
- Long conversations với repeated themes
- Token budget rất limited
Cảm ơn các bạn đã reading, nắm bắt context ta có câu trả lời chính xác , tránh ảo giác của AI 😀
All rights reserved
