Hướng dẫn thiết kế hệ thống (Phần 3) - Thiết kế hệ thống Twitter timeline và search
Bài đăng này đã không được cập nhật trong 4 năm
Lời mở đầu
TIếp theo phần 2, trong phần này mình sẽ giới thiệu với các bạn về thiết kế phần trong một dịch vụ khả phổ biến hiện nay đó là mạng xã hội trực tuyến. Trong bài viết này mình chỉ mình đến module timeline và search. Một điều quan trọng nữa các bạn sẽ thấy đó là các step giống hệt nhau, điều đó có nghĩa với bất kỳ hệ thống nào nữa thì cách tiếp cận vấn đề là không thay đổi.
Step 1 : Phác thảo ra các use case và những ràng buộc
Thu thập các yêu cầu và phạm vi vấn đề. Đặt ra các câu hỏi để làm rõ các trường hợp sử dụng và các ràng buộc. Thảo luận về những giả định. Nếu không có ai để giải đáp các câu hỏi, người đưa ra giải đáp ở đây là người đưa ra những yêu cầu cho bạn (VD: khách hàng, project owner). Vậy thì chúng ta sẽ phải tự xác định một số trường hợp sử dụng và khó khăn.
Các use case
- Người dùng đăng bài tweet
- Dịch vụ đẩy tweet đến người theo dõi, gửi thông báo đẩy và email
- Người dùng xem timeline của họ (hoạt động của người dùng)
- Người dùng xem home timeline (hoạt động của mọi người khác mà người dùng đang follow)
- Tìm kiếm theo keyword
- Dịch vụ có tính sẵn sàng cao
Out of scope
- Push tweet vào Twitter Firehose hoặc các stream khác
- Ẩn @reply nếu user không follow người nhận trả lời
- Cài đặt các nội dung ẩn
- Hệ thống phân tích
Hạn chế và giả định
Hạn chế chung
-
Traffic không phân bố đều
-
Tốc độ gửi bài nhanh
- Tất cả những người follow bạn đều gửi được bài nhanh chóng, ngoại trừ trường hợp bạn có tới hàng triệu người follow
-
100 triệu người dùng
-
500 million tweets per day or 15 billion tweets per month
-
250 tỷ yêu cầu đọc mỗi tháng
-
10 tỷ lượt tìm kiếm mỗi tháng
Timeline
-
View timeline phải nhanh
-
Tweeter sẽ đọc nhiều hơn viết nhiều
- Tối ưu hoá để đọc nhanh cái tweet
Search
- Tìm kiếm phải nhanh
- Tiến trình search với khối lượng lớn dữ liệu sẽ phải xử lý khá nặng
Tính toán sử dụng
**Kích thước mỗi tweet: **
- tweet_id - 8 byte
- user_id - 32 byte
- văn bản - 140 byte
- media - 10 KB trung bình
- Tổng cộng: ~ 10 KB
150 TB nội dung mới mỗi tháng tweet
-
10 KB cho mỗi tweet * 500 triệu tweet mỗi ngày * 30 ngày mỗi tháng
-
5.4 PB nội dung tweet mới trong 3 năm
-
100 nghìn yêu cầu đọc mỗi giây
- Đọc 250 tỷ yêu cầu mỗi tháng * (400 yêu cầu mỗi giây / một tỷ yêu cầu mỗi tháng)
-
6.000 tweet mỗi giây
- 15 tỷ tweets được gửi mỗi tháng * (400 yêu cầu mỗi giây / một tỷ yêu cầu mỗi tháng)
-
60 nghìn lượt tweet được gửi trên mỗi giây
- 150 tỷ tweets được phân phối trên fanout mỗi tháng * (400 yêu cầu mỗi giây / 1 tỷ yêu cầu mỗi tháng)
-
4.000 yêu cầu tìm kiếm mỗi giây
Công thức tính nhanh
- 2,5 triệu giây mỗi tháng
- 1 yêu cầu / giây = 2,5 triệu yêu cầu mỗi tháng
- 40 yêu cầu mỗi giây = 100 triệu yêu cầu mỗi tháng
- 400 yêu cầu mỗi giây = 1 tỷ yêu cầu mỗi tháng
Step 2 : Thiết kế high level
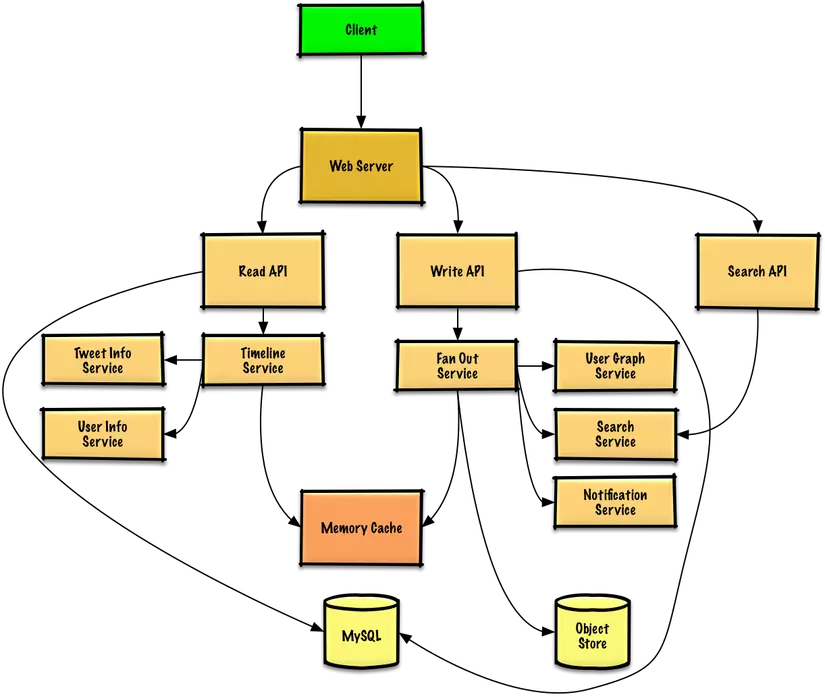
Step 3 : Thiết các thành phần lõi
Use case: Người dùng đăng bài tweet
Chúng ta có thể lưu trữ các tweets của người dùng để điền vào timeline người dùng (hoạt động từ người dùng) trong một cơ sở dữ liệu quan hệ. Chúng ta nên thảo luận về các trường hợp sử dụng và so sánh giữa việc chọn SQL hoặc NoSQL.
Chuyển các tweet và xây dựng đường mục home timeline (hoạt động từ những người mà người dùng đang theo dõi) là một thứ phức tạp hơn. Các thảo luận tweet dành cho tất cả những người theo dõi (60 nghìn tweet được thảo luận mỗi giây) sẽ làm quá tải cơ sở dữ liệu quan hệ truyền thống. Thế nên có lẽ chúng ta sẽchọn một nơi lưu trữ dữ liệu với tốc độ ghi nhanh như cơ sở dữ liệu NoSQL hoặc bộ nhớ Cache. Đọc 1 MB liên tục từ bộ nhớ mất khoảng 250 microsecond, trong khi đọc từ SSD lâu hơn mất 4 lần và từ HDD mất 80 lần.
Chúng ta có thể lưu trữ các file media như ảnh hoặc video trên storage.
- Client đăng bài tweet lên Web Server, chạy dưới dạng reverse proxy .
- Máy chủ Web chuyển tiếp yêu cầu tới máy chủ Write API
- Write API lưu trữ tweet trong timeline của người dùng trên cơ sở dữ liệu SQL
- Write API giao tiếp với Dịch vụ Fan Out (dịch vụ thảo luận), thực hiện những việc sau:
- Truy vấn User Graph service để tìm follower được lưu trữ trong Bộ nhớ Cache
- Lưu trữ tweet follower của người dùng trong home timeline trên bộ nhớ Cache
- Quá trình làlà O(n): 1.000 người theo dõi = 1.000 tra cứu và chèn
- Lưu trữ tweet trong Search Index Service để cho phép tìm kiếm nhanh
- Lưu trữ media trong Object Store
- Sử dụng Dịch vụ Notification để gửi thông báo đẩy tới follower:
- Sử dụng hàng đợi để gửi các thông báo
Làm rõ với quản lý dự án bao nhiêu dữ liệu cần được ghi :
Nếu Memory Cache của chúng ta là Redis thì chúng ta có thể sử dụng một danh sách công thức Redis với cấu trúc sau:
tweet n+2 tweet n+1 tweet n
| 8 bytes 8 bytes 1 byte | 8 bytes 8 bytes 1 byte | 8 bytes 7 bytes 1 byte |
| tweet_id user_id meta | tweet_id user_id meta | tweet_id user_id meta |
Các tweet mới sẽ được đặt trong bộ nhớ Cache, lưu trữ home timeline của người dùng (hoạt động từ những người mà người dùng đang theo dõi).
Use case: Người dùng xem timeline của họ
- Client post lên home timeline -> yêu cầu được gửi về web server
- Máy chủ Web chuyển tiếp yêu cầu đến máy chủ Read API
- Máy chủ API đọc kết nối với dịch vụ Timeline, trong đó làm như sau:
- Lấy dữ liệu thời gian được lưu trữ trong bộ nhớ Cache, có chứa tweet ID và ID người dùng
- Truy vấn Tweet Info Service để có được thông tin bổ sung về tweet ID
- Truy vấn User Info Service để có thêm thông tin về ID người dùng
Use case: Người dùng xem home timeline
- Khách hàng gửi home timeline request cho các máy chủ Web
- Máy chủ Web chuyển tiếp yêu cầu đến máy chủ Read API
- Read API lấy home timeline của người dùng từ cơ sở dữ liệu SQL
Use case: Tìm kiếm theo keyword
- Client gửi một yêu cầu tìm kiếm đến Web Server
- Máy chủ Web chuyển tiếp yêu cầu tới máy chủ Search API
- Search API liên hệ với Dịch vụ Tìm kiếm, thực hiện như sau:
- Phân tích/token input query, xác định những gì cần phải được tìm kiếm
- Loại bỏ đánh dấu
- Chia nhỏ văn bản thành các thuật ngữ
- Sửa lỗi chính tả
- Viết thường các ký tự viết hoa
- Convert truy vấn để sử dụng các phép toán boolean
- Truy vấn tìm kiếm cho kết quả:
- Phân tán máy chủ trong cluster để xác định xem có kết quả nào cho truy vấn
- Merges, xếp hạng, sắp xếp và trả về kết quả
- Phân tích/token input query, xác định những gì cần phải được tìm kiếm
Step 4: Scale thiết kế của bạn
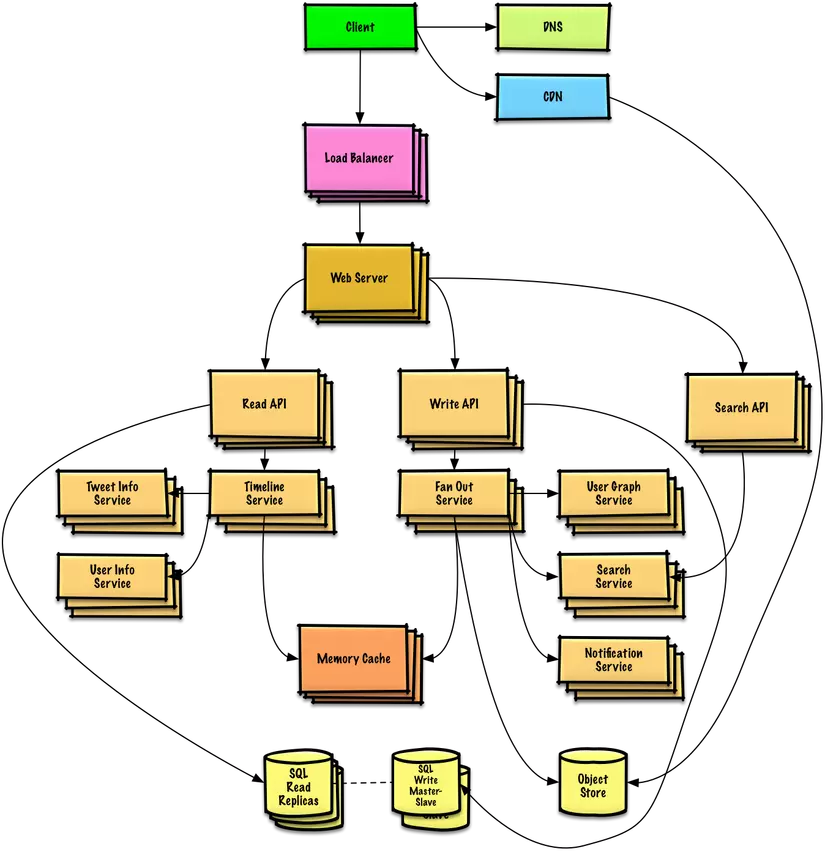
Và đương nhiên là những công việc mà bạn sẽ phải làm đi làm lại nhiều lần :
- Benchmark/Load Test
- Có được thông tin nghẽn cổ chai
- Có được phương án xử lý các trường hợp nghẽn cổ chai
- Làm lại các bước trên
- Điều quan trọng là bạn phải trao đổi thảo luận về những nút thắt cổ chai bạn có thể gặp phải với thiết kế ban đầu và cách bạn có thể giải quyết từng vấn đề. Ví dụ, những vấn đề nào được giải quyết bằng cách thêm một Load Balancer với nhiều server Web? CDN? Master-Slave Replication . Các lựa chọn thay thế cho mỗi trường hợp là gì ?
Kết luận
Trên đây là những gì mà tôi đã dành thời gian để nghiên cứu, tìm kiếm cấu trúc hệ thống. Những con số ở bài viết chỉ là những con số chủ quan do người viết bài tự ước lượng để có được con số chính xác bắt buộc các bạn phải có cách/biện pháp đo lương 1 cách thường xuyên. Con số này càng chính xác bao nhiêu thì bạn càng hạn chế được rủi ro bấy nhiêu. Xin hẹn các bạn ở phần sau của chuỗi bài viết này. Mọi góp ý xin liên hệ tới :
Skype : ltminh258 Chatwork : le.tuan.minh Email : ltminh88@gmail.com
All rights reserved
