Kiến trúc ColBERTv1 cho RAG
1. Tổng quan
Trong kiến trúc hệ thống tìm kiếm thông tin hiện đại, chúng ta đang chứng kiến một sự chuyển dịch mang tính bước ngoặt: từ tìm kiếm từ khóa (lexical search) dựa trên tần suất từ (BM25) sang tìm kiếm ngữ nghĩa (semantic search) dựa trên không gian vector. Trong hệ sinh thái Neural IR, ColBERT (Contextualized Late Interaction over BERT) đã xác lập vị thế là một trong những kiến trúc hiệu quả nhất nhờ cơ chế Late Interaction.
Điểm đổi mới cốt lõi của ColBERT là khả năng bảo toàn đặc tính ngữ nghĩa ở cấp độ token (token-level embeddings) thay vì nén toàn bộ văn bản vào một vector duy nhất (single-vector). Điều này giúp hệ thống đạt được độ chính xác tương đương các mô hình Cross-Encoder phức tạp nhưng vẫn duy trì được hiệu suất truy xuất ở quy mô lớn của các mô hình Bi-Encoder. Đối với các kỹ sư kiến trúc giải pháp AI, ColBERT mang lại 3 giá trị chiến lược cho hệ thống RAG (Retrieval-Augmented Generation):
- Độ chính xác chi tiết (Fine-grained Precision): Khả năng nắm bắt các sắc thái ngôn ngữ nhỏ nhất, đặc biệt hiệu quả trong các truy vấn dài hoặc chứa các thuật ngữ chuyên môn sâu.
- Hiệu suất lưu trữ đột phá: Với sự ra đời của phiên bản v2, các kỹ thuật nén phần dư (residual compression) đã cho phép triển khai trên hàng tỷ tài liệu mà không đòi hỏi tài nguyên RAM không tưởng.
- Khả năng Grounding vượt trội: Cung cấp bằng chứng truy xuất mạnh mẽ để giảm thiểu hiện tượng hallucination trong các Pipeline Agentic RAG.
2. Kiến trúc Cốt lõi và Cơ chế Late Interaction
Sự khác biệt lớn nhất giữa ColBERT và các kiến trúc Dense Retrieval truyền thống nằm ở giai đoạn tương tác giữa Query (câu hỏi) và Document (tài liệu).
2.1 Phân tích sự đánh đổi về Performance
Các mô hình "Single-vector" truyền thống nén toàn bộ ngữ cảnh của một đoạn văn vào một vector duy nhất (thường là 768 chiều). Quy trình này tạo ra hiện tượng "nghẽn cổ chai thông tin", nơi các chi tiết cụ thể bị pha loãng. ColBERT phá bỏ giới hạn này bằng cách sử dụng Token-level embeddings. Mỗi token trong văn bản được ánh xạ thành một vector riêng biệt, cho phép mô hình giữ lại "dấu vết" ngữ nghĩa của từng từ trong mối tương quan với các từ xung quanh.
2.2 Kiến trúc mạng (Encoder Architecture)
ColBERT sử dụng một mô hình ngôn ngữ tiền huấn luyện (thường là BERT) nhưng cấu hình nó theo cách đặc biệt để tạo ra các Contextualized Token Embeddings.
2.2.1 Query Encoder ()
- Input: Câu hỏi q được thêm tiền tố đặc biệt [Q].
Cấu trúc Input: [CLS] [Q] q1 q2 ... ql [mask] [mask] ... [mask]
- [Q] Token: Một token đặc biệt để báo cho BERT biết: "Đây là một câu hỏi, hãy xử lý nó theo kiểu truy vấn."
- Query Augmentation (Dùng [mask]): ColBERT cung cấp hyperparameter chiều dài query là . Nếu query có ít token hơn , nó sẽ bù vào bằng các token [mask]. Ngược lại nếu nhiều token hơn , nó sẽ chỉ giữ tokens từ query.
💡 Tại sao lại dùng [mask]?
- Cơ chế học "Mở rộng truy vấn" (Query Expansion): Các token [mask] này cho phép BERT sinh ra các embedding tại vị trí đó dựa trên ngữ cảnh của câu hỏi gốc, những từ tiềm năng có thể liên quan đến câu hỏi.
- Học trọng số (Re-weighting): Thông qua các vị trí [mask], BERT có thể học cách nhấn mạnh hoặc giảm nhẹ tầm quan trọng của các từ có sẵn trong query để tối ưu hóa việc matching với document sau này.
- Processing: Đi qua BERT để lấy các hidden states
- Linear Bottleneck: Sau lớp BERT, ColBERT thêm một lớp Linear Layer (không có activations) để giảm số chiều xuống còn m chiều (thường m = 128).
💡 Linear Layer không có activation vì:
- Bản chất là phép chiếu chứ không phải trích xuất (Extraction): BERT cực kỳ mạnh mẽ với hàng chục lớp Transformer và Activation (GELU). Nhiệm vụ của lớp Linear ở cuối không phải là học thêm các tính chất phi tuyến phức tạp, mà đơn giản là nén không gian vector từ 768 chiều xuống m chiều.
- Bảo toàn thông tin và Hướng: Nếu thêm một activation như ReLU, sẽ vô tình triệt tiêu toàn bộ các giá trị âm. Trong không gian vector để tính Dot Product, các giá trị âm mang thông tin cực kỳ quan trọng về sự "đối lập" hoặc "khác biệt" giữa các từ. Việc giữ lớp Linear thuần túy giúp bảo toàn trọn vẹn đặc trưng mà BERT đã học được.
- Tối ưu cho L2 Normalization: việc có một hàm Activation trước đó có thể làm biến dạng phân phối của các giá trị, khiến việc chuẩn hóa không còn phản ánh đúng tương quan ngữ nghĩa mà BERT tạo ra.
☝ Paper nhấn mạnh m chiều ảnh hưởng lớn:
- Đối với Document: Lưu trữ hàng tỷ vector token tốn rất nhiều chỗ; m càng nhỏ, lưu trữ càng nhẹ.
- Đối với Tốc độ: Khi chạy Ranking, hệ thống phải chuyển các vector từ RAM (CPU) lên GPU; m càng nhỏ, tốc độ truyền tải (transfer time) càng nhanh. Đây thường là bước tốn kém nhất trong quá trình Reranking với ColBERT.
- Normalization: Áp dụng L2 Normalization để mọi vector đều có độ dài bằng 1. Điều này giúp dot product sau này tương đương với Cosine Similarity.
- Output: Một ma trận , trong đó là số lượng token trong query. Với # là token [mask]:
Thực tế: Trong mã nguồn và các giải thích sâu hơn của tác giả, CNN ở đây thường được hiểu là một lớp Convolution 1D với kernel size = 1 (nó tương đương với lớp Linear layer đề cập bên trên). Việc dùng kernel size 1 giúp nó xử lý từng token embedding một cách độc lập mà không làm trộn lẫn thông tin giữa các token lân cận (vì việc trộn lẫn đã được lớp Self-attention của BERT làm rồi).
2.2.2 Document Encoder ()
- Input: Văn bản d được thêm tiền tố [D].
📌 Cấu trúc Input: [CLS] [D] d1 d2 ... dn (Không có [mask]).
- Processing: Tương tự Query Encoder nhưng có một bước cực kỳ quan trọng: Punctuation Filtering.
💡 Punctuation Filtering (Bộ lọc dấu câu):
- Sau khi đi qua BERT và lớp Linear, ColBERT sẽ xóa bỏ các vector ứng với các dấu câu (., !, ?...).
- Lý do: Các dấu câu dù có ngữ cảnh (contextualized) nhưng không đóng góp nhiều vào giá trị tìm kiếm thông tin. Việc loại bỏ chúng giúp giảm số lượng vector cần lưu trữ trên mỗi document, trực tiếp làm giảm dung lượng lưu trữ và tăng tốc độ truyền dữ liệu từ CPU lên GPU khi Ranking.
- Output: Một ma trận , trong đó n là số lượng token hữu ích trong document.
2.3 Cơ chế Late Interaction với phép toán MaxSim (Maximum Similarity)
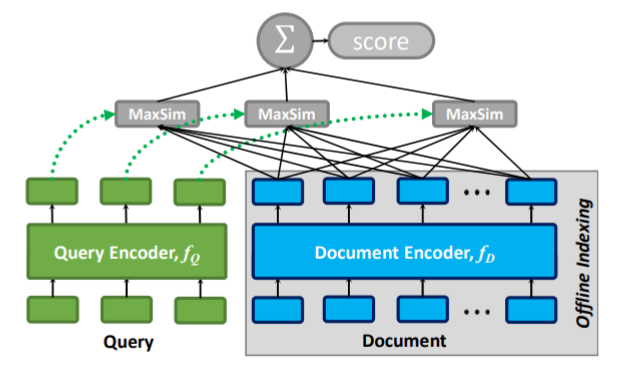
Đây là "linh hồn" của ColBERT, thứ giúp nó khác biệt hoàn toàn với Dense Retrieval truyền thống (như SBERT).
Thay vì nén cả ma trận thành 1 vector, ColBERT giữ nguyên toàn bộ tập hợp các vector token. Khi tính toán độ liên quan giữa Query và Document, nó thực hiện toán tử MaxSim:
💡 Dùng Dot-product vì các vector đã được L2-Normalized. Khi đó, Dot-product chính là Cosine Similarity, tính toán trên GPU nhanh hơn rất nhiều so với các hàm Cosine phức tạp.
💡 Cơ chế "Non-trainable Interaction":
- Bản thân cơ chế MaxSim không có tham số nào để học (no trainable parameters). Nó chỉ là một phép toán cộng và tìm Max đơn thuần.
- Ý nghĩa: Điều này giúp bước tương tác cực kỳ nhẹ về mặt tính toán, vì nó không phải chạy qua bất kỳ lớp Neural Network nào nữa.
Phân tích chi tiết bước này:
- Giải mã: Với mỗi token trong câu hỏi (), hệ thống tìm kiếm trong toàn bộ văn bản để chọn ra token () có độ tương đồng lớn nhất với nó.
- Tinh điểm: Nó cộng tất cả các giá trị tương đồng lớn nhất đó lại để ra điểm số cuối cùng.
- Ý nghĩa: Nó cho phép "Soft Keyword Matching": Vừa khớp từ khóa chính xác, vừa khớp ngữ nghĩa linh hoạt.
🗒️ Paper cung cấp thông tin Training Strategy:
- Dữ liệu đầu vào: Một bộ ba (Triple) gồm: q (câu hỏi), (văn bản đúng/tích cực) và (văn bản sai/tiêu cực).
- Mục tiêu (Loss Function): Sử dụng Pairwise Softmax Cross-entropy.
- Logic: Mô hình sẽ cố gắng tối ưu sao cho điểm phải lớn hơn hẳn điểm BERT sẽ phải tự học cách tạo ra các vector sao cho khi thực hiện phép toán MaxSim, văn bản đúng sẽ "khớp" với câu hỏi tốt hơn văn >bản sai.
3. Tính toán và lưu trữ Embedding Document (Offline Indexing)
Một trong những thách thức lớn nhất của kiến trúc Multi-vector là chi phí lưu trữ và tính toán. ColBERT giải quyết vấn đề này thông qua quy trình lập chỉ mục tách biệt hoàn toàn.
3.1 Triết lý Cách ly Tính toán (Isolation of Computation)
ColBERT được thiết kế để tách biệt quá trình mã hóa Query và Document. Điều này cho phép hệ thống tính toán và lưu trữ toàn bộ tập hợp embedding của tài liệu Offline. Khi có truy vấn, hệ thống chỉ cần tính toán duy nhất một ma trận và thực hiện tra cứu trên các đã có sẵn.
3.2 Lưu trữ Embedding (Storage)
- Sau khi tính toán xong, các vector được lưu xuống đĩa (Disk).
- Định dạng: Sử dụng giá trị 32-bit (float32) hoặc 16-bit (float16) cho mỗi chiều của vector.
- Mục đích sử dụng:
- Ranking: Load trực tiếp từ đĩa lên RAM/GPU để xếp hạng.
- Vector-similarity search: Tiếp tục được đánh chỉ mục (index) để tìm kiếm bằng các thuật toán vector (như FAISS).
3.3 Tối ưu hóa hiệu suất Indexing
Để xử lý hàng triệu tài liệu, ColBERT áp dụng các kỹ thuật tối ưu hóa phần cứng và thuật toán:
- Length-based Bucketing (BucketIterator):
- Vấn đề: Các tài liệu trong cùng một batch có độ dài khác nhau dẫn đến lãng phí tài nguyên GPU do cơ chế Padding.
- Giải pháp: Hệ thống gom nhóm tài liệu (ví dụ 100,000 bản ghi), sắp xếp theo độ dài, sau đó mới chia thành các batch nhỏ hơn để đưa vào GPU. Kỹ thuật này giảm thiểu tối đa lượng padding, giúp tăng băng thông xử lý của GPU.
💡 Cơ chế Padding: Trong một batch, nếu có 1 văn bản rất dài và nhiều văn bản rất ngắn, các văn bản ngắn sẽ phải "pad" (thêm các token trống) cho bằng văn bản dài nhất. Việc này làm GPU tốn bộ nhớ vô ích cho các token trống đó.
- CPU-GPU Parallelism:
- Việc xử lý tiền dữ liệu (WordPiece Tokenization) thường là bottleneck trên CPU. ColBERT thực hiện song song hóa quá trình này trên nhiều nhân CPU trong khi GPU thực hiện tính toán ma trận, đảm bảo luồng dữ liệu liên tục.
4. Luồng triển khai ColBERT với bài toán Re-ranking và Top-k Retrieval
ColBERT không chỉ là một mô hình học sâu, nó là một hệ thống tìm kiếm hai giai đoạn được tối ưu hóa cho hiệu suất thực tế. Có hai kịch bản triển khai chính:
4.1 Top-k Re-ranking
Trong kịch bản này, ColBERT được sử dụng để lọc lại kết quả từ một bộ tìm kiếm thô (thường là BM25). Mục tiêu là xếp hạng lại một tập nhỏ tài liệu (ví dụ: k = 1000) để đạt độ chính xác cao nhất.
Quy trình thực thi chi tiết:
- Query Encoding: Hệ thống nhận câu hỏi, chạy qua Query Encoder (BERT + Linear) duy nhất 1 lần để tạo ra ma trận embedding .
- Batch Gathering (Concurrently): đồng thời, hệ thống tải k ma trận embedding của k tài liệu ứng viên từ RAM CPU. Các ma trận này được gom lại thành một Tensor 3 chiều . Tensor này có kích thước , cho phép GPU thực hiện phép nhân ma trận hàng loạt (batch dot-product) thay vì phải xử lý từng tài liệu một cách tuần tự.
- Data Transfer: Chuyển Tensor từ bộ nhớ hệ thống lên bộ nhớ GPU (VRAM). Đây là bước tốn kém nhất về mặt thời gian trong quá trình Re-ranking.
- Batch Dot-Product: Trên GPU, thực hiện phép nhân ma trận hàng loạt giữa và Tensor . Kết quả trả về là một Tensor 3 chiều chứa các ma trận tương đồng (cross-match matrices) giữa query và từng tài liệu.
- MaxSim Reduction:
- Max-pooling: Với mỗi tài liệu, thực hiện tìm giá trị lớn nhất trên các cột (đại diện cho các token của tài liệu) để lấy ra điểm tương đồng lớn nhất cho mỗi từ trong query.
- Summation: Cộng dồn các giá trị Max này lại để ra điểm số cuối cùng cho tài liệu đó.
- Sorting: Sắp xếp tài liệu dựa trên điểm số để trả về kết quả cuối cùng.
4.2 Top-k Retrieval (End-to-End)
Khi số lượng tài liệu N quá lớn (ví dụ: 10 000 000), việc tính toán MaxSim cho toàn bộ là không khả thi. ColBERT sử dụng quy trình Tìm kiếm hai giai đoạn (Two-stage procedure) dựa trên thư viện FAISS.
Giai đoạn 1: Approximate Stage - Filtering
Hệ thống coi mọi token embedding của mọi tài liệu là một thực thể độc lập trong không gian vector.
- Indexing: Toàn bộ document embeddings được đưa vào một cấu trúc dữ liệu IVFPQ (Inverted File with Product Quantization) của Faiss.
- IVF: Phân vùng không gian vector thành P vùng (cells) bằng K-means. Khi tìm kiếm, hệ thống chỉ quét qua p (hyperparameter) **vùng gần nhất.
- PQ: Chia nhỏ mỗi vector thành các sub-vectors và nén chúng lại để tiết kiệm RAM.
- Search: Với mỗi vector trong số vectors của (), hệ thống thực hiện truy vấn tìm kiếm vector-similarity đồng thời trên Faiss.
- Mỗi vector query trả về kết quả gần nhất.
- Hệ thống ánh xạ (map) các vector này về ID tài liệu gốc của chúng.
- Kết quả là một tập hợp tài liệu ứng viên ().
Giai đoạn 2: Refinement Stage - Re-ranking
Sau khi có tập hợp tài liệu tiềm năng (thường nhỏ hơn rất nhiều so với ), hệ thống thực hiện quy trình Re-ranking chi tiết (như mô tả ở phần 3.1). Bước này đảm bảo độ chính xác tối đa bằng cách tính toán MaxSim đầy đủ thay vì dựa trên các vector nén xấp xỉ của Faiss.
5. So sánh hiệu năng của ColBERT
📌 Các số liệu độ trễ được đo đạc trên cấu hình tiêu chuẩn:
- GPU: 1x NVIDIA Tesla V100 (32GB VRAM).
- CPU: Intel Xeon Gold 6132 (28 nhân vật lý).
- RAM: 469 GiB.
📌 Chỉ số đánh giá:
- MRR@10 (Mean Reciprocal Rank): Đánh giá khả năng đưa kết quả đúng lên vị trí đầu tiên. Điểm càng gần 1 càng tốt.
- Recall@k: Đánh giá khả năng "vét" sạch tài liệu đúng trong kho dữ liệu vào Top k .
- FLOPs (Floating Point Operations): Đại diện cho khối lượng công việc mà GPU phải xử lý. FLOPs thấp đồng nghĩa với tốc độ nhanh và chi phí vận hành rẻ.
- Latency (ms): Thời gian phản hồi của hệ thống (tính bằng mili giây).
5.1 Hiệu năng Re-ranking trên tập dữ liệu MS MARCO
Trong thử nghiệm này, ColBERT được dùng để Re-rank top-1000 tài liệu được trả về từ mô hình truyền thống BM25 trên tập dữ liệu MS MARCO (8.8 triệu đoạn văn bản).
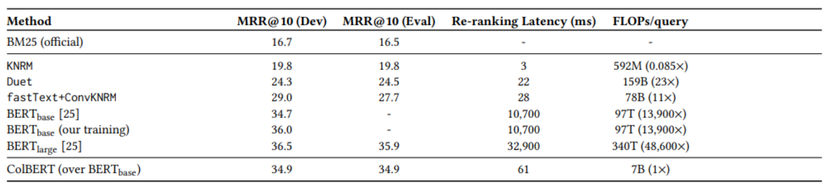
Nhận xét:
- Accuracy-Efficiency Trade-off: Thông thường, các mô hình nhanh hơn sẽ kém chính xác hơn. Tuy nhiên, ColBERT đạt MRR@10 nhỉnh hơn cả BERT-base (34.9 vs 34.7) trong khi nhanh hơn gấp 175 lần. Điều này chứng minh cơ chế Late Interaction có khả năng biểu diễn ngữ nghĩa tương đương với Full Self-Attention của Cross-Encoder.
- Tiết kiệm tài nguyên tính toán: Chỉ số FLOPs của ColBERT thấp hơn BERT-base tới 13,900 lần. Điều này cho thấy ColBERT cực kỳ thân thiện với phần cứng, cho phép triển khai trên các dòng GPU phổ thông thay vì các cụm máy chủ đắt đỏ.
- Tối ưu cho Real-time: Với độ trễ 61ms, ColBERT đưa tìm kiếm Neural IR vào ngưỡng phản hồi thời gian thực (real-time), mở đường cho việc áp dụng AI vào các công cụ tìm kiếm quy mô lớn.
5.2 Hiệu năng Retrieval trên tập dữ liệu MS MARCO
Trong thử nghiệm này, ColBERT được dùng để Retrieval top-1000 tài liệu trực tiếp trên tập dữ liệu MS MARCO (8.8 triệu đoạn văn bản).

Nhận xét:
- Đột phá về Recall: ColBERT đạt Recall@50 là 82.9%, con số này thậm chí còn cao hơn cả Recall@1000 của BM25 (81.4% theo bản ocial). Điều này cực kỳ quan trọng: Nó có nghĩa là ColBERT tìm thấy nhiều tài liệu liên quan trọng Top 50 hơn cả số lượng tài liệu mà BM25 tìm thấy trong tận Top 1000.
- Vượt xa các mô hình mở rộng văn bản (Document Expansion): Ngay cả khi so sánh với docTTTTTquery (một mô hình dùng T5 để mở rộng từ khóa cực mạnh), ColBERT vẫn áp đảo về MRR@10 (36.0 vs 27.7). Điều này cho thấy việc lưu trữ đa vector (multi-vector) hiệu quả hơn hẳn việc cố gắng nén thông tin vào các từ khóa đơn lẻ.
- Hiệu quả: Một insight thú vị từ paper là việc dùng ColBERT để tìm kiếm trực tiếp (End-to-End) cho kết quả (MRR 36.0) tốt hơn cả việc dùng ColBERT để Re-rank kết quả của BM25 (MRR 34.9).
- Lý do: BM25 đôi khi "bỏ sót" những tài liệu có sự tương đồng ngữ nghĩa nhưng không trùng khớp từ khóa. Khi ColBERT tự mình đi tìm, nó không bị giới hạn bởi bộ lọc thô của BM25 và có thể "vớt" được những tài liệu quý giá đó ngay từ giai đoạn đầu.
- Độ trễ chấp nhận được: 458ms cho việc tìm kiếm Neural trên 8.8 triệu tài liệu là tương đối cao, nhưng chất lượng kết quả mang lại (gần gấp đôi MRR) hoàn toàn xứng đáng cho các ứng dụng đòi hỏi độ chính xác cao như hệ thống hỏi đáp (QA) hay RAG chuyên sâu.
Kết luận
ColBERT v1 là mô hình tiên phong trong kiến trúc tương tác muộn (late interaction), cho phép mã hóa độc lập truy vấn và tài liệu thành các tập vector rồi tính điểm liên quan qua toán tử MaxSim,,. Phương pháp này giúp duy trì độ chính xác cao của BERT nhưng đạt tốc độ nhanh hơn 170 lần và giảm lượng tính toán 14.000 lần nhờ khả năng tính toán trước và lưu trữ tài liệu ngoại tuyến,.
Tuy nhiên, hạn chế lớn nhất của v1 là chiếm dụng không gian lưu trữ cực lớn (≥ 154 GiB cho tập dữ liệu MS MARCO), cao hơn gấp 10 lần so với các mô hình vector đơn,. Nguyên nhân là do v1 phải lưu trữ hàng tỷ vector chi tiết cho mọi token trong toàn bộ tập dữ liệu mà chưa có cơ chế nén hiệu quả
Link đính kèm và Tài liệu tham khảo:
All rights reserved
