Kiến trúc Microservices
1. Tổng quan
Kiến trúc microservices là một mô hình tổ chức hệ thống phần mềm, trong đó ứng dụng được phân rã thành tập hợp các dịch vụ nhỏ, tự trị và hoạt động độc lập. Mỗi dịch vụ được thiết kế xoay quanh một chức năng nghiệp vụ cụ thể, duy trì cơ sở dữ liệu riêng và giao tiếp với các dịch vụ khác thông qua giao thức truyền thông nhẹ.
Cách tiếp cận này hướng đến việc nâng cao khả năng mở rộng, tính linh hoạt trong phát triển, cũng như khả năng bảo trì và triển khai liên tục của hệ thống phần mềm hiện đại.
Kiến trúc microservices lấy cảm hứng từ domain-driven design (hay DDD) - một phương pháp thiết kế phần mềm.
Thay vì chỉ tập trung vào công nghệ, DDD giúp mô hình hóa phần mềm xoay quanh những khái niệm cốt lõi của nghiệp vụ, nhờ đó tạo ra một kiến trúc không chỉ phản ánh chính xác nhu cầu thực tế mà còn dễ dàng thích ứng với các thay đổi sau này.
Khái niệm Bounded Context của DDD đã truyền cảm hứng cho các nhà phát triển kiến trúc microservices. Khi phát triển một miền nghiệp vụ (domain), các dịch vụ sẽ bao gồm toàn bộ thực thể (entity) và hành vi (behavior) liên quan đến miền nghiệp vụ đó - trong trường hợp này là code và database. Điều này đồng nghĩa các dịch vụ sẽ được phát triển độc lập và giảm phụ thuộc lẫn nhau.
Tại sao cần giảm phụ thuộc ?
Khi phát triển ứng dụng monolith, các thành phần (class, entity, database) sẽ được tái sử dụng (reuse) trong toàn bộ dự án. Nếu ngữ cảnh nghiệp vụ không rõ ràng, các thành phần có thể phụ thuộc lẫn nhau trong quá trình phát triển và dẫn đến việc khó bảo trì.
The negative trade-of of reuse is coupling
Hơn nữa, lợi thế của kiến trúc microservices nằm ở việc nó duy trì các đơn vị phát triển (development-unit) và đơn vị triển khai (deployment-unit) nhỏ và độc lập. Điều này khiến các dịch vụ trở nên dễ dàng quản lý và triển khai.
Tuy nhiên, kiến trúc microservices không phải luôn tối ưu trong mọi trường hợp. Nó sẽ phù hợp trong các bài toán lớn và cần tách rời logic nghiệp vụ.
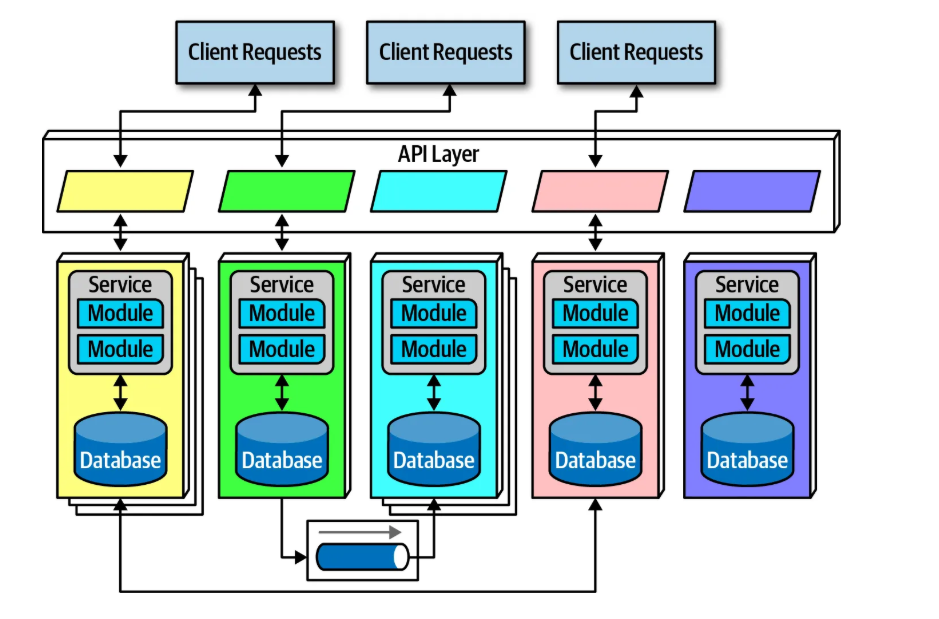
2. Kiến trúc phân tán
Microservices là một dạng một kiến trúc phân tán: mỗi dịch vụ chạy trong tiến trình riêng của nó, có thể là trên một máy vật lý, máy ảo hoặc container.
Việc tách rời các dịch vụ đến mức độ này cho phép có một giải pháp đơn giản cho một vấn đề phổ biến trong các kiến trúc có hạ tầng multi-tenant - đó là lưu trữ ứng dụng. Ví dụ, khi sử dụng một máy chủ để quản lý các ứng dụng lưu trữ, nó cho phép tái sử dụng vận hành đối với băng thông mạng, nhiều ứng dụng chạy song song, bộ nhớ và các thành phần khác. Tuy nhiên, nếu tất cả ứng dụng được hỗ trợ tiếp tục phát triển thì cuối cùng một số tài nguyên sẽ bị giới hạn trên hạ tầng chia sẻ.
Tách mỗi dịch vụ vào tiến trình riêng của nó sẽ giải quyết tất cả những vấn đề phát sinh do chia sẻ. Trước khi có sự phát triển mang tính tiến hóa của các hệ điều hành open-source miễn phí, kết hợp với việc cấp phát máy móc tự động, thì việc mỗi miền nghiệp vụ có hạ tầng riêng là không khả thi. Giờ đây, với tài nguyên cloud và công nghệ container, các nhóm phát triển có thể tận dụng lợi ích của việc tách rời tối đa - cả cấp độ miền nghiệp vụ và cấp độ vận hành.
Performance thường là trade-off của bản chất phân tán trong microservices. Các network-call mất nhiều thời gian hơn lời gọi hàm nội bộ (local-call/method-call). Thêm vào đó, việc xác thực bảo mật ở mọi API sẽ thêm thời gian xử lý bổ sung nên phải suy nghĩ cẩn trọng về các hệ quả của độ chi tiết (granularity) khi thiết kế hệ thống.
Bởi vì microservices là một kiến trúc phân tán, các kiến trúc sư có kinh nghiệm thường khuyên tránh việc sử dụng các giao dịch (transaction) liên dịch vụ, khiến cho việc xác định granularity của dịch vụ trở thành chìa khóa để thành công trong kiến trúc này.
3. Bounded Context
Triết lý cốt lõi của microservices là khái niệm bounded context
Mỗi dịch vụ mô hình hóa một miền nghiệp vụ hoặc một luồng công việc. Vì vậy, mỗi dịch vụ bao gồm mọi thứ cần thiết để vận hành trong ứng dụng, bao gồm các class, entity, database-schema và các thành phần phụ khác.
3.1. Granularity
Mục đích của ranh giới dịch vụ trong microservices là để nắm bắt một miền nghiệp vụ - domain hoặc một luồng thực thi - workflow.
Trong một số ứng dụng, các ranh giới tự nhiên này có thể lớn đối với một số phần của hệ thống — một số quy trình nghiệp vụ ràng buộc chặt hơn những phần khác. Dưới đây là một số hướng dẫn mà ta có thể dùng để tìm ra ranh giới phù hợp:
Purpose (Mục đích)
Trong microservices, ranh giới của một dịch vụ thường dựa trên nghiệp vụ chính của nó. Nói đơn giản: mỗi dịch vụ nên tập trung làm một chức năng rõ ràng cho toàn hệ thống, thay vì làm nhiều thứ rời rạc.
Transactions (Giao dịch)
Một bounded context thường gắn với một quy trình nghiệp vụ. Nếu có nhiều thực thể (entity) cần làm việc chung trong một transaction, thì tốt nhất nên gom chúng lại trong cùng một dịch vụ. Bởi vì trong hệ thống phân tán, giao dịch qua nhiều dịch vụ (distributed-transaction) thường gây lỗi và phức tạp. Tránh điều này hệ thống sẽ đơn giản và dễ vận hành hơn.
Choreography (Điều phối)
Nếu chia nhỏ dịch vụ quá mức, chúng có thể phải gọi nhau liên tục để làm xong một công việc gây tốn nhiều thời gian giao tiếp (communication-overhead). Trong trường hợp này, tốt hơn là gộp lại thành một dịch vụ lớn hơn để giảm bớt việc trao đổi qua mạng (network-call).
Việc lặp lại quy trình thiết kế là cách duy nhất để đảm bảo một kiến trúc tốt. Một kiến trúc tốt hiếm khi được tìm ra trong lần phân tích đầu tiên. Tuy nhiên, sau khi lặp lại nhiều phương án, ta sẽ có cơ hội tốt để tinh chỉnh thiết kế của mình.
3.2. Data Isolation
Trong kiến trúc microservices, mỗi dịch vụ thường có cơ sở dữ liệu riêng theo bounded context của nó. Điều này khác với các kiến trúc cũ (Monolithic, SOA,…) vốn hay dùng một cơ sở dữ liệu chung cho toàn hệ thống.
Microservices muốn tránh sự phụ thuộc lẫn nhau (coupling). Nếu nhiều dịch vụ cùng truy cập vào một cơ sở dữ liệu thì chúng sẽ dễ bị ràng buộc chặt chẽ, khó mở rộng và dễ gây lỗi.
Tuy nhiên, khi tách dữ liệu ra từng dịch vụ, sẽ xuất hiện một vấn đề mới:
- Trong hệ thống cũ, thường có một “single source of truth” - nguồn dữ liệu duy nhất và đúng đắn nhất.
- Trong microservices, dữ liệu được phân tán, nên không còn một nơi duy nhất giữ “single source of truth” nữa.
Có 3 hướng xử lý phổ biến cho việc này (ví dụ bài toán đặt hàng trong 1 ứng dụng e-commerce):
- Chọn một dịch vụ làm nơi dữ liệu gốc: Customer-service là nguồn chính cho dữ liệu khách hàng, các dịch vụ khác như Order-service sẽ gọi sang Customer-service để lấy thông tin khi cần.
- Cache dữ liệu: Order-service có thể lưu một bản copy thông tin khách hàng cần thiết (caching) để giảm số lần gọi sang Customer-service.
- Nhân bản/Đồng bộ dữ liệu: Dữ liệu khách hàng được đồng bộ qua sự kiện (event) hoặc cơ chế nhân bản (replication). Khi đó Order-service sẽ có thông tin khách hàng.
4. Operational reuse
Trong kiến trúc microservices, nguyên tắc chung là ưu tiên tách biệt thay vì chia sẻ nhằm giảm thiểu sự phụ thuộc giữa các thành phần. Tuy nhiên, không phải khía cạnh nào cũng phù hợp với cách tiếp cận này. Các mối quan tâm vận hành như giám sát (monitoring), ghi log (logging) hay cơ chế ngắt mạch (circuit-breaker) lại có tính chất lặp lại và cần được tái sử dụng để đảm bảo hiệu quả quản lý toàn hệ thống. Nếu giao phó hoàn toàn cho từng nhóm phát triển dịch vụ, tổ chức sẽ phải đối mặt với thách thức lớn trong việc duy trì sự nhất quán, kiểm soát nâng cấp và tiết kiệm chi phí vận hành.
Giải pháp cho vấn đề này chính là sidecar-pattern.
Thay vì tích hợp các chức năng vận hành trực tiếp vào từng dịch vụ, kiến trúc sidecar tách chúng ra thành một thành phần chạy song song đi kèm với mỗi dịch vụ.
Cách tiếp cận này giúp cho việc quản lý trở nên linh hoạt hơn. Một thay đổi ở công cụ giám sát hay hệ thống log chỉ cần cập nhật ở sidecar, thay vì chỉnh sửa từng dịch vụ. Đồng thời, nó đảm bảo mọi dịch vụ trong hệ thống đều tuân thủ một chuẩn vận hành thống nhất.
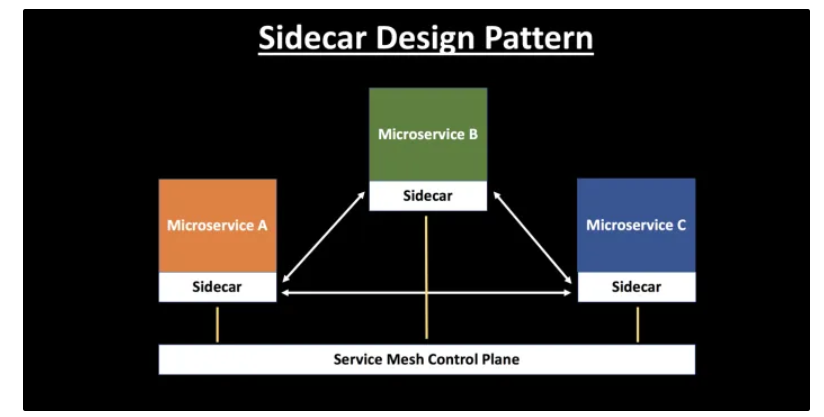
Khi toàn bộ dịch vụ đều được gắn kèm sidecar, các sidecar này có thể kết nối với nhau để hình thành service-mesh. Đây là một lớp hạ tầng cho phép quản lý tập trung các vấn đề vận hành như giám sát, ghi và theo dõi log. Đồng thời cung cấp cho hệ thống một giao diện (UI) vận hành thống nhất.
Bên cạnh đó, service-mesh thường được mở rộng với service-discovery – một cơ chế giúp hệ thống tự động phát hiện, đăng ký và điều phối dịch vụ. Nhờ vậy, các dịch vụ mới có thể được đưa vào hệ thống một cách linh hoạt, đáp ứng nhu cầu mở rộng hoặc thay đổi tải. Kết hợp với tầng API, service-discovery trở thành điểm truy cập thống nhất cho người dùng và các hệ thống bên ngoài, đảm bảo tính linh hoạt, khả năng mở rộng và sự vận hành ổn định của toàn hệ thống.
5. Communication
Trong kiến trúc microservices, giao tiếp giữa các service là yếu tố cốt lõi. Ta cần lựa chọn giữa giao tiếp đồng bộ (synchronous) và bất đồng bộ (asynchronous).
- Synchronous: bên gọi phải chờ phản hồi từ bên nhận yêu cầu.
- Asynchronous: giao tiếp thông qua events và messages, hướng đến kiến trúc Event-driven architecture (EDA).
Vì không có cơ chế tích hợp tập trung, mỗi dịch vụ phải biết cách gọi dịch vụ khác thông qua REST/SOAP hay Message-queue. Kiến trúc microservices cũng mang tính đa dạng công nghệ, cho phép các các dịch vụ được viết bằng nhiều ngôn ngữ khác nhau phù hợp với nhu cầu riêng.
5.1. Choreography & Orchestration
Có 2 cách để các dịch vụ trong một hệ thống microservices tương tác với nhau: Choreography và Orchestration. Hai phương pháp rất khác nhau về tư tưởng thiết kế.
Choreography
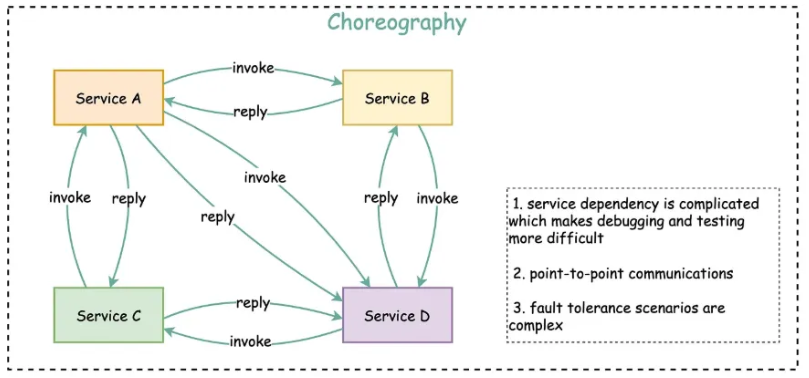
Các dịch vụ phối hợp trực tiếp với nhau mà không cần một thành phần điều phối trung tâm. Mỗi dịch vụ biết khi nào cần gọi dịch vụ khác và tự chịu trách nhiệm cho bước tiếp theo trong luồng xử lý.
Cách tiếp cận này giúp hệ thống phân tán, giảm sự phụ thuộc vào một điểm tập trung. Tuy nhiên, nó khiến việc quản lý, theo dõi luồng nghiệp vụ và kiểm tra lỗi trở nên phức tạp hơn. Mô hình này thường phù hợp khi các quy trình đơn giản và sự phối hợp giữa các dịch vụ rõ ràng.
Orchestration
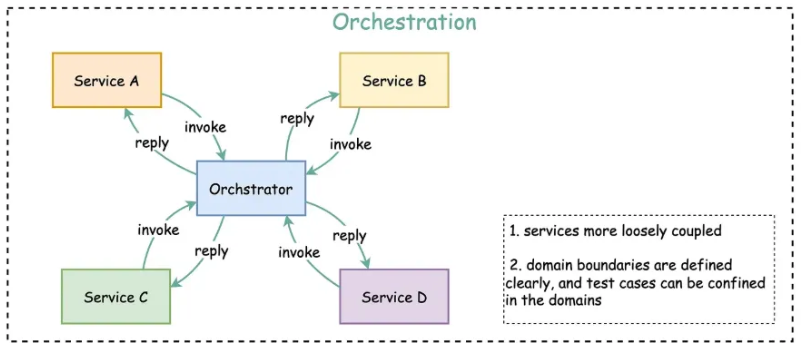
Đây là mô hình giao tiếp có một thành phần trung tâm (orchestrator) chịu trách nhiệm điều phối toàn bộ luồng nghiệp vụ. Orchestrator biết dịch vụ nào cần được gọi, theo thứ tự nào và xử lý kết quả trả về để quyết định bước tiếp theo.
Cách tiếp cận này giúp dễ kiểm soát, giám sát và quản lý luồng xử lý. Tuy nhiên, nó làm tăng sự phụ thuộc vào orchestrator, và có thể khiến orchestrator trở thành bottleneck hoặc single-point-of-failure. Mô hình này thường phù hợp cho quy trình phức tạp, nhiều bước, cần kiểm soát chặt chẽ.
5.2. Distributed-transaction & SAGA
Các kiến trúc sư microservices tìm cách tách rời các dịch vụ một cách tối đa, nhưng họ lại thường gặp vấn đề trong việc xử lý các giao dịch (transaction) giữa các dịch vụ. Khi các dịch vụ và cơ sở dữ liệu bị tách rời, tính nguyên tử (atomicity) của giao dịch - vốn rất dễ thực hiện trong các ứng dụng nguyên khối (Monolithic) lại trở thành một vấn đề lớn.
Việc tạo giao dịch giữa các dịch vụ là không nên vì nó vi phạm nguyên tắc tách rời cốt lõi của kiến trúc microservices và tạo ra sự phụ thuộc phức tạp. Thay vì tìm cách tạo giao dịch phân tán, hãy điều chỉnh lại mức độ chi tiết (granularity) của các thành phần dịch vụ.
Mặc dù việc tạo giao dịch giữa các dịch vụ là không nên nhưng vẫn có những trường hợp ngoại lệ. Ví dụ, khi hai dịch vụ cần có kiến trúc rất khác nhau, buộc phải tách rời, nhưng lại cần phải phối hợp giao dịch với nhau. Trong những tình huống như vậy, các mẫu thiết kế (patterns) đặc biệt có thể được sử dụng để xử lý giao dịch. Tuy nhiên, chúng sẽ đi kèm với những trade-offs đáng kể.
Một mẫu thiết kế xử lý giao dịch phân tán (Distributed-transaction) phổ biến trong kiến trúc microservices là SAGA Pattern.
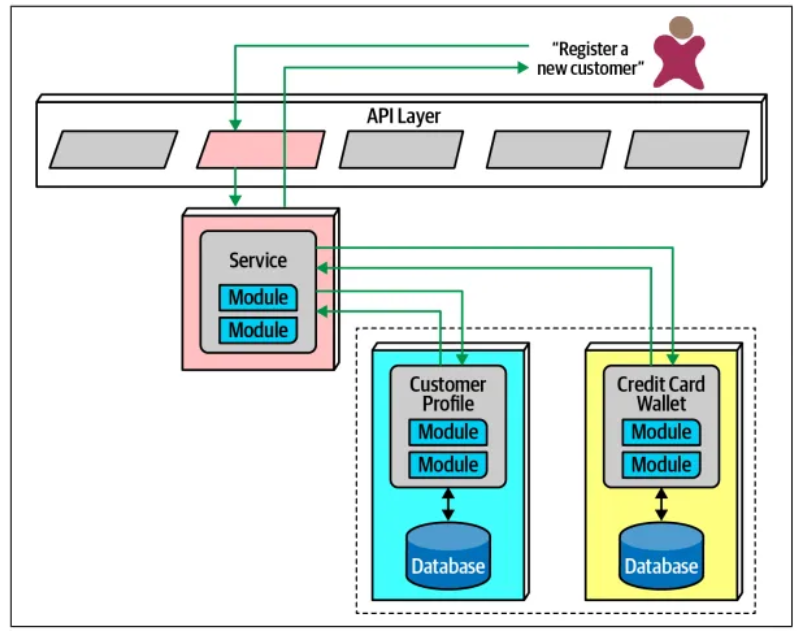
Trong ví dụ minh họa, một dịch vụ đóng vai trò trung gian (mediator) giữa nhiều yêu cầu (request) liên dịch vụ và điều phối giao dịch. Dịch vụ trung gian này sẽ gọi từng phần của giao dịch, ghi lại kết quả thành công hoặc thất bại và điều phối các kết quả. Nếu mọi thứ diễn ra theo kế hoạch, tất cả các giá trị trong các dịch vụ và cơ sở dữ liệu của chúng sẽ được cập nhật đồng bộ.
Trong trường hợp xảy ra lỗi, dịch vụ trung gian phải đảm bảo rằng không có phần nào của giao dịch thành công nếu một phần không thành công. Quy trình cụ thể như sau
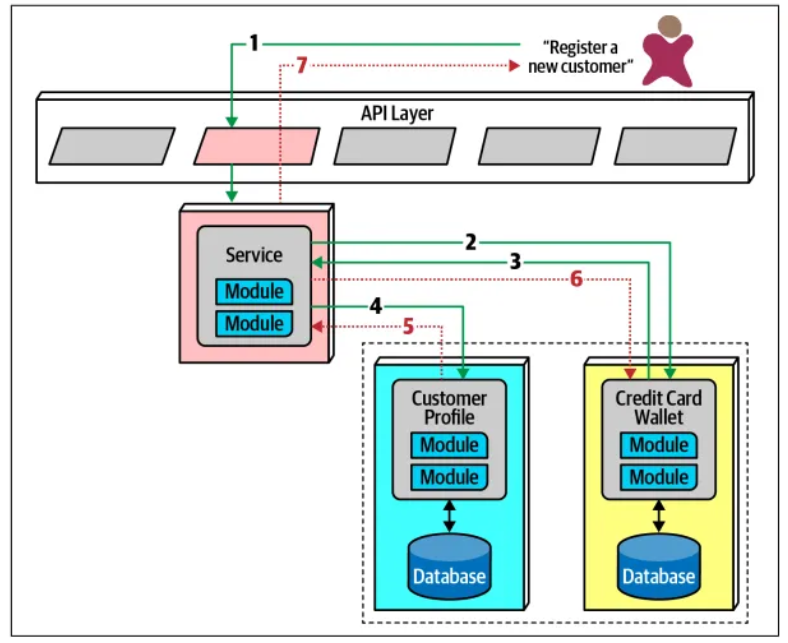
Nếu phần đầu của giao dịch thành công nhưng phần thứ hai thất bại, dịch vụ trung gian phải gửi yêu cầu đến tất cả các phần đã thành công của giao dịch để yêu cầu chúng hoàn tác lại yêu cầu trước đó. Kiểu điều phối này được gọi là compensating-transaction hay giao dịch bù.
Các nhà phát triển thường triển khai mẫu này bằng cách đưa mỗi yêu cầu (request) do dịch vụ trung gian quản lý vào trạng thái chờ xử lý (pending-state) cho đến khi dịch vụ trung gian báo hiệu tất cả các giao dịch con đều xử lý thành công.
Tuy nhiên, thiết kế này sẽ trở nên phức tạp nếu phải xử lý các yêu cầu bất đồng bộ, đặc biệt là khi có các yêu cầu mới xuất hiện phụ thuộc vào trạng thái giao dịch đang chờ xử lý.
Việc dịch vụ trung gian phải gửi các yêu cầu để điều phối và hoàn tác liên tục sẽ tạo ra một lượng lớn lưu lượng dữ liệu qua lại trên mạng. Điều này có thể làm tăng độ trễ và áp lực lên hệ thống mạng, đặc biệt là trong các ứng dụng có nhiều giao dịch phức tạp hoặc yêu cầu tốc độ cao.
Một cách triển khai khác của compensating-transaction là xây dựng các thao tác (do) và (undo) cho mỗi hoạt động có khả năng xảy ra giao dịch. Điều này giúp giảm bớt việc điều phối trong quá trình giao dịch, nhưng các thao tác (undo) có xu hướng phức tạp hơn đáng kể so với các thao tác (do). Do đó làm tăng hơn gấp đôi công việc thiết kế, triển khai và gỡ lỗi.
Mặc dù chúng ta có thể xây dựng các giao dịch liên dịch vụ tuy nhiên nên nhớ rằng điều này đi ngược lại tư tưởng thiết kế của kiến trúc microservices.
Các trường hợp gây lỗi luôn tồn tại, vì vậy lời khuyên tốt nhất là nên sử dụng SAGA Pattern một cách thận trọng.
All rights reserved
