
Kafka và RabbitMQ – Hệ thống Xếp hàng hay Nền tảng Streaming?
Chào mừng đến với vũ trụ Microservices, nơi mọi thứ đều phân tán, phức tạp, và mọi ứng dụng đều cần một bộ phận đưa thư đáng tin cậy. Nếu bạn cảm thấy như đang tổ chức một bữa tiệc lớn mà không biết nên thuê bưu điện truyền thống (với các giao thức nghiêm ngặt) hay một công ty chuyển phát nhanh siêu tốc (chuyên trị data stream không ngừng nghỉ), thì bạn không cô độc.
Hai "ông lớn" RabbitMQ và Apache Kafka chính là những ứng viên hàng đầu. Một bên là Broker truyền thống, cẩn thận, đảm bảo tin nhắn được xử lý từng cái một – đúng kiểu "nhân viên ngân hàng" của thế giới messaging. Bên kia là nền tảng Streaming tốc độ ánh sáng, chuyên gia về dữ liệu lịch sử và thông lượng khổng lồ – giống như "nhật ký vĩnh cửu" của hệ thống. Lựa chọn sai ư? Có thể bạn sẽ phải đối mặt với tình trạng tắc đường dữ liệu hoặc không thể "replay" lại những sai lầm trong quá khứ. Hãy cùng so sánh để xem ai sẽ là người hùng giải cứu kiến trúc của bạn nhé!

I. Giới thiệu: Sự trỗi dậy của Giao tiếp Phi đồng bộ
Trong một kiến trúc Microservices điển hình, các dịch vụ không nên gọi trực tiếp lẫn nhau (trừ các trường hợp đặc biệt). Thay vào đó, chúng giao tiếp một cách phi đồng bộ (asynchronously) thông qua tin nhắn hoặc sự kiện. Điều này giúp các dịch vụ hoạt động độc lập, không bị phụ thuộc vào sự sẵn có của dịch vụ khác.
RabbitMQ và Kafka là hai giải pháp hàng đầu giải quyết vấn đề này, nhưng chúng sinh ra với những mục đích rất khác nhau:
-
RabbitMQ (Message Broker): Tập trung vào việc chuyển giao tin nhắn một cách đáng tin cậy từ A đến B, sau đó xóa tin nhắn đi. Nó tối ưu cho các tác vụ ngắn hạn (task-queue).
-
Apache Kafka (Event Streaming Platform): Tập trung vào việc ghi lại, lưu trữ (lâu dài), và xử lý luồng sự kiện theo thời gian thực. Nó tối ưu cho thông lượng cao và phân tích dữ liệu.
Mục tiêu của bài viết này là làm sáng tỏ sự khác biệt kiến trúc và tính năng của chúng, giúp bạn đưa ra quyết định sáng suốt cho hệ thống của mình.
II. Tổng quan về RabbitMQ: Người đưa thư đáng tin cậy
RabbitMQ là một Message Broker mã nguồn mở, triển khai giao thức AMQP (Advanced Message Queuing Protocol) và hỗ trợ nhiều giao thức khác như STOMP, MQTT. Nó tuân theo triết lý Smart Broker, Dumb Consumer.
1. Mô hình hoạt động và các thành phần cốt lõi
Kiến trúc của RabbitMQ xoay quanh bốn thành phần chính:
- Producer (Người sản xuất): Ứng dụng gửi tin nhắn.
- Exchange (Sàn giao dịch): Nơi nhận tin nhắn từ Producer và định tuyến chúng đến các Queue. Exchange không lưu trữ tin nhắn, mà hoạt động như một bộ lọc.
- Queue (Hàng chờ): Nơi lưu trữ tin nhắn cho đến khi Consumer xử lý. Đây là linh hồn của RabbitMQ.
- Consumer (Người tiêu thụ): Ứng dụng kết nối với Queue và nhận tin nhắn để xử lý.
Điểm đặc trưng: Smart Broker, Dumb Consumer. Trong RabbitMQ, Broker (Exchange và Queue) giữ vai trò quản lý chính. Broker quyết định tin nhắn đi đâu (Routing), Queue lưu trữ trạng thái, và quan trọng nhất là Broker sẽ xóa tin nhắn ngay sau khi Consumer xác nhận (Acknowledgement) rằng nó đã xử lý xong. Consumer chỉ cần nhận và xử lý mà không cần lo lắng về việc quản lý trạng thái tin nhắn.
2. Các tính năng chính
- Routing linh hoạt: RabbitMQ cung cấp nhiều loại Exchange:
- Direct: Định tuyến tin nhắn dựa trên khóa định tuyến chính xác.
- Topic: Định tuyến tin nhắn dựa trên các mẫu (pattern matching).
- Fanout: Gửi tin nhắn đến tất cả các Queue được liên kết (Broadcast).
- Độ tin cậy cao: RabbitMQ đảm bảo tin nhắn không bị mất mát nhờ cơ chế Persistence (lưu trữ tin nhắn trên đĩa) và Message Acknowledgement (xác nhận từ Consumer).
- Worker Queues: Cho phép nhiều Consumer cùng nhận tin nhắn từ một Queue duy nhất, đảm bảo tính năng Point-to-Point (mỗi tin nhắn chỉ được xử lý bởi một Consumer) – lý tưởng cho các tác vụ nền.
3. Trường hợp sử dụng tiêu biểu
RabbitMQ là lựa chọn hoàn hảo cho các tác vụ yêu cầu độ tin cậy và xử lý riêng biệt:
- Xử lý tác vụ nền (Background Jobs): Gửi email, tạo báo cáo, nén/resize ảnh.
- Phân phối tác vụ: Đảm bảo mỗi công việc nặng (ví dụ: tính toán phức tạp) chỉ được giao cho một Worker xử lý.
- Giao tiếp yêu cầu-phản hồi: Sử dụng các Queue tạm thời để phản hồi lại dịch vụ yêu cầu.
III. Tổng quan về Apache Kafka: Nhật ký sự kiện vĩnh cửu
Kafka, ban đầu được phát triển tại LinkedIn, không chỉ là một Message Broker; nó là một Nền tảng Event Streaming phân tán. Nó tuân theo triết lý ngược lại: Dumb Broker, Smart Consumer.
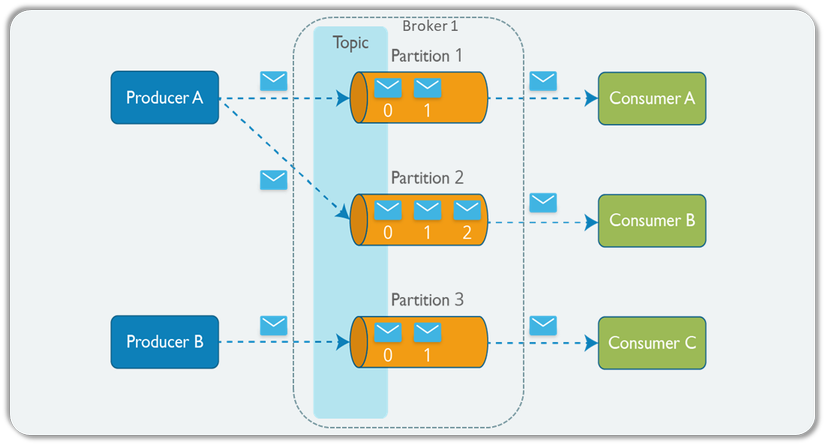
1. Mô hình hoạt động và các thành phần cốt lõi
- Kafka hoạt động như một nhật ký cam kết phân tán (distributed commit log).
- Producer (Người sản xuất): Gửi sự kiện/tin nhắn đến các Topic.
- Topic (Chủ đề): Một danh mục nơi các tin nhắn được lưu trữ. Topic được chia thành nhiều Partitions.
- Partition (Phân vùng): Một log file có thứ tự (ordered, immutable sequence of records). Mỗi tin nhắn trong Partition có một Offset (vị trí duy nhất).
- Broker (Máy chủ): Các máy chủ Kafka lưu trữ các Partitions.
- Consumer Group (Nhóm tiêu thụ): Một nhóm các Consumer làm việc cùng nhau. Mỗi Partition chỉ được đọc bởi một Consumer duy nhất trong Group đó.
Điểm đặc trưng: Dumb Broker, Smart Consumer. Kafka Broker không theo dõi tin nhắn nào đã được đọc. Thay vào đó, Consumer Group tự quản lý vị trí (Offset) mà chúng đã đọc gần nhất. Điều này cho phép Broker tập trung toàn bộ tài nguyên vào việc lưu trữ và phục vụ data stream với thông lượng cực cao.
2. Các tính năng chính
- Thông lượng và khả năng mở rộng: Kafka được thiết kế để xử lý lượng tin nhắn khổng lồ bằng cách phân tán dữ liệu và tải xử lý trên nhiều Partitions và Brokers.
- Lưu trữ sự kiện vĩnh viễn (Persistence): Tin nhắn không bị xóa ngay sau khi đọc mà được giữ lại theo một khoảng thời gian cấu hình (Retention Policy), cho phép Replay (đọc lại dữ liệu lịch sử).
- Đảm bảo thứ tự: Thứ tự tin nhắn được đảm bảo trong phạm vi một Partition.
- Hệ sinh thái: Kafka đi kèm với Kafka Connect (tích hợp với các hệ thống dữ liệu khác) và Kafka Streams (thư viện xử lý luồng dữ liệu).
3. Trường hợp sử dụng tiêu biểu
Kafka là lựa chọn lý tưởng cho các ứng dụng đòi hỏi xử lý dữ liệu lớn theo thời gian thực:
- Data Pipeline: Di chuyển dữ liệu giữa các hệ thống (database, data lake).
- Event Sourcing: Lưu trữ tất cả các sự kiện thay đổi trạng thái của ứng dụng, cho phép tái tạo lại trạng thái bất cứ lúc nào.
- Log Aggregation: Thu thập và tổng hợp log từ hàng trăm dịch vụ phân tán.
- Real-time Analytics: Xử lý luồng dữ liệu giao dịch hoặc clickstream ngay khi chúng xảy ra.
IV. Vậy khi nào nên chọn Kafka? Khi nào nên chọn RabbitMQ?
Sự khác biệt cốt lõi giữa Kafka và RabbitMQ nằm ở cách chúng tiếp cận khái niệm tin nhắn và việc quản lý trạng thái.
| Tiêu chí | RabbitMQ (Smart Broker) | Kafka (Dumb Broker) |
|---|---|---|
| Quản lý trạng thái | Broker quản lý trạng thái của tin nhắn (đã gửi, đã nhận). | Consumer quản lý trạng thái đọc (Offset). |
| Cách xóa tin nhắn | Tin nhắn bị xóa ngay sau khi Consumer xác nhận (ack). | Tin nhắn được lưu trữ trên log (Persistence) cho đến khi hết thời gian giữ (Retention Policy). |
| Mô hình Consumer | Worker Queue (Point-to-Point): Mỗi tin nhắn chỉ được một Consumer xử lý. | Consumer Group (Publish/Subscribe): Nhiều nhóm Consumer khác nhau có thể đọc cùng một luồng dữ liệu mà không ảnh hưởng lẫn nhau. |
-
Chọn RabbitMQ khi:
- Cần Worker Queue và đảm bảo xử lý duy nhất: Bạn có các tác vụ nặng cần được xử lý riêng biệt (ví dụ: in hóa đơn, gửi SMS) và cần đảm bảo mỗi tin nhắn chỉ được tiêu thụ bởi một Worker duy nhất.
- Yêu cầu Routing phức tạp: Bạn cần định tuyến tin nhắn linh hoạt dựa trên nhiều tiêu chí (Exchange Types).
- Ưu tiên Độ tin cậy và Độ trễ thấp: Đối với các tác vụ yêu cầu độ trễ thấp và độ tin cậy tuyệt đối trong việc chuyển giao (như thông báo quan trọng).
- Hệ thống quy mô nhỏ đến trung bình: Dễ triển khai và quản lý hơn.
-
Chọn Kafka khi:
- Cần xử lý Thông lượng khổng lồ: Xử lý dữ liệu lớn theo thời gian thực (log data, clickstream, IoT sensor data).
- Xây dựng Event Sourcing và Data Pipeline: Bạn cần một nguồn sự kiện đáng tin cậy (Source of Truth) và khả năng Replay để xây dựng lại trạng thái hệ thống.
- Cần nhiều Consumer đọc cùng một luồng dữ liệu: Bạn có nhiều nhóm phân tích hoặc dịch vụ muốn tiêu thụ cùng một luồng sự kiện mà không ảnh hưởng đến luồng chính.
- Cần khả năng xử lý luồng (Stream Processing): Tận dụng Kafka Streams hoặc ksqlDB để biến đổi và xử lý dữ liệu ngay trên luồng.
VI. Kết luận:
RabbitMQ và Kafka, mặc dù cùng phục vụ mục đích giao tiếp phi đồng bộ, nhưng lại đại diện cho hai triết lý kiến trúc khác nhau:
- RabbitMQ là Message Queue cổ điển: Đảm bảo chuyển giao, xóa ngay sau khi hoàn thành.
- Kafka là Event Stream Platform: Đảm bảo lưu trữ, cho phép tái tạo và xử lý luồng dữ liệu.
Không có người chiến thắng tuyệt đối. Đôi khi, các kiến trúc phức tạp thậm chí sử dụng cả hai công cụ này: Kafka dùng để thu thập và lưu trữ luồng sự kiện lớn, sau đó chuyển một phần sự kiện nhỏ hơn (đã được xử lý hoặc tóm tắt) sang RabbitMQ Queue để kích hoạt các tác vụ nền yêu cầu độ tin cậy cao và xử lý duy nhất.
All rights reserved
