Kafka vs Redis: Phân tích kiến trúc dữ liệu và lựa chọn tối ưu cho hệ thống real-time
Trong quá trình xây dựng các hệ thống xử lý dữ liệu ngày nay, nhiều doanh nghiệp thường đứng trước một lựa chọn tưởng chừng đơn giản: sử dụng Kafka hay Redis. Tuy nhiên, nếu nhìn sâu vào kiến trúc, đây không phải là hai công nghệ “cùng vai trò” để so sánh trực tiếp, mà là hai hướng tiếp cận hoàn toàn khác nhau đối với dữ liệu.
Kafka đại diện cho tư duy xử lý dữ liệu theo dòng chảy liên tục (streaming), nơi mỗi sự kiện đều được ghi lại, lưu trữ và có thể truy xuất lại bất cứ lúc nào. Trong khi đó, Redis lại tập trung vào tốc độ truy cập, tối ưu cho việc đọc – ghi tức thời với độ trễ cực thấp. Chính sự khác biệt về triết lý thiết kế này tạo ra khoảng cách rõ rệt trong cách hai hệ thống vận hành.
Khi dữ liệu không chỉ là lưu trữ, mà là dòng chảy
Kafka được xây dựng như một hệ thống log phân tán, nơi mọi dữ liệu đều được ghi lại theo thứ tự và tồn tại trong một khoảng thời gian nhất định. Điều này mang lại một lợi thế quan trọng: dữ liệu không “biến mất” sau khi được xử lý.
Trong thực tế, điều này có nghĩa là một hệ thống sử dụng Kafka có thể:
- Đọc lại dữ liệu cũ để phân tích,
- Khôi phục trạng thái khi có lỗi,
- Hoặc tái xử lý toàn bộ pipeline nếu cần.
Ngược lại, Redis không được thiết kế cho mục tiêu đó. Là một cơ sở dữ liệu in-memory, Redis ưu tiên việc phản hồi nhanh hơn là lưu trữ lâu dài. Dữ liệu trong Redis thường mang tính tạm thời, phục vụ cho những tác vụ cần tốc độ như cache, session hoặc các thao tác real-time.
Sự khác biệt này giống như việc so sánh một hệ thống lưu trữ lịch sử giao dịch đầy đủ với một bộ nhớ đệm giúp tăng tốc truy vấn, cả hai đều quan trọng, nhưng phục vụ những mục tiêu khác nhau.
Cách dữ liệu được “di chuyển” trong hệ thống
Một trong những điểm khác biệt mang tính bản chất giữa Kafka và Redis nằm ở cách dữ liệu được truyền đi.
Kafka hoạt động theo cơ chế “pull”, tức là phía consumer chủ động lấy dữ liệu khi cần. Điều này giúp hệ thống kiểm soát tốt hơn quá trình xử lý, tránh việc bị quá tải và cho phép quản lý trạng thái tiêu thụ dữ liệu thông qua offset.
Trong khi đó, Redis sử dụng mô hình “push” trong Pub/Sub, nghĩa là dữ liệu sẽ được gửi ngay lập tức đến các subscriber. Cách tiếp cận này phù hợp với các hệ thống cần phản hồi nhanh, nhưng lại không đảm bảo khả năng kiểm soát hay lưu trữ lịch sử dữ liệu.
Vì vậy, nếu hệ thống của bạn cần đảm bảo rằng không một message nào bị bỏ lỡ, Kafka sẽ là lựa chọn phù hợp hơn. Còn nếu mục tiêu là truyền tải thông tin nhanh nhất có thể, Redis sẽ phát huy tối đa lợi thế của mình.
Hiệu năng
Redis nổi tiếng với tốc độ xử lý cực nhanh nhờ lưu trữ dữ liệu trên RAM. Trong nhiều trường hợp, thời gian phản hồi chỉ tính bằng microseconds, gần như tức thì đối với người dùng.
Kafka, ngược lại, không tối ưu cho độ trễ thấp nhất mà tập trung vào khả năng xử lý khối lượng dữ liệu lớn với thông lượng cao. Việc ghi dữ liệu xuống disk, kết hợp với cơ chế replication, giúp Kafka đảm bảo tính bền vững và khả năng mở rộng, dù phải đánh đổi một phần về độ trễ.
Điều này dẫn đến một nguyên tắc quan trọng trong thiết kế hệ thống: Redis tối ưu cho latency, Kafka tối ưu cho throughput.
Và trong nhiều hệ thống lớn, cả hai thường được sử dụng song song để tận dụng ưu điểm của từng công nghệ.
Khả năng chịu lỗi và tính tin cậy của dữ liệu
Trong các hệ thống phân tán, việc đảm bảo dữ liệu không bị mất khi xảy ra sự cố là yếu tố then chốt.
Kafka giải quyết bài toán này bằng cách sao chép dữ liệu trên nhiều broker khác nhau. Ngay cả khi một node gặp sự cố, dữ liệu vẫn được giữ nguyên và có thể tiếp tục phục vụ các consumer khác.
Redis cũng có các cơ chế persistence như RDB hoặc AOF, nhưng đây không phải là thiết kế mặc định. Nếu không được cấu hình đúng, Redis có thể mất dữ liệu khi xảy ra sự cố hệ thống.
Vì vậy, Kafka thường được sử dụng như một lớp “xương sống dữ liệu” (data backbone), còn Redis đóng vai trò lớp tăng tốc phía trên.
Khi nào nên chọn Kafka và khi nào nên chọn Redis?
Nếu hệ thống của bạn xử lý dữ liệu lớn, cần phân tích theo thời gian thực, hoặc xây dựng kiến trúc event-driven, Kafka gần như là lựa chọn bắt buộc. Đây là nền tảng phù hợp cho các pipeline dữ liệu, hệ thống log, IoT hoặc các ứng dụng tài chính.
Ngược lại, Redis phát huy sức mạnh trong các bài toán yêu cầu phản hồi nhanh: cache dữ liệu, quản lý session, leaderboard hoặc các hệ thống cần truy xuất tức thời.
Một sai lầm phổ biến là cố gắng sử dụng Redis như một message broker đầy đủ chức năng, hoặc dùng Kafka cho những tác vụ đơn giản như cache. Điều này không chỉ làm tăng độ phức tạp mà còn khiến hệ thống hoạt động kém hiệu quả.
Góc nhìn thực tế
Trong kiến trúc hiện đại, Kafka và Redis thường không cạnh tranh mà bổ trợ cho nhau.
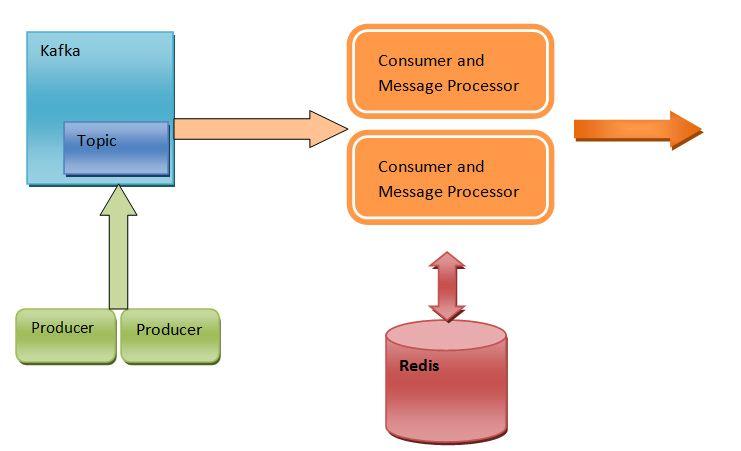
Kafka đảm nhiệm việc tiếp nhận và xử lý dòng dữ liệu lớn, đảm bảo mọi sự kiện đều được ghi nhận và có thể phân tích. Sau đó, kết quả được đẩy sang Redis để phục vụ truy vấn nhanh cho người dùng cuối.
Mô hình này giúp hệ thống vừa đảm bảo độ chính xác của dữ liệu, vừa duy trì trải nghiệm mượt mà với độ trễ thấp.
Kết luận
Kafka và Redis đại diện cho hai lớp khác nhau trong kiến trúc dữ liệu: một bên là xử lý và lưu trữ dòng sự kiện quy mô lớn, một bên là tối ưu tốc độ truy xuất và phản hồi.
Việc lựa chọn không nằm ở việc công nghệ nào “mạnh hơn”, mà ở việc hiểu rõ bài toán hệ thống đang cần giải quyết là gì. Trong nhiều trường hợp, câu trả lời tối ưu không phải là Kafka hay Redis, mà là cách kết hợp cả hai để tạo nên một kiến trúc cân bằng giữa hiệu năng và độ tin cậy.
All rights reserved
