Kiến trúc ColBERTv2: Tối ưu truy xuất thông tin cho hệ thống RAG
1. Đặt vấn đề
Ở phiên bản v1, đặt ra một thách thức lớn về Không gian lưu trữ (Space Footprint), việc lưu trữ vector thô (16-bit/32-bit float) cho mỗi token khiến dung lượng Index phình to một cách khủng khiếp.
- Ví dụ: Với 8.8 triệu đoạn văn của MS MARCO, v1 tốn 154 GiB - 286 GiB.
- Hệ quả: Việc triển khai trên quy mô hàng tỷ tài liệu (Billion-scale) đòi hỏi tài nguyên RAM cực kỳ đắt đỏ, vượt quá khả năng của nhiều hệ thống.
→Nếu ColBERT v1 là một "đột phá" với cơ chế Late Interaction, thì ColBERT v2 chính là lời giải cho bài toán thực tế, v2 tập trung giải quyết hai vấn đề chí mạng của v1: Dung lượng lưu trữ khổng lồ và Sự phụ thuộc vào chất lượng dữ liệu huấn luyện.
2. Chiến lược huấn luyện: Denoised Supervision
Trong khi ColBERT v1 dựa trên các cặp Triple đơn giản từ tập dữ liệu MS MARCO, ColBERTv2 thực hiện một bước nhảy vọt về chất lượng thông qua cơ chế giám sát tinh vi. Mục tiêu của v2 là tạo ra các vector token chuẩn xác hơn, giúp chúng giữ được đặc trưng ngữ nghĩa ngay cả sau khi bị nén cực mạnh.
2.1 Distillation (Chưng cất tri thức từ Cross-Encoder)
- Mô hình “giáo viên”: Sử dụng một Cross-Encoder mạnh (như MiniLM với 22 triệu tham số). Cross-Encoder cực kỳ chính xác vì nó cho phép câu hỏi và văn bản tương tác với nhau ngay từ lớp đầu tiên (Early Interaction).
- Cơ chế học: Với mỗi Query, mô hình “giáo viên” sẽ chấm điểm một tập hợp các tài liệu (bao gồm cả tài liệu đúng và tài liệu sai tiềm năng).
- Hàm Loss KL-Divergence: Thay vì dùng hàm Loss phân loại nhị phân (Đúng/Sai) như v1, ColBERTv2 sử dụng KL-Divergence để bắt chước hoàn toàn "phân phối điểm số" của Cross-Encoder.
💡 Ở đây, được tính bằng Softmax trên các Logits của Cross-Encoder. Nếu thực chất là một tài liệu tốt (False Negative), mô hình “giáo viên” (vốn rất thông minh và nhìn thấy cả và cùng lúc) sẽ trả về một điểm số cao cho .
→ Vì không bị ép "bẻ cong" vector để thỏa mãn nhãn sai, các vector token sẽ hội tụ về các cụm (clusters) rất rõ ràng và ổn định dựa trên ý nghĩa thực của chúng.
2.2 Hard-Negative Mining (Khai thác mẫu âm khó)
Để mô hình thực sự tinh nhạy, nó cần được huấn luyện bởi những ví dụ Hard Negatives.
- Quy trình: ColBERTv2 sử dụng chính Index đã nén của nó để thực hiện truy vấn trên tập huấn luyện và lấy ra Top-k kết quả.
- Lựa chọn mẫu: Những tài liệu không phải là tài liệu đúng nhưng lại được ColBERTv2 chấm điểm cao chính là các Hard Negatives. Các mẫu này chứa rất nhiều từ khóa trùng khớp với query nhưng lại sai về bản chất ngữ nghĩa hoặc ngữ cảnh.
- Độ khó tăng cường: v2 xây dựng các bộ dữ liệu huấn luyện lên tới 64-way tuples, Cụ thể, v2 sử dụng cấu trúc 64-way nghĩa là mỗi Query sẽ đi kèm với 1 tài liệu đúng () và 63 tài liệu sai (). Điều này buộc BERT phải học cách phân biệt các sắc thái ngữ nghĩa cực nhỏ ở cấp độ token để không bị đánh lừa.
💡 v1 (Triplets): 1 Pos + 1 Neg → Ranh giới phân loại rộng, dễ bị nhiễu bởi các tài liệu trùng từ khóa. v2 (64-way Tuples): 1 Pos + 63 Hard Negs → Ranh giới phân loại cực hẹp và sắc nét, tối ưu hóa khả năng phân biệt ngữ nghĩa tinh vi.
2.3 Khử nhiễu (Denoising)
Đây là phần giải thích cho cái tên "Denoised Supervision".
💡 Vấn đề của dữ liệu thô: Trong các tập dữ liệu lớn như MS MARCO, có rất nhiều tài liệu thực tế là đúng (Relevant) nhưng lại không được dán nhãn (Unlabeled). Trong huấn luyện truyền thống, nếu mô hình tìm thấy các tài liệu này, nó sẽ bị phạt (vì bị coi là False Negative). Đây chính là noise.
- Cách v2 giải quyết: Nhờ có sự dẫn dắt của Cross-Encoder, nếu một tài liệu chưa dán nhãn nhưng được mô hình giáo viên chấm điểm cao, ColBERTv2 sẽ coi đó là một tín hiệu tích cực thay vì bị phạt.
- Lợi ích: Quy trình này giúp mô hình ít bị ảnh hưởng bởi các nhãn dán thiếu sót trong tập dữ liệu, từ đó học được bản chất ngữ nghĩa thực sự của các token.
3. Cơ chế Nén thặng dư (Residual Compression)
Đây là cải tiến quan trọng nhất giúp giảm dung lượng Index từ 6 - 10 lần mà không đánh đổi độ chính xác.
3.1 Phân cụm dựa trên Tâm điểm (Centroid-based Clustering)
ColBERTv2 khai thác thực tế là các vector token luôn tập trung quanh các vùng ngữ nghĩa ổn định.
- Centroids: Hệ thống xác định khoảng (tương đương 262,144) tâm cụm trong không gian vector.
- Phân vùng: Mỗi vector được gán cho một Centroid gần nhất . Tại đây, đóng vai trò là bộ khung mang ý nghĩa chung của cụm.
3.2 Biểu diễn phần dư (Residual Representation)
Thay vì lưu 128 số thực (float) cho mỗi vector v, v2 chỉ lưu:
- ID của Centroid: Mã số của tâm cụm gần nhất.
- Vector phần dư (r): . Đây là phần chênh lệch (khoảng cách và hướng) để tinh chỉnh vị trí của vector gốc từ tâm cụm.
3.3 Lượng tử hóa vô hướng (Scalar Quantization)
Phần dư thường có phân phối chuẩn và đối xứng quanh 0. V2 tận dụng điều này để nén xuống mức bit-level:
- 1-bit Quantization: Chỉ lưu dấu (0 cho số âm, 1 cho số dương).
- 2-bit Quantization: Chia dải giá trị của thành 4 khoảng dựa trên độ lệch chuẩn.
- Kết quả: Mỗi từ từ 256 bytes (v1) giảm xuống chỉ còn 20 - 36 bytes (v2). Với tập MS MARCO, dung lượng RAM cần thiết giảm từ 154 GiB xuống 25 GiB.
- Cấu trúc: Phần dư bảo toàn đầy đủ chiều của không gian vector. Kỹ thuật lượng tử hóa được áp dụng độc lập trên mỗi chiều.
- Độ mịn dữ liệu: Việc sử dụng 2-bit (4 trạng thái) cho phép mô hình biểu diễn không chỉ hướng (âm/dương) mà cả cường độ (độ lệch mạnh/yếu) của vector token so với tâm cụm.
- Hiệu ứng triệt tiêu sai số: Nhờ số lượng chiều lớn (thường m = 128), các sai số lượng tử hóa nhỏ ở từng chiều sẽ tự động triệt tiêu lẫn nhau trong phép tính tổng MaxSim ().
→ Điều này giải thích tại sao ColBERTv2 có thể nén dữ liệu cực mạnh mà vẫn duy trì được độ chính xác tương đương các mô hình Cross-Encoder không nén.
4. Quy trình Triển khai Indexing (Offline Indexing Pipeline)
Quy trình Index của v2 được thiết kế để tối ưu hóa bộ nhớ và tận dụng tối đa phần cứng thông qua 3 giai đoạn:
Bước 1: Centroid Selection (Chọn tâm cụm)
Để xây dựng bộ khung nén, ColBERTv2 cần xác định các Centroids đại diện cho toàn bộ không gian ngữ nghĩa. Tuy nhiên, việc xử lý hàng tỷ vector token cùng lúc là bất khả thi về mặt tài nguyên RAM. Quy trình giải quyết gồm 2 bước tối ưu:
A. Lấy mẫu đại diện (Sampling)
Hệ thống không tính toán Centroid trên toàn bộ hàng tỷ vector (vì quá tốn RAM). Thay vào đó:
- Nó lấy một sample đại diện từ kho dữ liệu. Đây là một quy tắc tối ưu được mượn từ thư viện FAISS (Facebook AI Similarity Search) mà ColBERTv2 áp dụng.
- Công thức: Nếu tổng số vector trong kho dữ liệu là , thì số lượng mẫu cần lấy sẽ được tính theo công thức:
💡 Tại sao lại là căn bậc hai?
- Số lượng tâm cụm (Centroids) k thường cũng được thiết lập tỉ lệ với (ví dụ: ).
- Để thuật toán K-means hoạt động ổn định và hội tụ tốt, mỗi tâm cụm cần có khoảng 256 đến 1024 điểm dữ liệu để huấn luyện.
- Do đó, số mẫu S sẽ tỉ lệ với số tâm cụm , mà k lại tỉ lệ với . Suy ra tỉ lệ với .
B. Xác định số lượng tâm cụm ()
- Quy tắc thiết lập: Số lượng tâm cụm được tính dựa trên quy mô của kho dữ liệu theo công thức:
- Tối ưu hóa FAISS: Sau khi có con số ước tính, hệ thống sẽ làm tròn lên lũy thừa của 2 gần nhất để tối ưu hóa việc tính toán trên GPU/CPU.
☝Ví dụ thực tế
- Với tập dữ liệu MS MARCO (khoảng 226 triệu vector token), công thức: cho ra kết quả khoảng 240,528.
- Lũy thừa của 2 gần nhất và lớn hơn con số này chính là .
- Với các kho dữ liệu lớn hơn hoặc nhỏ hơn, sẽ thay đổi tương ứng (, ,…).
Bước 2: Passage Encoding & Compression
Quét qua toàn bộ tài liệu theo batch:
- BERT Encoding: Tạo ra các vector token 128 chiều (sau lớp Linear).
- Centroid Assignment: Với mỗi vector, tìm Centroid gần nhất trong bộ mã tâm cụm.
- Residual Calculation: Tính toán và thực hiện lượng tử hóa (1-bit hoặc 2-bit).
- Storage: Lưu ID tâm cụm và phần dư đã nén xuống đĩa theo từng khối tài liệu.
Bước 3: Index Inversion (Lập danh sách đảo ngược)
Để hỗ trợ tìm kiếm thần tốc (End-to-End Retrieval):
- Hệ thống gom tất cả các Embedding ID có chung một Centroid ID vào một danh sách gọi là Inverted List.
- Khi có một Query, thay vì quét toàn bộ Index, ColBERTv2 thực hiện qua 2 bước:
- Candidate Generation (Lọc ứng viên):
- Với mỗi token trong (), hệ thống tìm tâm cụm (Centroids) gần nó nhất (thường 1, 2 hoặc 4).
- Hệ thống chỉ truy cập vào các Inverted Lists của các Centroids này.
- Hiệu quả: Việc này loại bỏ ngay lập tức 99.9% các vector không liên quan trong kho dữ liệu.
- Approximate MaxSim & Rerank:
- Hệ thống giải nén các phần dư trong danh sách ứng viên, phục hồi lại vector xấp xỉ .
- Tính điểm MaxSim xấp xỉ: tính tích vô hướng giữa vector () với tất cả các vector của tài liệu đó. Điểm số này được gọi là một "Cận dưới" (Lower-bound) của điểm thực tế.
- Từ đó lấy ra Top-K tài liệu ‘ứng viên’. Tiếp theo thực hiện tính MaxSim để trả ra kết quả tốt nhất cho người dùng.
- Candidate Generation (Lọc ứng viên):
Kết luận Indexing
Sự kết hợp giữa Inverted List và Residual Compression giúp ColBERTv2 đạt được hiệu quả tối ưu với Information Retrieval:
- Dung lượng thấp: Cạnh tranh trực tiếp với các mô hình Single-vector (Single-embedding).
- Tốc độ cao: Nhờ Inverted List loại bỏ 99.9% dữ liệu thừa, việc tra cứu Multi-vector không còn là gánh nặng.
- Độ chính xác không đổi: Việc nén dựa trên "khoảng cách tới tâm cụm" (Residual) thông minh hơn so với nén vector thô, giúp bảo toàn các sắc thái ngữ nghĩa của Late Interaction
5. Đánh giá Khả năng Tổng quát hóa: Benchmark LoTTE
LoTTE (viết tắt của Long-Tail Topic-stratified Evaluation for IR) là một bộ benchmark mới được giới thiệu cùng với ColBERTv2 nhằm đánh giá khả năng truy hồi thông tin trong các kịch bản ngoài miền dữ liệu huấn luyện (out-of-domain), đặc biệt tập trung vào các chủ đề ngách (long-tail topics) và các câu truy vấn thực tế của người dùng
5.1 Mục tiêu và Ý nghĩa
Khác với các bộ dữ liệu phổ biến như Wikipedia (thường tập trung vào các thực thể nổi tiếng), LoTTE nhắm vào các chủ đề ít phổ biến hơn mà các hệ thống IR thường gặp khó khăn,. Nó bổ sung cho benchmark BEIR bằng cách tập trung vào các câu hỏi tìm kiếm tự nhiên với ý định thực tế thay vì chỉ là các tác vụ tương đồng ngữ nghĩa,.
5.2 Cấu trúc và Quy mô dữ liệu
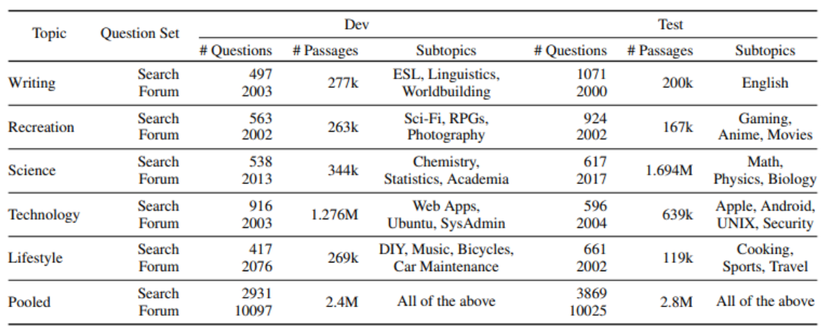
- Nguồn dữ liệu: Các đoạn văn bản (passages) được thu thập từ các bài đăng trả lời trên các cộng đồng StackExchange,.
- Phân loại chủ đề: Dữ liệu được chia thành 12 bộ thử nghiệm thuộc 5 lĩnh vực chính: Viết lách (Writing), Giải trí (Recreation), Khoa học (Science), Công nghệ (Technology) và Đời sống (Lifestyle),.
- Số lượng: Mỗi bộ thử nghiệm chứa từ 500 đến 2.000 câu truy vấn và kho dữ liệu từ 100.000 đến 2 triệu đoạn văn bản.
- Chế độ "Pooled": Bên cạnh việc đánh giá theo từng chủ đề, LoTTE còn có thiết lập "pooled" — gộp tất cả các chủ đề lại thành một kho dữ liệu lớn và đa dạng hơn để kiểm tra khả năng chuyển đổi miền của mô hình,.
5.3 Hai loại câu truy vấn chính

☝ Ví dụ về các truy vấn và đoạn trích ngắn của các câu trả lời từ LoTTE. Hai ví dụ đầu tiên thể hiện các truy vấn Search, trong khi hai ví dụ cuối là các truy vấn Forum. Các đoạn trích được rút ngắn để dễ trình bày.
LoTTE phân biệt rõ rệt giữa hai kiểu tìm kiếm:
- Search Queries: Được lấy từ dữ liệu GooAQ (các câu hỏi tự động hoàn thành trên Google). Những câu hỏi này thường ngắn gọn, mang tính tìm kiếm kiến thức và phản ánh hành vi tìm kiếm tự nhiên của người dùng,.
- Forum Queries: Được trích xuất từ tiêu đề các bài đăng trên StackExchange. Những câu hỏi này thường mang tính mở hơn và đa dạng hơn so với các truy vấn tìm kiếm thông thường,.
5.4 Phương pháp đánh giá
- Chỉ số: Sử dụng Success@5 (S@5). Một hệ thống sẽ ghi điểm nếu tìm thấy câu trả lời chính xác (được chấp nhận hoặc có điểm bình chọn ≥ 1) nằm trong 5 kết quả đầu tiên.
- Ý nghĩa: Chỉ số này phản ánh khả năng của mô hình trong việc đưa ra những lựa chọn chất lượng nhất trong một không gian kết quả rất hẹp.
5.5 So sánh hiệu năng thực nghiệm
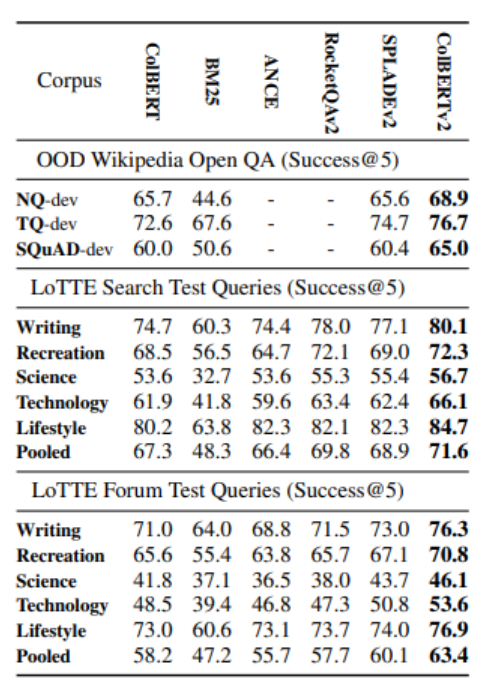
a. Khả năng Tổng quát hóa (Zero-shot) vượt trội
- Insight: ColBERTv2 thiết lập kỷ lục SOTA mới trên tất cả 28 tập dữ liệu thử nghiệm ngoài miền huấn luyện (Wikipedia, LoTTE).
- Ý nghĩa: Dù chỉ huấn luyện trên dữ liệu phổ thông (MS MARCO), v2 vẫn áp đảo các đối thủ ở các chủ đề Long-tail như Khoa học, Công nghệ. Điều này chứng minh cơ chế Late Interaction bền bỉ hơn hẳn các mô hình Single-vector khi đối mặt với thuật ngữ chuyên sâu và dữ liệu lạ.
b. Nghịch lý: Nén mạnh hơn nhưng Chính xác hơn
- Insight: Mặc dù bị nén thặng dư (Residual Compression) tới 10 lần so với v1, ColBERTv2 vẫn đạt điểm số cao hơn phiên bản tiền nhiệm ở mọi hạng mục (ví dụ Science Search: 53.6 vs 56.7).
- Ý nghĩa: Chiến lược Denoised Supervision đã tạo ra các vector token chất lượng cao đến mức dù bị lượng tử hóa xuống 1-bit/2-bit, chúng vẫn mang nhiều thông tin ngữ nghĩa hơn các vector thô của v1.
c. Ưu thế tuyệt đối trong các truy vấn phức tạp (Forum Queries)
- Insight: Khoảng cách dẫn trước của ColBERTv2 so với các đối thủ (SPLADEv2, RocketQAv2) nới rộng nhất ở phần Forum Queries (truy vấn từ diễn đàn).
- Ý nghĩa: Các câu hỏi trên diễn đàn thường dài, mang tính diễn đạt cá nhân và cấu trúc phức tạp. Việc khớp token-to-token giúp ColBERTv2 chính xác trong các câu hỏi dài dòng, điều mà các mô hình Single-vector thường gặp khó khăn.
6. Những hạn chế và Thách thức
Mặc dù sở hữu hiệu năng ấn tượng, ColBERTv2 vẫn tồn tại những rào cản kỹ thuật cần lưu ý:
- Chi phí huấn luyện (Training Overhead): Quy trình chưng cất tri thức (Distillation) từ Cross-Encoder và khai thác mẫu âm khó (Hard-negative mining) đòi hỏi tài nguyên tính toán và thời gian huấn luyện lớn hơn nhiều so với các mô hình Bi-Encoder đơn giản.
- Độ phức tạp hệ thống: Việc quản lý centroids, inverted lists và residual compression yêu cầu hạ tầng phần mềm phức tạp hơn so với các hệ thống tìm kiếm vector đơn lẻ (Vector DB truyền thống).
- Rào cản ngôn ngữ: Hầu hết các thực nghiệm và bộ tham số tối ưu hiện tại đều dựa trên tiếng Anh (MS MARCO). Việc mở rộng sang đa ngôn ngữ (Multilingual) yêu cầu dữ liệu huấn luyện tương ứng và cấu hình lại bộ Centroids để phù hợp với đặc thù của từng ngôn ngữ.
- Sự phụ thuộc vào phần cứng: Mặc dù đã tối ưu hóa, phép toán MaxSim vẫn đạt hiệu suất cao nhất trên GPU. Việc triển khai hoàn toàn trên CPU ở quy mô hàng tỷ tài liệu vẫn là một thách thức về mặt độ trễ nếu không có các kỹ thuật tối ưu hóa mã nguồn sâu hơn.
7. Kết luận
ColBERTv2 không chỉ là một bản cập nhật, mà là một lời giải toàn diện cho bài toán cân bằng giữa Accuracy, Latency và Dung lượng (Footprint).
- Đột phá công nghệ: Bằng cách kết hợp chiến lược Denoised Supervision và Residual Compression, v2 đã đưa kiến trúc Late Interaction từ một mô hình lý thuyết nặng nề thành một giải pháp thực chiến mạnh mẽ.
- Giá trị hệ thống: ColBERTv2 thiết lập tiêu chuẩn mới về khả năng tổng quát hóa (Zero-shot) trên các chủ đề Long-tail. Trong kỷ nguyên của RAG, đây là "bộ máy truy xuất" lý tưởng giúp giảm thiểu hallucination nhờ khả năng cung cấp bằng chứng chính xác tới từng token.
- Hiệu quả kinh tế: Việc cắt giảm 10 lần dung lượng Index giúp các doanh nghiệp triển khai hệ thống tìm kiếm Neural IR quy mô hàng tỷ tài liệu với chi phí phần cứng tối thiểu, tiệm cận các mô hình Single-vector nhưng với độ chính xác vượt trội của Cross-Encoder.
II. Tổng kết & Sample với RAGatouille
1. So sánh: ColBERT v1 vs. ColBERT v2
| Tiêu chí | ColBERT v1 (Nền tảng) | ColBERT v2 (Tối ưu hóa) |
|---|---|---|
| Kiến trúc Encoder | BERT-base + Linear Layer (Nén xuống chiều) | BERT-base + Linear Layer (Thừa hưởng từ v1) |
| Chiến lược Huấn luyện | Pairwise Softmax Cross-entropy (dựa trên các cặp Triple / đơn giản). | Denoised Supervision: Distillation từ Cross-Encoder mạnh + Hard-negative mining. |
| Cấu trúc Indexing | IVF đơn giản: Lưu trữ vector thô, tra cứu dựa trên tài liệu. | MV-IVF + Centroid Pruning: Lập chỉ mục cấp độ Token với tâm cụm. |
| Cơ chế Nén (Compression) | Không nén: Lưu trữ giá trị thực (float32/float16). | Residual Compression: Chỉ lưu ID tâm cụm + Phần dư (Residual) nén 1-bit/2-bit. |
| Dung lượng lưu trữ | Rất cao: ~512 Bytes/token (với float32, 128d). | Cực thấp: ~20 - 36 Bytes/token (Giảm 6 - 10 lần). |
| Độ trễ (Latency) | Cao ở quy mô lớn: Nghẽn băng thông khi truyền tải tensor vector thô lên GPU. | Thấp (Real-time): Dữ liệu nén nhỏ gọn giúp tăng tốc độ Gathering & Transfer lên GPU. |
| Khả năng tổng quát hóa | Tốt trên tập dữ liệu huấn luyện (MS MARCO). | SOTA (State-of-the-art): Đứng đầu 22/28 benchmark Zero-shot (BEIR, LoTTE). |
| Quy mô triển khai | Phù hợp quy mô triệu tài liệu (Million-scale). | Tối ưu quy mô hàng tỷ tài liệu (Billion-scale). |
Sự chuyển dịch từ ColBERT v1 sang v2 không chỉ là một bản cập nhật phần mềm, mà là một cuộc cách mạng về tính thực dụng trong kiến trúc Neural IR:
- ColBERT v1: Xác lập triết lý Late Interaction và phép toán MaxSim. Nó chứng minh rằng việc giữ lại đặc trưng ở cấp độ token sẽ mang lại độ chính xác vượt trội so với các mô hình nén vào một vector đơn (Single-vector). Tuy nhiên, rào cản lớn nhất là Storage Footprint quá lớn.
- ColBERT v2: Giải quyết triệt để bài toán kinh tế. Thông qua Residual Compression và Denoised Supervision, v2 giảm dung lượng Index xuống 6-10 lần mà không làm mất đi độ chính xác, thậm chí còn đạt SOTA trên các benchmark ngoài miền dữ liệu (Zero-shot) như LoTTE.
2. Triển khai với RAGatouille (Source)
Trong thực tế triển khai doanh nghiệp, việc tự viết lại toàn bộ các bước chia cụm (Centroid), nén Residual hay quản lý Inverted List là cực kỳ phức tạp. RAGatouille ra đời như một "wrapper" chuẩn công nghiệp, giúp đơn giản hóa toàn bộ các công trình nghiên cứu của Stanford thành các hàm Python dễ sử dụng.
2.1 Chiến lược Inference tối ưu cho RAG
Tùy vào quy mô dữ liệu của doanh nghiệp, chúng ta có hai chiến lược triển khai chính với RAGatouille:
- Chiến lược 1: Re-ranking Stage 2 (Khuyên dùng cho quy mô lớn)
- Cơ chế: Kết hợp BM25 (Elasticsearch) lấy Top 100 → Dùng hàm .rerank() của RAGatouille để sắp xếp lại.
- Ưu điểm: Tận dụng hạ tầng CPU sẵn có cho lọc thô, chỉ dùng GPU cho bước tính toán kỹ cuối cùng. Đây là cách tiếp cận cân bằng nhất giữa chi phí và hiệu năng.
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
query = "Cơ chế nén của ColBERT v2"
candidates = [
"ColBERT v2 sử dụng Residual Compression để giảm dung lượng.",
"Mô hình BERT truyền thống không có Late Interaction.",
"RAG giúp giảm thiểu hiện tượng ảo giác thông tin."
]
# Thực hiện Re-rank
results = RAG.rerank(query=query, documents=candidates, k=1)
# --- GIẢI THÍCH KẾT QUẢ TRẢ RA (OUTPUT) ---
# 'results' là một danh sách các Dictionary. Mỗi Dictionary chứa:
# [
# {
# "content": "ColBERT v2 sử dụng Residual Compression để giảm dung lượng.",
# "score": 25.85,
# "rank": 1,
# "result_index": 0
# }
# ]
for res in results:
print(f"--- PHÂN TÍCH RANK {res['rank']} ---")
print(f"Nội dung: {res['content']}") # Văn bản gốc được khớp
# SCORE: Đây là tổng điểm MaxSim (đơn vị: tích vô hướng/cosine).
# Điểm càng cao (>15-20) nghĩa là các token khớp ngữ nghĩa cực mạnh.
print(f"Điểm MaxSim: {res['score']}")
# RESULT_INDEX: Vị trí gốc của tài liệu trong danh sách 'candidates' truyền vào.
# Giúp map lại với Database gốc của doanh nghiệp.
print(f"Vị trí gốc: {res['result_index']}")
- Chiến lược 2: End-to-End Retrieval (Khuyên dùng cho quy mô vừa và nhỏ)
- Cơ chế: Dùng hàm .index() để tạo chỉ mục trực tiếp và .search() để truy xuất.
- Ưu điểm: Loại bỏ sự phụ thuộc vào các Vector DB bên thứ ba, cung cấp trải nghiệm tìm kiếm "All-in-one" cực kỳ mạnh mẽ.
from ragatouille import RAGPretrainedModel
# 1. KHỞI TẠO MODEL (Load Checkpoint ColBERT v2)
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
# --- BƯỚC 1: OFFLINE INDEXING (EMBEDDING & LẬP CHỈ MỤC) ---
# Đây là giai đoạn "nạp kiến thức" vào hệ thống.
my_docs = [
"ColBERT v2 sử dụng cơ chế nén Residual Compression để giảm dung lượng Index.",
"Hệ thống RAG giúp giảm ảo giác (hallucination) bằng cách cung cấp bằng chứng thực tế.",
"RAGatouille là thư viện Python giúp triển khai ColBERT một cách đơn giản nhất."
]
# Thực hiện Indexing: Mã hóa từng token, phân cụm (Centroid) và nén (Residual)
RAG.index(
collection=my_docs,
index_name="my_enterprise_index",
max_document_length=180
)
# --- BƯỚC 2: ONLINE SEARCH (TRUY XUẤT TỪ ĐẦU ĐẾN CUỐI) ---
# Hệ thống tự tìm trong Index đã tạo ở bước 1 mà không cần bộ lọc nào khác.
query = "Cách ColBERT v2 tiết kiệm bộ nhớ?"
results = RAG.search(query=query, k=1)
# --- GIẢI THÍCH KẾT QUẢ TRẢ RA (OUTPUT ANNOTATION) ---
# 'results' trả về một danh sách các Dictionary (mỗi Dic là một đoạn văn khớp nhất).
# Ví dụ kết quả thực tế của results[0]:
# {
# 'content': 'ColBERT v2 sử dụng cơ chế nén Residual Compression để giảm dung lượng Index.',
# 'score': 24.15625,
# 'rank': 1,
# 'document_id': 'doc_0',
# 'passage_id': 0,
# 'document_metadata': {}
# }
for res in results:
print(f"--- KẾT QUẢ SEARCH CHI TIẾT ---")
# 1. CONTENT: Nội dung đoạn văn bản thô được tìm thấy.
# Đây là kiến thức sẽ đưa vào Prompt cho LLM trả lời.
print(f"Nội dung: {res['content']}")
# 2. SCORE (Điểm MaxSim): Tổng độ tương đồng giữa các token Query và Document.
# - Lưu ý: Score này không giới hạn 0-1.
# - Score > 15 thường là kết quả rất chất lượng.
print(f"Điểm MaxSim: {res['score']:.2f}")
# 3. RANK: Thứ tự ưu tiên của kết quả (1 là tốt nhất).
# RAGatouille đã tự động sắp xếp kết quả theo điểm số giảm dần cho bạn.
print(f"Xếp hạng: {res['rank']}")
# 4. DOCUMENT_ID & PASSAGE_ID:
# - document_id: ID của tài liệu gốc bạn nạp vào lúc Index.
# - passage_id: ID của đoạn văn nhỏ (chunk) sau khi hệ thống tự chia.
# Dùng các ID này để truy vấn ngược lại database gốc nếu cần lấy thêm thông tin.
print(f"ID định danh: {res['document_id']} (Đoạn số: {res['passage_id']})")
# 5. DOCUMENT_METADATA:
# Các thông tin đi kèm (như Tác giả, Ngày tạo, URL nguồn...)
# Nếu lúc Index có truyền thêm metadata, nó sẽ xuất hiện ở đây.
print(f"Dữ liệu kèm theo: {res['document_metadata']}")
Link đính kèm và Tài liệu tham khảo:
All rights reserved
