[Join SQL] Thế giới hôn nhân của các bảng: Giải mã cơ chế Join trong SQL!
Bài đăng này đã không được cập nhật trong 3 năm
Xin chào các bạn, hôm nay mình sẽ cùng thảo luận một chút về cơ chế thực hiện phép JOIN các bảng trong cơ sở dữ liệu, cùng tìm hiểu các bảng lựa chọn cách để "tỏ tình" với bảng "người thương" của mình như thế nào.
Cơ chế join các bảng trong SQL là một khía cạnh quan trọng trong việc truy vấn dữ liệu từ cơ sở dữ liệu quan hệ. Khi làm việc với dữ liệu được phân tán trên nhiều bảng, việc kết hợp các bảng thông qua các phép join là cần thiết để thu thập thông tin và tạo ra kết quả mà chúng ta mong muốn. Thông thường chúng ta sẽ sử dụng phép join phổ biến như INNER JOIN, LEFT JOIN, RIGHT JOIN và FULL OUTER JOIN. Vậy thực chất phép JOIN sẽ xảy ra như thế nào và thuật toán nào để chúng kết hợp được với nhau.
Cơ chế kết hợp (join) các bảng trong SQL Oracle được thực hiện thông qua các phương pháp như Nested Loops Join, Hash Join và Sort Merge Join. Bằng việc hiểu rõ cơ chế join các bảng trong SQL, chúng ta sẽ có khả năng thiết kế và tối ưu hóa truy vấn dữ liệu hiệu quả hơn, đảm bảo rằng chúng ta nhận được kết quả chính xác và nhanh chóng từ cơ sở dữ liệu. Hãy cùng đi sâu vào cơ chế join các bảng trong SQL và khám phá những điều thú vị phía sau!

1. Nested Loops Join:
Nested Loops Join là phương pháp đơn giản nhất trong các phương pháp join. Khi sử dụng Nested Loops Join, hệ thống sẽ duyệt qua từng hàng trong bảng thứ nhất (outer table) và tìm các hàng khớp trong bảng thứ hai (inner table) thông qua một vòng lặp lồng nhau. Điều này được thực hiện bằng cách so sánh giá trị của cột kết hợp trong hai bảng. Hay nói cách khác, cách Join này sẽ sử dụng 2 vòng for và với độ phức tạp tính toán là O(M.N) với M và N là số hàng của 2 bảng.
Nguyên tắc hoạt động của Nested Loops Join như sau:
- Nested Loops Join dựa trên một vòng lặp lồng nhau. Bên ngoài vòng lặp là bảng gốc (outer table), còn bên trong vòng lặp là bảng kết hợp (inner table).
- Trong Nested Loops Join, mỗi hàng từ bảng gốc sẽ được duyệt tuần tự một lần. Với mỗi hàng này, hệ thống sẽ tìm kiếm các hàng trong bảng kết hợp mà thỏa mãn điều kiện kết hợp.
- Để thực hiện tìm kiếm, Nested Loops Join sử dụng chỉ mục hoặc quét toàn bộ bảng kết hợp. Nếu bảng kết hợp có chỉ mục tốt cho cột kết hợp, việc tìm kiếm sẽ được thực hiện nhanh chóng. Nếu không có chỉ mục, Nested Loops Join sẽ phải quét toàn bộ bảng kết hợp để tìm kiếm hàng phù hợp.
- Khi tìm thấy các hàng phù hợp, hệ thống sẽ ghép cặp hàng từ bảng gốc với các hàng kết hợp tương ứng và trả về kết quả truy vấn.
Ưu điểm: Nested Loops Join hiệu quả khi bảng inner table có kích thước nhỏ hoặc chỉ có một số lượng nhỏ các hàng khớp.
Nhược điểm: Khi một trong hai bảng có kích thước lớn, Nested Loops Join có thể trở nên chậm chạp vì phải duyệt qua nhiều hàng.
2. Hash Join
Đối với Join 2 bảng dữ liệu có kích thước lớn việc sử dụng Nested loops join sẽ gặp vấn đề khi độ phức tạp tính toán quá lớn O(M.N), dẫn đến tốn thời gian và chi phí. Hash Join là một phương pháp hiệu quả khi các bảng có kích thước lớn. Tại sao lại vậy?
Hash table là một cấu trúc dữ liệu lưu dữ liệu theo một cặp key - value, nó sử dụng một hàm Hash để tính toán vị trí lưu dữ liệu, nơi đó sẽ lưu một bucket để ta có thể tìm dữ liệu. Vì thế khi tìm kiếm trên Hash table ta chỉ mất độ phức tạp là O(1) trong trường hợp tốt nhất, vì chỉ cần chỉ ra Key, sẽ trả về cho ta Value.
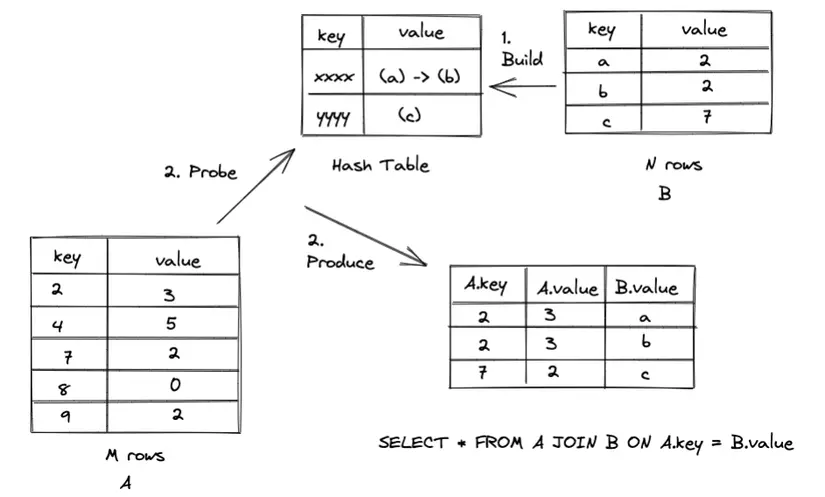
Hash Join thực hiện hai bước chính: xây dựng bảng băm (hash table) và thực hiện join.
- Trong bước xây dựng bảng băm, hệ thống sẽ lấy bảng có kích thước nhỏ hơn (bảng nhỏ) và tạo một bảng băm (hash table) từ cột kết hợp. Mỗi giá trị trong cột điều kiện kết hợp sẽ được đưa qua một hàm băm để tạo ra một giá trị băm duy nhất. Các giá trị băm này sẽ được lưu trữ trong bảng băm.
- Sau khi xây dựng bảng băm, hệ thống sẽ lấy bảng còn lại (bảng lớn) và thực hiện join với bảng băm. Đối với mỗi hàng trong bảng lớn, hệ thống sẽ áp dụng cùng một hàm băm vào cột kết hợp và so sánh giá trị băm với bảng băm. Những hàng có giá trị băm khớp nhau sẽ được ghép cặp và trả về kết quả join.
Rất đơn giản phải không nào. Độ phức tạp tính toán của thuật toán này sẽ là O(M+N), là nhanh hơn so với Nested Loops Join. Thay vì việc join với 1 bảng có kích thước lớn, nó chỉ viêc join với 1 hash table với kích thước nhỏ hơn và tìm kiếm trên bảng này là nhanh hơn.
Hash Join thường được sử dụng trong các trường hợp sau:
- Join giữa hai bảng lớn: Khi có hai bảng có kích thước lớn và được join với nhau, Hash Join có thể cung cấp hiệu suất tốt hơn so với các phương pháp join khác như Nested Loops Join hoặc Sort Merge Join.
- Join trên các cột không được chỉ định chỉ mục (non-indexed columns): Khi không có chỉ mục trên các cột được join, Hash Join có thể tận dụng bộ nhớ (memory) để xây dựng hash table nhanh chóng và thực hiện truy vấn nhanh hơn.
- Join inner join: Hash Join thường được sử dụng cho các loại join inner join, trong đó chỉ có các bản ghi khớp giữa hai bảng được trả về. Hash Join có thể tìm kiếm và so khớp các khóa join nhanh chóng trong hash table.
Nhược điểm:
- Yêu cầu bộ nhớ đáng kể: Phép join hash yêu cầu một lượng bộ nhớ đáng kể để xây dựng bảng băm (hash table). Nếu kích thước dữ liệu vượt quá khả năng của bộ nhớ, có thể xảy ra tràn bộ nhớ hoặc hiệu suất kém do việc sử dụng bộ nhớ ảo.
- Cần thời gian để xây dựng bảng băm: Trước khi thực hiện phép join, hash join cần xây dựng bảng băm từ một trong hai bảng. Quá trình này tốn thời gian và tài nguyên, đặc biệt là đối với các bảng có kích thước lớn.
- Không hiệu quả với các bảng nhỏ: Khi một trong hai bảng trong phép join là một bảng nhỏ, việc xây dựng bảng băm có thể là một lãng phí tài nguyên.
3. Sort Merge Join
Sort Merge Join là một phương pháp join trong SQL, trong đó các bảng đầu vào được sắp xếp theo một cột chung và sau đó được ghép nối (merge) lại với nhau dựa trên thứ tự sắp xếp đó. Quá trình này bao gồm hai giai đoạn: sắp xếp (sorting) và trộn dữ liệu (merging).
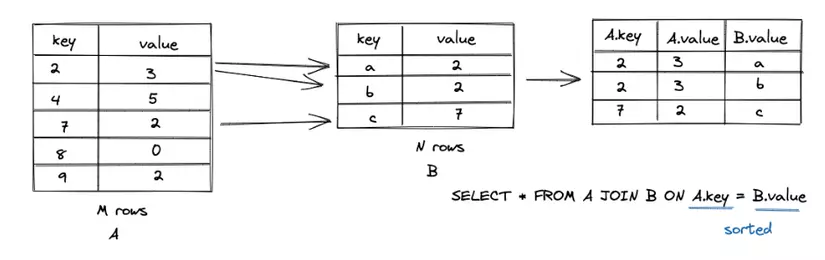
Quá trình Sort Merge Join được thực hiện theo các bước sau:
-
Sắp xếp dữ liệu: Đầu tiên, dữ liệu từ các bảng cần được sắp xếp dựa trên các cột được sử dụng để thực hiện phép join. Cả hai bảng đều được sắp xếp theo cùng một tiêu chí sắp xếp (tăng hoặc giảm) để đảm bảo tính đồng nhất.
-
Trộn dữ liệu: Tiếp theo, thuật toán sử dụng phép trộn (merge) để so sánh và tìm các cặp dữ liệu tương ứng trong hai bảng đã được sắp xếp. Thuật toán duyệt qua các bảng theo thứ tự sắp xếp và so sánh các giá trị trong cùng vị trí. Nếu giá trị trong cột join của hai bảng là tương đồng, nó được coi là một cặp dữ liệu tương ứng.
Độ phức tạp của phép Join Sort Merge Join phụ thuộc vào kích thước dữ liệu và độ phức tạp của quá trình sắp xếp.
- Quá trình sắp xếp: Độ phức tạp của việc sắp xếp dữ liệu trong Sort Merge Join là O(n log n), với n là số lượng bản ghi trong mỗi bảng. Do cần sắp xếp dữ liệu trước khi thực hiện phép join, thời gian sắp xếp có ảnh hưởng đáng kể đến độ phức tạp của thuật toán.
- Quá trình trộn dữ liệu: Quá trình trộn dữ liệu trong Sort Merge Join có độ phức tạp là O(M+N), với M+N là tổng số lượng bản ghi trong cả hai bảng. Trong quá trình trộn, thuật toán duyệt qua các bản ghi đã sắp xếp của cả hai bảng một lần và so sánh các giá trị trong cùng vị trí để tìm các cặp dữ liệu tương ứng.
Vì vậy độ phức tạp chung của phép Join này sẽ là O(M+N), cũng khá là nhanh.
Ưu điểm:
- Tính tổng quát: Xử lý các loại phép join phức tạp và đa dạng.
- Hiệu suất tốt với dữ liệu lớn, đặc biệt khi dữ liệu đã được sắp xếp.
- Độ phức tạp dễ dự đoán và điều chỉnh.
Nhược điểm:
- Yêu cầu bộ nhớ lớn để lưu trữ dữ liệu đã sắp xếp.
- Thời gian sắp xếp dữ liệu trước khi thực hiện join.
- Không hiệu quả với dữ liệu chưa sắp xếp hoặc có sự thay đổi thường xuyên.
4. Tổng kết lại
Việc hiểu được các cơ chế này sẽ rất có ích trong quá trình truy vấn. Việc lựa chọn cơ chế join phù hợp có thể giúp giảm thời gian thực thi truy vấn, tối ưu hóa tài nguyên hệ thống và cải thiện hiệu suất chung của cơ sở dữ liệu. Ta có thể dựa vào đặc điểm của các bảng dữ liệu như kích thước, tính chất và yêu cầu của truy vấn, ta có thể lựa chọn bảng, câu truy vấn phù hợp cơ chế join tối ưu nhất.
- Nested loop join: Thường được sử dụng cho các truy vấn với bảng dữ liệu nhỏ hoặc khi không có chỉ mục (index) phù hợp. Tuy nhiên, nó có độ phức tạp cao và yêu cầu nhiều tài nguyên. Việc sử dụng nested loop join có thể làm tăng thời gian thực thi truy vấn.
- Hash join: Thích hợp cho các truy vấn với dữ liệu lớn và bảng có chỉ mục phù hợp. Hash join sử dụng bảng băm (hash table) để nhanh chóng tìm kiếm và kết hợp các bản ghi tương ứng. Điều này giúp giảm thời gian thực thi truy vấn, đặc biệt khi có chỉ mục tương ứng.
- Sort merge join: Được sử dụng khi các bảng dữ liệu đã được sắp xếp hoặc cần được sắp xếp trước. Sort merge join kết hợp việc sắp xếp và trộn (merge) các bảng dữ liệu theo một tiêu chí chung. Nó hiệu quả với dữ liệu lớn và có thể giảm tải cho hệ thống. Tuy nhiên, nó yêu cầu bộ nhớ đủ lớn để thực hiện việc sắp xếp và trộn dữ liệu.
Trên đây là sự tìm hiểu của mình về cơ chế Join, mong nhận được ý kiến phản hồi. Bên dưới mình có để link tham khảo mọi người có thể đọc thêm để hiểu rõ. Cảm ơn mọi người đã đọc bài viết!
Reference
- Time Complexities of Table Joins (https://www.yuji.page/time-complexities-of-table-joins/)
- Visualizing Merge Join Internals And Understanding Their Implications (https://bertwagner.com/posts/visualizing-merge-join-internals-and-understanding-their-implications/?ref=yuji.page)
- Visualizing Nested Loops Joins And Understanding Their Implications (https://bertwagner.com/posts/visualizing-nested-loops-joins-and-understanding-their-implications/)
- Visualizing Hash Match Join Internals And Understanding Their Implications (https://bertwagner.com/posts/hash-match-join-internals/)
All rights reserved
