Hướng dẫn tích hợp AI Agent với cơ sở dữ liệu ngoài (External Database)
Trong các hệ thống AI Agent hiện đại, dữ liệu hiếm khi nằm gọn trong một nơi duy nhất. Các thông tin ngữ cảnh (context) thường được lưu trữ dưới dạng vector để phục vụ tìm kiếm ngữ nghĩa, trong khi dữ liệu nghiệp vụ như khách hàng, đơn hàng, phản hồi lại được quản lý trong SQL hoặc NoSQL Database.
Vấn đề đặt ra là: làm sao để Agent vừa có khả năng hiểu ngữ nghĩa (semantic) vừa có thể truy xuất dữ liệu nghiệp vụ chính xác theo thời gian thực, chỉ trong một truy vấn duy nhất?
Bài viết này sẽ hướng dẫn chi tiết quy trình kết hợp AI Agent với cơ sở dữ liệu ngoài (External DB), giúp hệ thống của bạn vừa “hiểu” vừa “biết”, vừa khai thác insight ngữ nghĩa, vừa lấy được thông tin chính xác từ database truyền thống.
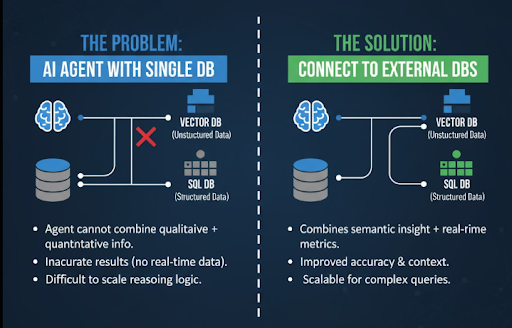
Vấn đề khi Agent chỉ truy cập một loại dữ liệu
Hầu hết các AI Agent được thiết kế chỉ kết nối với một loại cơ sở dữ liệu, điều này gây ra nhiều giới hạn trong thực tế:
- Vector DB (Chroma, Pinecone, FAISS): tốt cho việc hiểu ngữ nghĩa và tìm kiếm nội dung, nhưng không thể cung cấp dữ liệu định lượng hoặc thời gian thực.
- SQL DB (MySQL, PostgreSQL, MongoDB): lưu dữ liệu giao dịch, nhưng không hiểu ý nghĩa câu hỏi của người dùng.
Khi chỉ dựa vào một nguồn, Agent dễ gặp tình huống như:
- Không kết hợp được insight định tính (ý kiến, cảm xúc) với dữ liệu định lượng (số lượng, doanh thu).
- Câu trả lời thiếu độ chính xác vì không có dữ liệu thực tế.
- Khó mở rộng logic reasoning khi hệ thống phức tạp hơn.
Giải pháp: Hybrid RAG (Retrieval-Augmented Generation) – cho phép Agent truy cập song song hai nguồn dữ liệu: Vector DB để tìm ngữ cảnh và SQL DB để lấy dữ liệu chính xác.
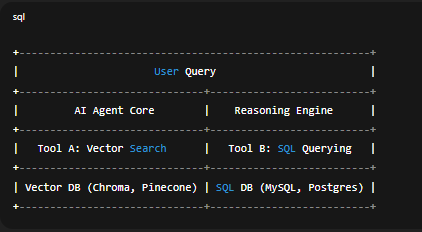
Kiến trúc tổng thể của hệ thống Hybrid Agent
Một mô hình kết hợp giữa Vector DB và SQL DB có thể chia thành 4 tầng:
- User Layer – Người dùng đặt câu hỏi tự nhiên.
- LLM Reasoning Layer – Phân tích intent và xác định loại dữ liệu cần truy vấn.
- Retrieval Layer – Gọi tới Vector DB để tìm context ngữ nghĩa.
- Query Layer – Sinh câu truy vấn SQL và lấy dữ liệu thực tế.
Luồng xử lý ví dụ:
“Những khách hàng nào phản hồi tích cực về sản phẩm BizChatAI trong tháng 9?”
- Vector DB → tìm các feedback chứa “BizChatAI” và “tích cực”.
- SQL DB → lấy danh sách khách hàng tương ứng và thông tin đơn hàng.
- Agent → tổng hợp và trả lời:
“Có 12 khách hàng, trong đó 5 khách hàng VIP phản hồi tích cực về BizChatAI.”
Chuẩn bị môi trường phát triển
Công nghệ đề xuất
| Thành phần | Gợi ý sử dụng |
|---|---|
| LLM | GPT-4o, Claude 3, Mistral 7B (self-host) |
| Vector DB | Chroma, Pinecone hoặc FAISS |
| SQL DB | MySQL / PostgreSQL |
| Framework | LangChain, LlamaIndex hoặc Semantic Kernel |
Chuẩn bị dữ liệu
- Tạo các bảng customers, feedback, orders trong SQL DB.
- Sinh embedding cho các trường dạng text (ví dụ: feedback_text, transcript).
- Lưu embedding vào vector DB, đồng thời lưu customer_id làm khóa liên kết (foreign key).
| feedback_id | customer_id | feedback_text | embedding_id |
|---|---|---|---|
| 001 | 1001 | “Chatbot phản hồi rất nhanh.” | e1 |
| 002 | 1002 | “Rất hài lòng với BizChatAI.” | e2 |
Tích hợp Agent với Vector DB và SQL DB
Bước 1. Kết nối Vector DB
from langchain.vectorstores import Chroma
vector_db = Chroma(persist_directory="data/vectorstore")
Bước 2. Kết nối SQL DB
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://user:password@localhost:3306/agents_db")
Bước 3. Định nghĩa Tool cho Agent
from langchain.tools import Tool
tools = [
Tool(
name="VectorSearch",
func=lambda q: vector_db.similarity_search(q, k=5),
description="Truy vấn ngữ nghĩa từ vector DB."
),
Tool(
name="SQLQuery",
func=lambda q: engine.execute(q).fetchall(),
description="Truy vấn dữ liệu có cấu trúc từ SQL DB."
)
]
Bước 4. Khởi tạo Agent reasoning
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
agent = initialize_agent(
tools=tools,
llm=ChatOpenAI(model="gpt-4o"),
agent_type="zero-shot-react-description",
verbose=True
)
Bước 5. Gọi truy vấn thông minh
query = "Liệt kê top 5 khách hàng phản hồi tích cực về BizChatAI tháng 9."
agent.run(query)
Kết quả Agent sẽ tự động:
- Gọi
VectorSearchđể tìm các đoạn văn bản phù hợp. - Sinh câu SQL tương ứng.
- Kết hợp kết quả từ hai nguồn và trả lời bằng ngôn ngữ tự nhiên.
Tối ưu hiệu năng và bảo mật
| Mục tiêu | Giải pháp |
|---|---|
| Tốc độ truy vấn | Giới hạn số kết quả vector (k ≤ 5), tránh overload LLM |
| Bảo mật dữ liệu | Dùng ORM (SQLAlchemy) hoặc query template có validation |
| Độ chính xác | Gán confidence_score cho vector result để loại nhiễu |
| Khả năng mở rộng | Tích hợp message queue (Kafka, Redis Streams) cho truy vấn song song |
| Tối ưu phản hồi | Cache kết quả bằng Redis hoặc DuckDB |
Kinh nghiệm triển khai thực tế
- Schema-Aware Prompting: mô tả rõ cấu trúc bảng SQL trong system prompt, ví dụ: "
Database có bảng customers(name, email, segment), feedback(customer_id, content, date)." - Tách logic RAG & Reasoning: giữ phần retrieval độc lập để kiểm soát tốt hơn pipeline.
- Audit truy vấn: log toàn bộ câu SQL mà Agent sinh ra để kiểm tra lỗi hoặc hành vi bất thường.
- Benchmark định kỳ: so sánh câu trả lời với dữ liệu thật để tinh chỉnh prompt và weight vector.
Kết luận
Sự kết hợp giữa Vector Database và External Database (SQL/NoSQL) giúp AI Agent trở nên “hai chiều”:
- Vừa hiểu được ngữ cảnh và ý nghĩa câu hỏi,
- Vừa truy xuất dữ liệu chính xác, cập nhật theo thời gian thực.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-ket-hop-ai-agent-voi-co-so-du-lieu-ngoai-external-db.html
Đây là nền tảng quan trọng để phát triển các hệ thống AI tác vụ (Task-Oriented Agent) có khả năng tự học, tự suy luận và đưa ra hành động thực tế trong môi trường doanh nghiệp.
All rights reserved
