JavaScript engine: Shapes và Inline Caches
Bài đăng này đã không được cập nhật trong 7 năm
I. JavaScript engine pipeline
Mọi thứ bắt đầu với những dòng code JavaScript mà bạn viết. JavaScript engine sẽ phân giải mã nguồn và chuyển thành AST (Abstract Syntax Tree). Dựa vào AST, trình thông dịch có thể bắt đầu làm việc và sinh ra bytecode. Đó là lúc mà engine thực sự chạy JavaScript code.
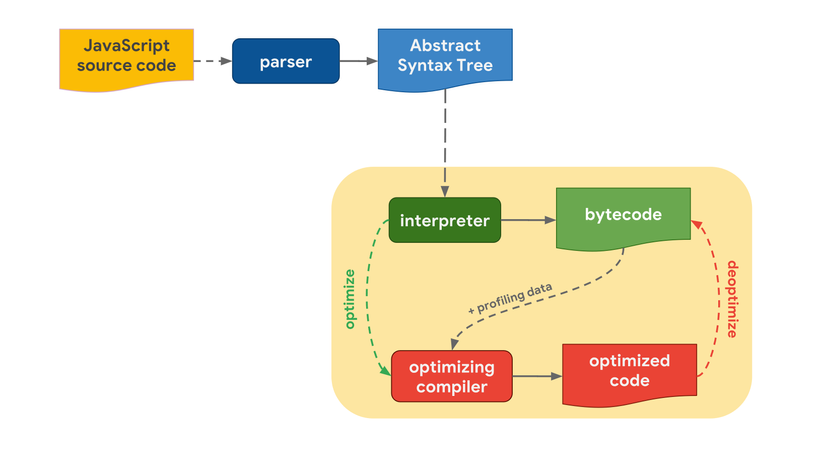
Để chương trình chạy nhanh hơn, bytecode có thể được gửi đến bộ biên dịch tối ưu cùng với dữ liệu đã được profiling. Bộ tối ưu này sẽ đặt ra những giả định dựa trên dữ liệu thu thập được và sinh ra mã máy đã được tối ưu ở mức độ cao nhất.
Nếu một trong các giả định này sai thì bộ biên dịch tối ưu sẽ hủy quá trình này và quay lại trình thông dịch.
Interpreter/compiler pipelines trong JavaScript engine
Giờ chúng ta sẽ xem một vài điểm khác nhau giữa các JavaScript engine phổ biến về cách chúng thông dịch và tối ưu code như thế nào.
Về cơ bản, có một pipeline chứa một trình thông dịch và một bộ biên dịch tối ưu. Trình thông dịch sinh nhanh các bytecode chưa tối ưu, và bộ biên dịch sẽ mất thời gian lâu hơn nhưng sẽ sinh ra mã máy (machine code) đã được tối ưu.
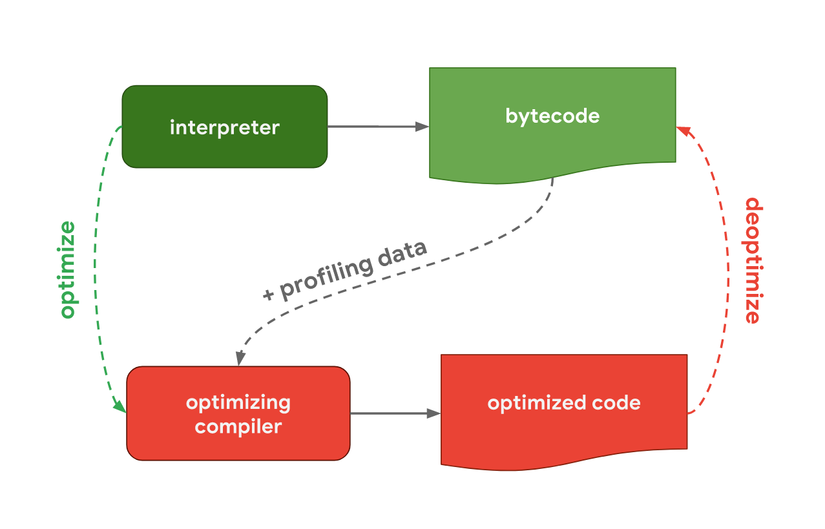
Pipeline này chính là cách hoạt động của V8 (JavaScript engine được dùng trong Chrome và Node.js):

Trình thông dịch trong V8 được gọi là Ignition, chịu trách nhiệm cho việc sinh và thực thi bytecode. Trong quá trình này thì nó cũng thu thập dữ liệu profiling dùng để tăng tốc cho việc thực thi code sau này. Khi một function hot, chẳng hạn như được dùng thường xuyên thì bytecode và dữ liệu profiling được truyền đến bộ biên dịch TurboFan và sinh ra mã máy tối ưu dựa theo dữ liệu thu thập được.
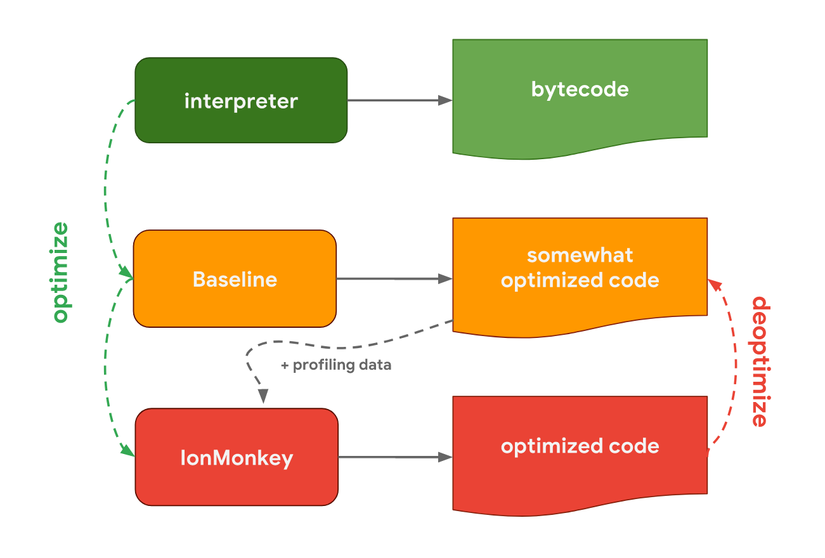
SpiderMonkey, JavaScript engine của Mozilla (từng được dùng trong Firefox và SpiderNode) thì làm hơi khác một chút. Chúng có tận 2 bộ biên dịch. Baseline sẽ sinh ra mã tối ưu một phần, kết hợp với dữ liệu profiling thì IonMonkey sẽ sinh ra mã cực kỳ tối ưu. Tuy nhiên nếu có lỗi thì IonMonkey sẽ trả về mã sinh bởi Baseline.
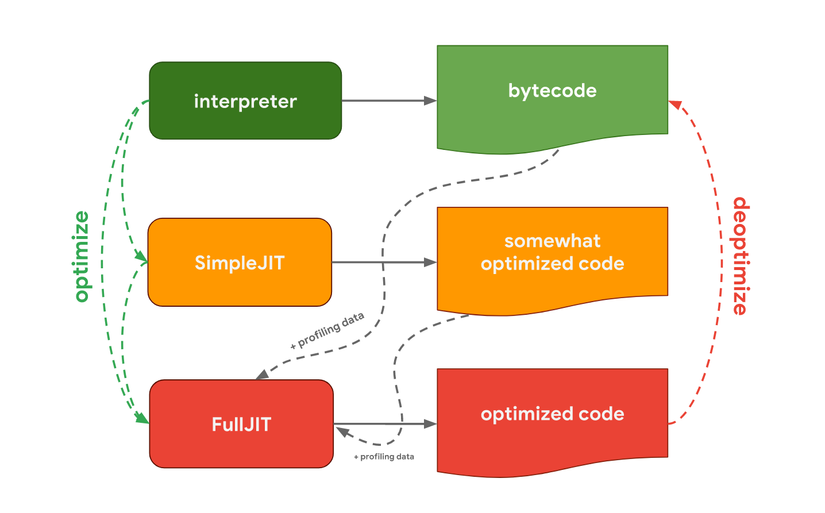
Chakra, JavaScript engine của Microsoft (được dùng ở Edge và Node-ChakraCore) có thiết lập tương tự với hai bộ biên dịch. SimpleJIT sinh mã tối ưu một phần, còn FullJIT sẽ sinh mã tối ưu toàn phần.
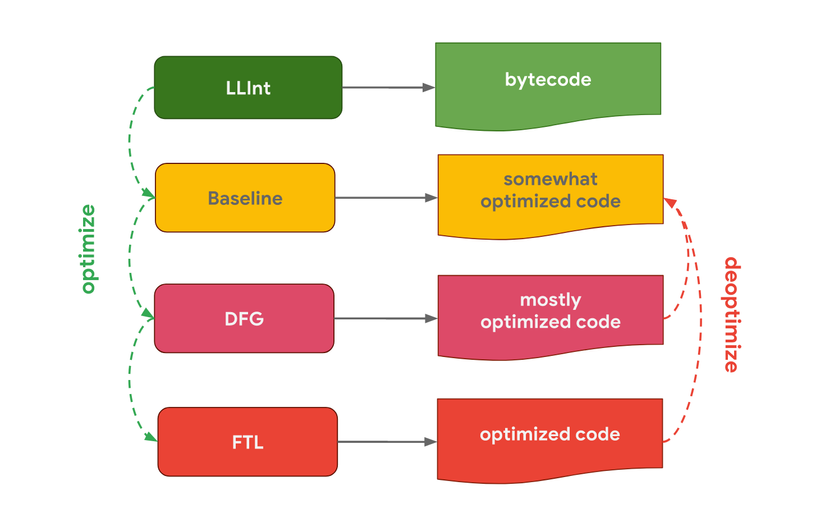
JavaScriptCore (JSC), JavaScript engine của Apple (được dùng trong Safari và React Native) thậm chí dùng đến 3 bộ biên dịch. Trình thông dịch LLInt sẽ sinh bytecode và truyền vào bộ biên dịch Baseline. Bộ biên dịch này sẽ tối ưu mã và gửi vào DFG (Data Flow Graph), rồi tiếp tục vào FTL (Faster Than Light).
Tại sao một số engine lại có nhiều bộ biên dịch hơn những engine khác? Thực ra là đều có đánh đổi cả. Trình thông dịch có thể sinh ra bytecode nhanh, nhưng bytecode lại thường không hiệu quả. Bộ biên dịch ngược lại sẽ mất nhiều thời gian hơn nhưng sẽ sinh ra mã máy tối ưu hơn. Rõ ràng hoặc là sinh code nhanh để chạy bằng trình thông dịch, hoặc là mất thêm thời gian nhưng sẽ có mã tối ưu nhờ bộ biên dịch. Một số engine còn sử dụng nhiều bộ biên dịch khác nhau để cho phép kiểm soát được tỷ lệ trade-off giữa thời gian và hiệu suất.
Chúng ta vừa điểm qua một số khác biệt cốt yếu về pipeline giữa các JavaScript engine. Nhưng bên cạnh những khác biệt này, thì ở mức độ cao hơn, mọi engine đều có cùng một kiến trúc: đó là một parser và một interpreter/compiler pipeline.
II. Mô hình đối tượng của JavaScript
Hãy khám phá cách cài đặt một số thành phần trong JavaScript engine để xem nó có gì.
Một ví dụ ở đây là cách JavaScript engine thiết lập mô hình đối tượng (JavaScript object model), và những thủ thuật nào giúp tăng tốc độ truy xuất thuộc tính của đối tượng? Như đã nói thì những engine phổ biến đều cài đặt chức năng này giống nhau.
Tài liệu ECMAScript có định nghĩa object như một từ điển, với key tương ứng với các đặc tính của thuộc tính.
(attribute và property có nghĩa tương đương trong tiếng Việt, trong bài viết tôi sẽ tạm để property là thuộc tính, còn attribute là đặc tính để phân biệt)
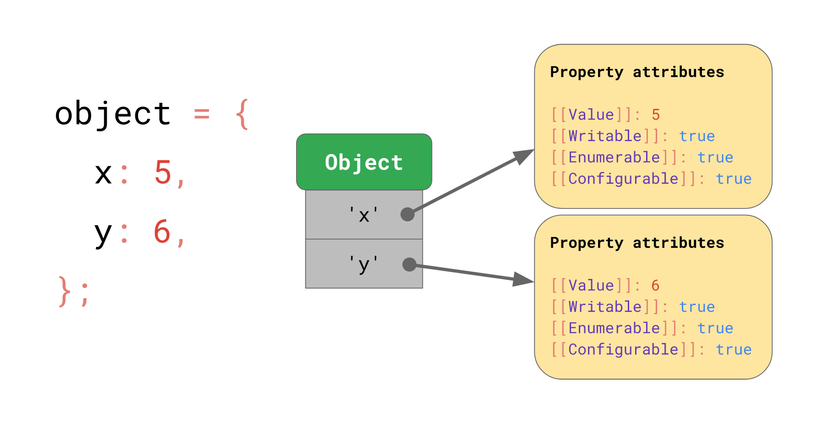
Ngoài bản thân [[Value]], tài liệu còn định nghĩa những đặc tính sau:
[[Writable]]nếu là false thì thuộc tính không thể thay đổi[[Enumerable]]nếu true, người dùng có thể lặp qua thuộc tính khi sử dụng for (var prop in obj){} (hoặc những phương pháp tương tự).[[Configurable]]nếu false, thì không thể xóa thuộc tính
Ký hiệu [[]] biểu diễn những thuộc tính mà không public. Nhưng bạn vẫn có thể lấy được những giá trị này bằng Object.getOwnPropertyDescriptor API:
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// → { value: 42, writable: true, enumerable: true, configurable: true }
Ok, đó là cách JavaScript định nghĩa object. Vậy còn array thì sao?
Bạn có thể nghĩ array là một trường hợp đặc biệt của object. Một điểm khác biệt là array có thể kiểm soát được chỉ mục của nó. Chỉ mục của array (index) là thuật ngữ đặc biệt trong tài liệu ECMAScript. Array giới hạn chỉ 2³²−1 item trong JavaScript. Chỉ mục của array là bất cứ chỉ mục hợp lệ mà nằm trong giới hạn vừa đề cập, ví dụ là bất kỳ số integer từ 0 đến 2³²−2.
Một khác biệt nữa là array cũng có thuộc tính length.
const array = ['a', 'b'];
array.length; // → 2
array[2] = 'c';
array.length; // → 3
Ở ví dụ này, array lúc khởi tạo có length là 2. Sau đó chúng ta gán một phần tử khác vào chỉ mục 9, và length tự động cập nhật.
JavaScript định nghĩa array tương tự như object. Chẳng hạn, tất cả key bao gồm chỉ mục đều được biểu diễn dưới dạng string. Phần tử đầu tiên trong array được chứa với key là '0'.

Thuộc tính length chỉ là một thuộc tính non-enumerable và non-configurable.
Khi phần tử mới được thêm vào array, JavaScript tự động cập nhật giá trị của [[Value]] của length.
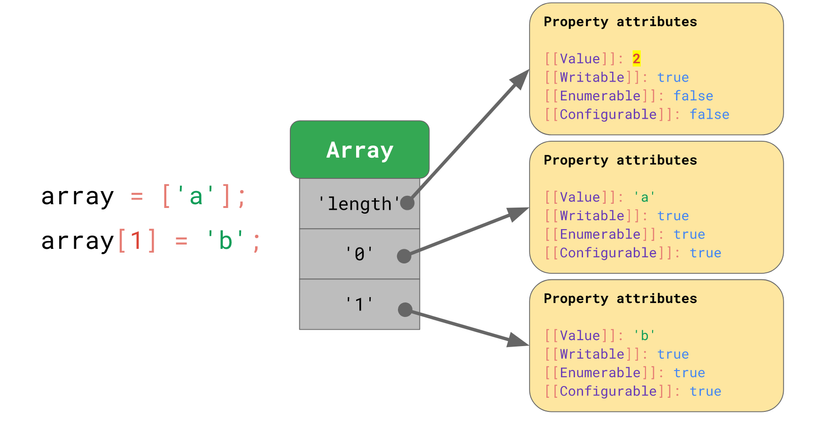
Nhìn chung array có hành vi tương tự như object.
III. Tối ưu truy cập thuộc tính
Bây giờ chúng ta biết được cách JavaScript định nghĩa object như thế nào, hãy tiếp tục tìm hiểu xem cách JavaScript engine làm việc với object.
Nhìn lại một chương trình JavaScript bất kỳ, thì truy cập thuộc tính là thao tác phổ biến nhất. Và đó là lý do để JavaScript engine tập trung tối ưu thao tác này.
const object = {
foo: 'bar',
baz: 'qux',
};
// Truy cập thuộc tính `foo` của `object`
doSomething(object.foo);
// ^^^^^^^^^^
Shapes
Trong chương trình JavaScript, thường thì sẽ có nhiều object có chung thuộc tính, những object như vậy có cùng shape.
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
// `object1` and `object2` have the same shape.
Và cũng có cách xử lý chung cho những trường hợp như vậy:
function logX(object) {
console.log(object.x);
// ^^^^^^^^
}
const object1 = { x: 1, y: 2 };
const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);
Chính vì vậy mà JavaScript engine tối ưu truy cập thuộc tính dựa trên shape của object. Đây chính là cách nó hoạt động.
Giả sử chúng ta có một object với thuộc tính x và y, và nó dùng cấu trúc dữ liệu kiểu từ điển mà chúng ta đã thảo luận ở trên: nó chứa key (là string), và những key này trỏ đến đặc tính tương ứng của thuộc tính.
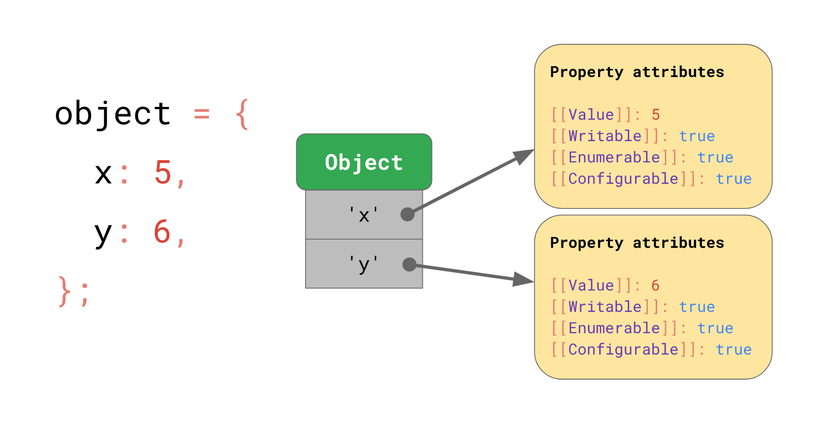
Nếu bạn truy cập một thuộc tính, ví dụ object.y, JavaScript engine sẽ tìm key y của object, sau đó nhận những đặc tính tương ứng của y, và cuối cùng trả về [[Value]].
Một câu hỏi đặt ra là những đặc tính này có được lưu vào bộ nhớ hay không? Và chúng ta có nên lưu chúng thành một phần của JSObject? Nếu giả sử chúng ta sẽ gặp nhiều object có cùng shape sau này, thì rõ ràng việc lưu thuộc tính và đặc tính vào JSObject là phí phạm, vì tên thuộc tính được lặp lại ở mọi object, và bộ nhớ khó mà chứa nổi. Để tối ưu thì engine lưu shape của từng object riêng biệt.
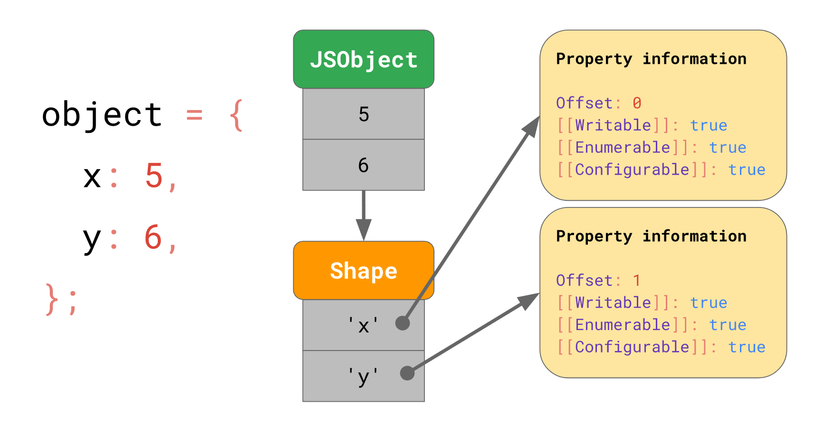
shape chứa tên thuộc tính cũng như tất cả các đặc tính, ngoại trừ [[Value]]. Thay vào đó nó chứa offset của giá trị nằm trong JSObject, nhờ đó mà engine sẽ biết tìm giá trị ở đâu. Mọi JSObject có cùng hình dạng sẽ cùng trỏ đến một shape, còn bản thân object chỉ cần lưu giá trị của thuộc tính là đủ.
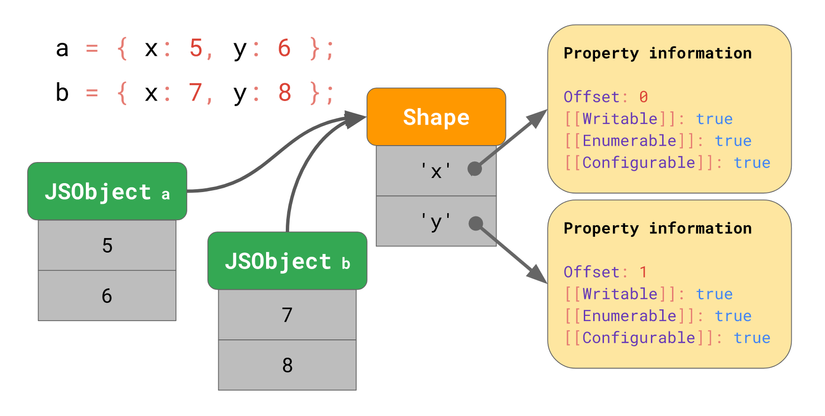
Lợi ích trở nên rõ ràng hơn khi có nhiều object. Không quan trọng có bao nhiêu object, miễn là chúng có cùng shape, chúng ta chỉ cần phải chứa shape cũng như thông tin của thuộc tính một lần!
Mọi JavaScript engine đều sử dụng shape như một cách để tối ưu, nhưng không phải engine nào cũng gọi chúng là shape:
- Tài liệu học thuật gọi chúng là Hidden Class (tuy nhiên lại dễ nhầm lẫn với JavaScript class)
- V8 gọi chúng là Maps (dễ nhầm với JavaScript Maps)
- Chakra gọi là Types
- JavaScriptCore gọi chúng là Structures
- SpiderMonkey gọi chúng là Shapes
Xuyên suốt bài viết này tôi sẽ để nguyên cách gọi là shape.
Transition chains và trees
Nếu bạn có object với một shape cụ thể, sau đó bạn thêm thuộc tính thì điều gì sẽ xảy ra? JavaScript engine sẽ tìm shape mới như thế nào?
const object = {};
object.x = 5;
object.y = 6;
Trong JavaScript engine điều này được gọi là transition chain. Ví dụ:
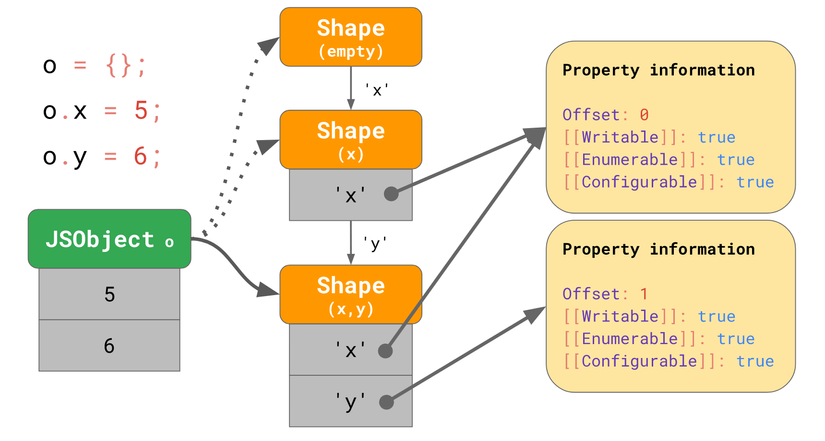
Ban đầu object không có thuộc tính, nên nó trỏ đến một shape rỗng. Câu lệnh kế tiếp thêm thuộc tính x với giá trị 5 đến object, nên JS engine chuyển đến một shape có chứa thuộc tính x và 5 sẽ được thêm vào JSObject với offset là 0. Tương tự thì khi thêm thuộc tính y, engine chuyển sang shape tiếp theo có chưa có x và y, đồng thời thêm 6 vào JSObject (offset là 1).
Lưu ý: thứ tự thuộc tính được thêm vào cũng ảnh hưởng đến shape, ví dụ { x: 4, y: 5 } sẽ tạo một shape khác với { y: 5, x: 4 }.
Thậm chí, thay vì lưu toàn bộ thuộc tính cho mỗi shape thì mỗi shape chỉ cần biết về thuộc tính mới. Chẳng hạn, trong trường hợp này chúng ta không cần lưu thông tin về x trong shape cuối cùng, vì nó có thể tìm được x bằng cách lần theo chuỗi, điều này là nhờ mỗi shape sẽ có một liên kết với shape trước nó:
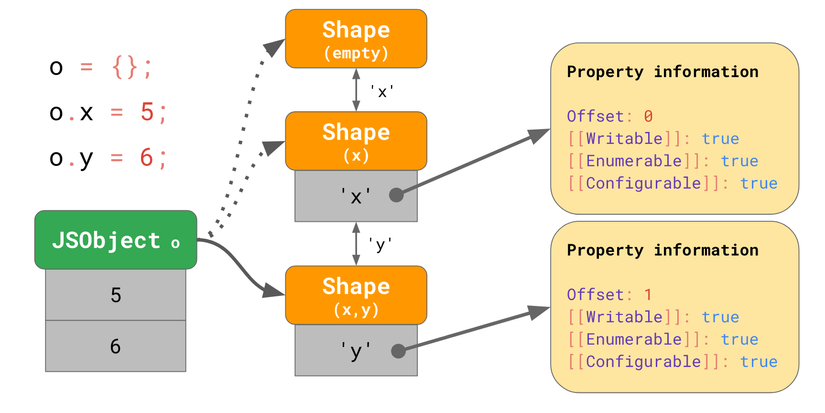
Nếu bạn viết o.x trong code, thì JS engine sẽ tìm thuộc tính x bằng cách lần theo transition chain cho đến khi nó tìm thấy.
Nhưng nếu không có cách nào để tạo transition chain thì sao? Chẳng hạn như nếu bạn có 2 object rỗng, và bạn thêm vào mỗi object một thuộc tính khác nhau.
const object1 = {};
object1.x = 5;
const object2 = {};
object2.y = 6;
Trong trường hợp này thay vì chuỗi thì ta phải phân nhánh, thành transition tree:
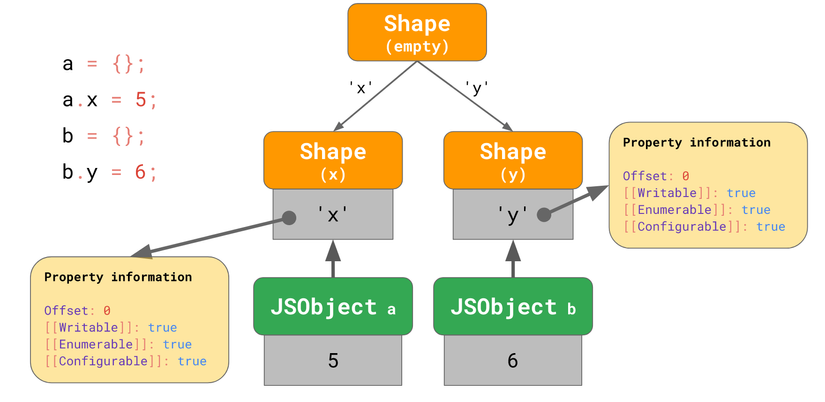
Ở đây, chúng ta tạo một object a rỗng, rồi thêm thuộc tính x. Lúc này thì ta sẽ có một JSObject chứa chỉ một giá trị, và 2 shape: một shape rỗng, và một shape với chỉ một thuộc tính x.
Ví dụ thứ 2 thì bắt đầu với object b rỗng, sau đó thêm thuộc tính y, kết quả là ta có 2 chuỗi shape, với tổng cộng là 3 shape.
Vậy có phải lúc nào cũng bắt đầu bằng một shape rỗng? Không cần thiết. Engine sẽ áp dụng một số biện pháp tối ưu cho object literal mà đã có thuộc tính. Chẳng hạn:
const object1 = {};
object1.x = 5;
const object2 = { x: 6 };
Ở ví dụ đầu, bắt đầu là một shape rỗng, và chuyển đến shape có x như đã nói.
Trong trường hợp object2, sẽ hay hơn là sinh ra object mà có thuộc tính x từ đầu thay vì bắt đầu bằng một object rỗng.

Object literal với thuộc tính x bắt đầu với Shape mà có x ngay từ đầu, đây là cách V8 và SpiderMonkey thực hiện.
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
Ở ví dụ trên, như đã thảo luận thì sẽ tạo một object với 3 Shape trong bộ nhớ (chưa kể Shape rỗng). Để truy cập thuộc tính x thì engine cần dựa theo danh sách liên kết, bắt đầu từ Shape dưới cùng và tìm ngược lên.
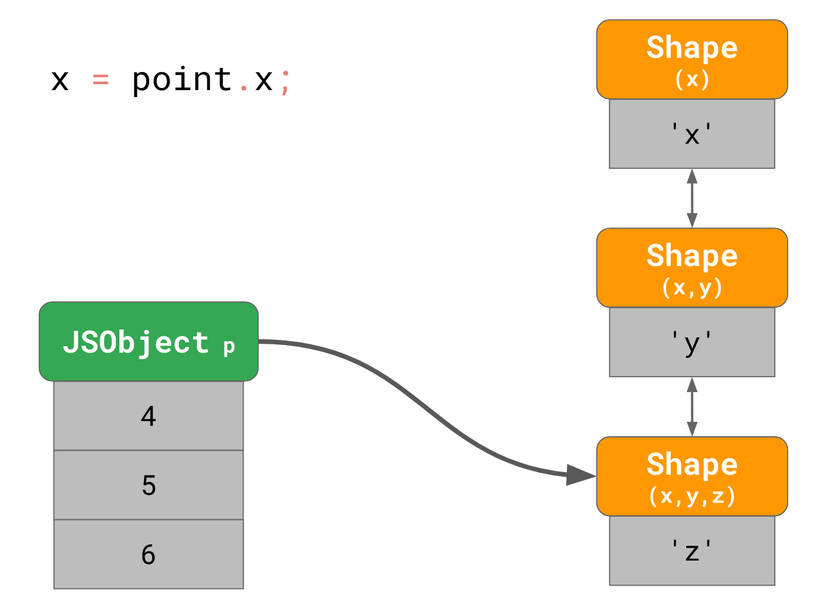
Nếu chúng ta thường xuyên làm việc này thì sẽ rất chậm, đặc biệt nếu object có nhiều thuộc tính. Thời gian để tìm thuộc tính là O(n). Để tăng tốc độ tìm kiếm, JS engine thêm một kiểu cấu trúc dữ liệu gọi là ShapeTable. ShapeTable là kiểu từ điển, nó ánh xạ thuộc tính với Shape tương ứng.
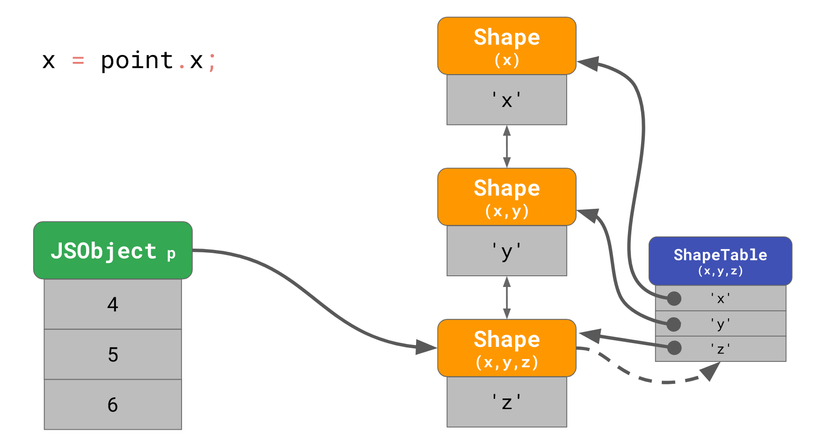
Ok, vậy là ta lại trở về với kiểu tìm kiếm bằng dictionary, vậy tại sao còn cần dùng Shape. Lý do là vì Shape hỗ trợ một kiểu tối ưu khác, gọi là Inline Cache.
Inline Caches (ICs)
Nguồn cảm hứng đằng sau shape chính là khái niệm Inline Caches hay ICs. ICs là nhân tố chính để giúp JavaScript chạy nhanh hơn! JS engine sử dụng ICs để lưu thông tin khi tìm thấy thuộc tính ở object, nhằm giảm số lần tìm kiếm.
Function getX sẽ nhận đầu vào là object và trả về thuộc tính x của nó:
function getX(o) {
return o.x;
}
Nếu ta chạy function này trong JSC, nó sẽ sinh ra bytecode như sau:
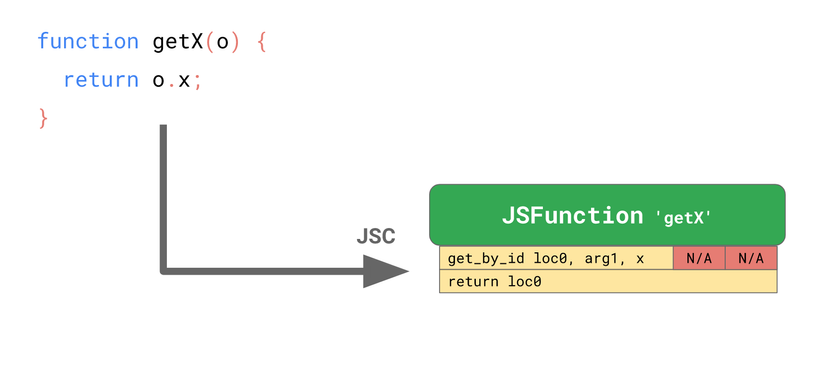
Chỉ thị get_by_id nhận thuộc tính x từ tham số đầu tiên (arg1) và lưu kết quả vào loc0. Chỉ thị thứ 2 trả về loc0.
JSC cũng nhúng Inline Cache vào chỉ thị get_by_id, trong đó có 2 slot chưa được khởi tạo.
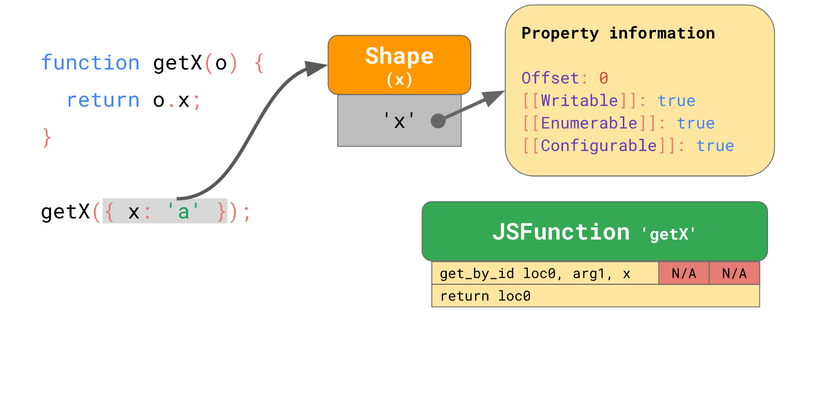
Giả sử ta gọi getX với object là {x: 'a'}. Như đã nói, object này có một shape chứa thuộc tính x mà chỉ lưu offset và đặc tính của thuộc tính x. Khi bạn thực thi function này lần đầu tiên, get_by_id sẽ tìm kiếm x và tìm thấy giá trị được lưu ở offset 0.
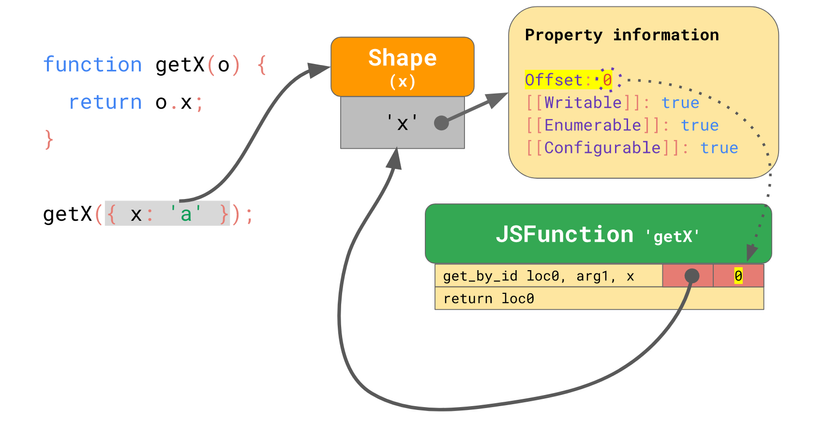
IC được nhúng trong get_by_id sẽ lưu lại shape cũng như offset:

Với các lần chạy hàm tiếp theo, IC chỉ cần so sánh shape, nếu trùng với cái đã có trước đó thì chỉ cần tải giá trị từ bộ nhớ. Cụ thể, nếu JS engine tìm thấy object với Shape mà IC đã ghi lại trước đó, nó sẽ không cần phải tìm thông tin về thuộc tính nữa, phần tìm kiếm đắt đỏ này sẽ bị bỏ qua hoàn toàn. Rõ ràng là sẽ nhanh hơn so với việc phải tìm kiếm thuộc tính lại mỗi lần chạy hàm.
IV. Storing arrays
Với array, thuộc tính được lưu lại thường chính là chỉ mục. Giá trị của thuộc tính chính là phần tử của mảng. Thay vì phí phạm bộ nhớ để lưu hết đặc tính (của thuộc tính) cho mỗi phần tử, JS engine lưu phần tử tách biệt với các thuộc tính khác.
Xem mảng sau:
const array = [
'#jsconfeu',
];
Engine lưu length (1), và trỏ đến Shape lưu offset và đặc tính của thuộc tính length.
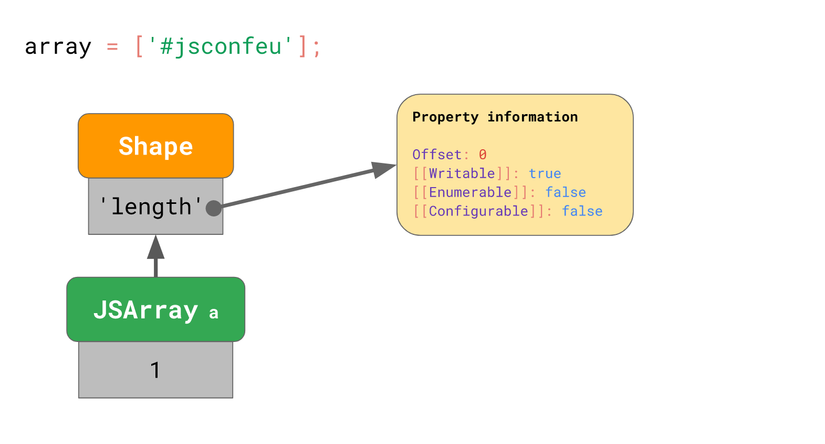
Trông có vẻ giống với những ví dụ khác ở trên, vậy còn giá trị của array được lưu ở đâu?
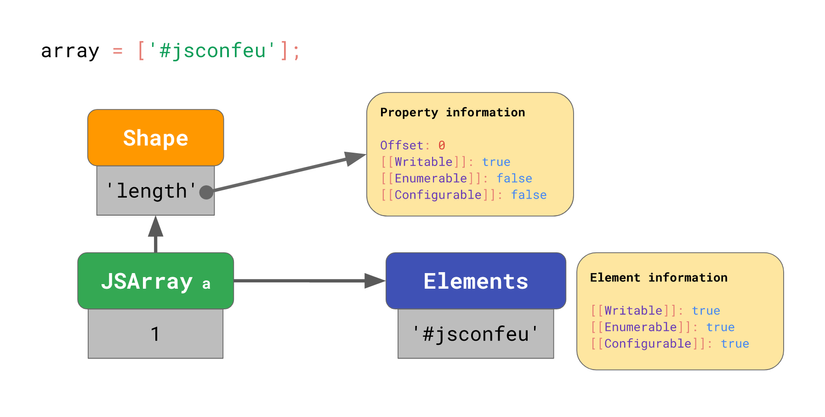
Mọi array đều có một kho độc lập để lưu trữ giá trị của các phần tử. Nếu bạn thay đổi đặc tính của thuộc tính của các phần tử mảng? (Như đã nói thì với array, chỉ mục chính là thuộc tính, nên thay đổi ở đây chính là thay đổi đặc tính của chỉ mục).
// Please don’t ever do this!
const array = Object.defineProperty(
[],
'0',
{
value: 'Oh noes!!1',
writable: false,
enumerable: false,
configurable: false,
}
);
Đoạn code trên định nghĩa một thuộc tính tên là '0', nhưng lại thiết lập đặc tính của nó là những giá trị không phải mặc định. Khi đó, JS engine biểu diễn toàn bộ kho lưu phần tử như một từ điển ánh xạ chỉ mục với đặc tính của nó.
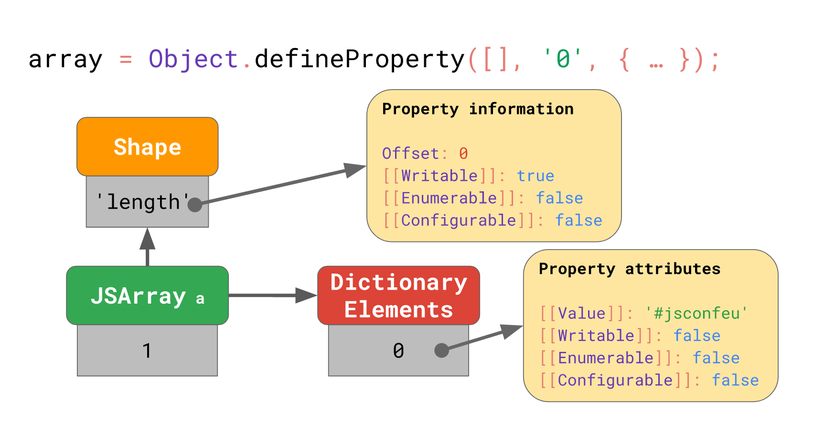
Thậm chí dù chỉ một phần tử có đặc tính khác với mặc định (non-default), thì toàn bộ kho lưu trữ phần tử cũng sẽ trở nên chậm và kém hiệu quả. Vậy nên khi code hãy tránh Object.defineProperty với chỉ mục của array.
V. Tổng kết
Chúng ta vừa tìm hiểu xong cách JavaScript engine lưu trữ object và array, cũng như cách Shape và ICs tối ưu những thao tác phổ biến. Dựa vào kiến thức này, chúng ta có thể đề ra được một số coding tip cải thiện performance như sau:
- Luôn khởi tạo object theo cùng một cách, lúc đó chúng sẽ luôn có cùng Shape
- Không chỉnh sửa đặc tính của chỉ mục, để chúng được lưu trữ và thao tác hiệu quả
All rights reserved
