Kafka giải quyết bài toán gì mà Redis/RabbitMQ không làm được?
Vấn đề không nằm ở “tool nào nhanh hơn”
So sánh Kafka với Redis hay RabbitMQ thường bị kéo về câu hỏi quen thuộc: hệ thống nào nhanh hơn, latency thấp hơn, dễ dùng hơn. Nhưng nếu nhìn từ góc độ system design, đó không phải câu hỏi đúng.
Ba công cụ này được sinh ra để giải quyết ba lớp bài toán khác nhau:
- Redis: Xử lý nhanh trong memory
- RabbitMQ: Điều phối message theo mô hình queue
- Kafka: Tổ chức và lưu trữ dòng dữ liệu theo thời gian
Vì vậy, Kafka không phải là phiên bản “mạnh hơn” của queue. Nó giải quyết một bài toán mà queue và cache không được thiết kế để xử lý.
Kafka giải bài toán: Lưu lịch sử, không chỉ truyền dữ liệu
RabbitMQ và Redis Pub/Sub được thiết kế với một giả định ngầm: message chỉ cần được xử lý một lần rồi biến mất. Điều này rất phù hợp với các tác vụ như gửi email, xử lý background job, hoặc truyền tín hiệu giữa các service.
Nhưng khi hệ thống cần giữ lại toàn bộ lịch sử sự kiện, cách tiếp cận này không còn đủ.
Kafka giải bài toán khác:
Dữ liệu không chỉ để xử lý, mà còn phải được lưu lại như một dòng sự kiện
Ví dụ, với RabbitMQ:
- Message được consume → biến mất
- Không thể đọc lại nếu không có cơ chế riêng
Với Kafka:
- Event được ghi vào log
- Có thể đọc lại bất kỳ lúc nào
- Nhiều consumer có thể đọc cùng một dữ liệu
Điểm khác biệt này là nền tảng cho rất nhiều kiến trúc hiện đại.
Kafka cho phép replay, queue thì không
 Một trong những khả năng quan trọng nhất mà Kafka mang lại là replay dữ liệu.
Một trong những khả năng quan trọng nhất mà Kafka mang lại là replay dữ liệu.
Trong Kafka, consumer đọc dữ liệu theo offset. Điều này có nghĩa là:
- Có thể quay lại offset cũ
- Đọc lại toàn bộ dữ liệu
- Chạy lại logic khi cần
Ngược lại, với RabbitMQ:
- Message đã ack → không còn
- Muốn replay phải tự build lại hệ thống
Trong thực tế, replay là thứ cực kỳ quan trọng khi:
- Thay đổi business logic
- Fix bug
- Rebuild data pipeline
- Train lại hệ thống analytics
Kafka không chỉ giúp hệ thống chạy, mà còn giúp hệ thống có thể chạy lại.
Kafka cho phép nhiều consumer đọc cùng một data stream
Với queue truyền thống, một message thường chỉ được xử lý bởi một consumer. Điều này giúp phân phối công việc, nhưng lại hạn chế khi nhiều service cùng cần dữ liệu.
Kafka giải quyết bằng cách biến dữ liệu thành một stream chung:
- Service A đọc để xử lý nghiệp vụ
- Service B đọc để gửi email
- Service C đọc để analytics
- Service D đọc để machine learning
Tất cả cùng đọc từ một nguồn, nhưng không ảnh hưởng lẫn nhau.
Điều này giúp hệ thống mở rộng dễ dàng. Bạn có thể thêm một consumer mới mà không cần thay đổi producer hay các service khác.
Kafka tách rời hệ thống tốt hơn queue
Trong hệ thống dùng RabbitMQ, producer thường phải biết queue nào sẽ nhận message, và consumer nào sẽ xử lý. Mặc dù có abstraction, nhưng vẫn tồn tại coupling ở mức nhất định.
Kafka giảm coupling bằng cách:
- Producer chỉ publish event
- Consumer tự subscribe
Producer không cần biết ai đang đọc dữ liệu. Consumer cũng không cần biết dữ liệu đến từ đâu ngoài topic. Điều này đặc biệt quan trọng trong kiến trúc microservices, nơi số lượng service có thể tăng theo thời gian.
Kafka xử lý tốt bài toán data pipeline và stream processing
Redis và RabbitMQ phù hợp với message processing, nhưng không được thiết kế cho data pipeline quy mô lớn.
Kafka thì khác. Nó hoạt động tốt khi:
- Ingest hàng triệu event/giây
- Stream dữ liệu liên tục
- Làm nền tảng cho hệ thống analytics
Trong các pipeline như:
App → Kafka → Stream processing → Data warehouse
Kafka đóng vai trò trung tâm. Nó đảm bảo dữ liệu được lưu lại, phân phối và xử lý theo thời gian thực. Redis có thể nhanh, RabbitMQ có thể linh hoạt, nhưng cả hai không được thiết kế để làm backbone cho data pipeline lớn.
Kafka scale theo cách queue khó làm được
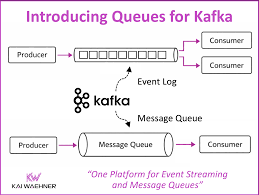 RabbitMQ scale bằng cách:
RabbitMQ scale bằng cách:
- Tăng số consumer
- Hoặc chia queue
Nhưng khi throughput quá lớn, việc scale trở nên phức tạp.
Kafka scale bằng partition:
- Chia log thành nhiều phần
- Phân phối trên nhiều node
- Consumer đọc song song
Cách scale này phù hợp hơn với dữ liệu dạng stream lớn và liên tục. Tuy nhiên, đổi lại là phải chấp nhận trade-off về ordering (chỉ đảm bảo trong partition).
Khi nào Kafka thực sự vượt trội?
Kafka không thay thế hoàn toàn Redis hay RabbitMQ. Nó vượt trội khi hệ thống có những đặc điểm sau:
- Cần lưu lịch sử sự kiện
- Cần replay dữ liệu
- Nhiều service cùng consume một data stream
- Xử lý dữ liệu realtime với throughput lớn
- Xây dựng data pipeline hoặc analytics system
Nếu hệ thống chỉ cần:
- Xử lý job đơn giản
- Gửi message một lần
- Latency cực thấp
Thì Redis hoặc RabbitMQ thường phù hợp hơn.
Kết luận
Kafka không phải là một message queue “mạnh hơn”. Nó giải quyết một bài toán khác: biến dữ liệu thành một dòng sự kiện có thể lưu trữ, đọc lại và xử lý nhiều lần. Redis và RabbitMQ rất tốt trong việc truyền và xử lý message. Nhưng khi hệ thống cần:
- Giữ lại lịch sử
- Tách rời các service
- Cho nhiều consumer đọc cùng dữ liệu
- Và xây dựng pipeline dữ liệu lớn
Thì Kafka trở thành lựa chọn phù hợp hơn.
All rights reserved
