Hướng dẫn kết hợp nhiều nguồn context trong một truy vấn AI
Trong thực tế triển khai các hệ thống AI Agent, đặc biệt là RAG (Retrieval-Augmented Generation) hay multi-agent pipeline, việc chỉ dựa vào một nguồn dữ liệu duy nhất là không đủ. Người dùng thường đặt các câu hỏi yêu cầu tổng hợp từ nhiều kho tri thức khác nhau, ví dụ: cơ sở dữ liệu sản phẩm, hồ sơ khách hàng, và tài liệu kỹ thuật nội bộ.
Để xử lý chính xác, hệ thống cần một Router thông minh đóng vai trò điều phối (dispatcher), giúp LLM xác định nguồn context phù hợp cho từng phần truy vấn thay vì “đổ” tất cả dữ liệu vào prompt vốn dễ gây token overload và context nhiễu. Bài viết này sẽ hướng dẫn chi tiết cách triển khai cơ chế multi-context routing trong pipeline AI thực tế.
Bài toán thực tế: Multi-Context Query
Trong môi trường production, dữ liệu của doanh nghiệp phân tán ở nhiều hệ thống khác nhau:
- CRM: lưu thông tin và lịch sử giao dịch khách hàng.
- CDP: ghi nhận hành vi, phân khúc và thuộc tính người dùng.
- Product DB: quản lý sản phẩm, giá, tồn kho.
- Knowledge Base: tài liệu hướng dẫn (Notion, Confluence, Google Drive…).
- Vector DB: chứa tài liệu embedding phục vụ semantic search.
Ví dụ truy vấn:
“Hãy báo giá sản phẩm X và kiểm tra xem tài khoản của tôi có ưu đãi không.”
→ Hệ thống cần truy xuất đồng thời từ Product DB (giá sản phẩm) và CRM/CDP (thông tin ưu đãi). Nếu không có cơ chế routing, việc nhồi tất cả dữ liệu vào context sẽ khiến chi phí token cao, latency lớn và mô hình dễ trả lời sai.
Router Architecture – Dispatcher trong AI Pipeline
Router là thành phần trung gian định tuyến truy vấn đến các nguồn dữ liệu phù hợp.
Một pipeline cơ bản gồm 6 giai đoạn:
1. Nhận truy vấn – Backend nhận câu hỏi người dùng → gửi sang Router.
2. Phân tích intent – Sử dụng LLM classifier hoặc NLU model để trích xuất intent, entity.
Ví dụ: “Báo giá sản phẩm A cho 100 người dùng” → intent = request_quote, entity = {product: A, quantity: 100}.
3. Xác định nguồn dữ liệu
- Rule-based: cấu hình YAML/JSON map intent → nguồn.
- AI-based: để LLM chọn nguồn dựa trên schema mô tả (như function-calling).
4. Truy vấn dữ liệu
- CRM → REST/GraphQL API.
- Vector DB → similarity search.
- Product DB → SQL query.
5. Hợp nhất context
- Chuẩn hóa về JSON thống nhất.
- Áp dụng chiến lược merge (top-k, weighting, priority…).
6. Sinh prompt: Render context vào prompt template → gửi sang LLM để sinh kết quả.
Router Rule-Based (Config-Driven Approach)
Triển khai đơn giản nhất là rule-based routing.
Ví dụ file routes.yaml:
routes:
- intent: request_quote
sources: [product_db, crm]
- intent: check_feature
sources: [knowledge_base]
- intent: customer_profile
sources: [crm, cdp]
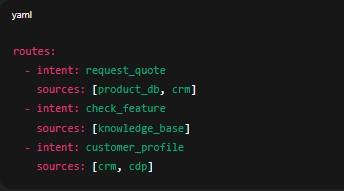
Router load cấu hình này, map intent → danh sách nguồn dữ liệu → thực thi truy vấn.
Ưu điểm: dễ kiểm soát, dễ debug.
Nhược điểm: kém linh hoạt khi intent phức tạp hoặc chưa có rule tương ứng.
Router AI-Based (Function-Calling / Tool-Selection)
Để hệ thống tự động hơn, bạn có thể mô hình hóa từng nguồn context như một “tool” hoặc “function” cho LLM lựa chọn:
[
{
"name": "search_product_db",
"description": "Truy vấn thông tin sản phẩm theo tên hoặc ID",
"parameters": { "product_name": "string" }
},
{
"name": "get_customer_profile",
"description": "Lấy hồ sơ khách hàng từ CRM",
"parameters": { "customer_email": "string" }
}
]
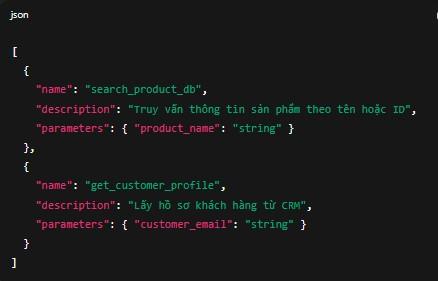
Khi người dùng gửi query, LLM sẽ chọn function cần gọi → Router parse function_call → trigger API tương ứng.
Ưu điểm: linh hoạt, dễ mở rộng.
Nhược điểm: cần xử lý lỗi khi LLM gọi nhầm hoặc thiếu tham số.
Chiến lược Hợp nhất Context (Context Merging Strategy)
Khi dữ liệu trả về từ nhiều nguồn, cần có chiến lược hợp nhất hợp lý:
| Chiến lược | Mô tả | Rủi ro |
|---|---|---|
| Concat Raw Text | Gộp text từ tất cả nguồn | Dễ bloat token, mất trọng tâm |
| Structured JSON Merge | Chuẩn hóa schema rồi render vào prompt | Cần định nghĩa schema rõ |
| Weighted Ranking | Sắp xếp theo score (vector similarity) | Phụ thuộc vào độ chính xác scoring |
| Hierarchical Merge | Ưu tiên thứ tự nguồn (CRM > DB > KB) | Phức tạp khi conflict dữ liệu |
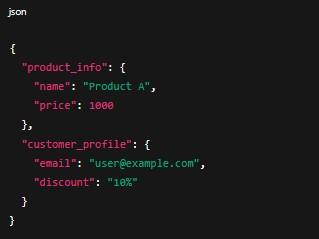
Ví dụ payload hợp nhất:
{
"product_info": {
"name": "Product A",
"price": 1000
},
"customer_profile": {
"email": "user@example.com",
"discount": "10%"
}
}
Xử lý Bất đồng bộ (Async & Fan-Out)
Một số API (như CRM hoặc Search KB) có latency cao.
Router nên thiết kế theo hướng asynchronous fan-out:
- Gửi song song truy vấn đến nhiều nguồn.
- Sử dụng
Promise.all()(Node.js) hoặcasyncio.gather()(Python). - Có cơ chế timeout fallback nếu một nguồn không phản hồi.
Điều này đảm bảo hệ thống ổn định và phản hồi nhanh, không bị treo do một service chậm.
Kết luận
Khi truy vấn AI cần tổng hợp từ nhiều nguồn dữ liệu, Router là trái tim của hệ thống. Một kiến trúc routing tốt giúp:
- Giảm chi phí token.
- Tăng tốc độ phản hồi.
- Giữ logic dữ liệu rõ ràng, có thể mở rộng.
Với cách tiếp cận module hóa – từ rule-based đến function-calling developer hoàn toàn có thể xây dựng một Context Router thông minh, tối ưu cho các ứng dụng AI có độ phức tạp cao như RAG, Chat Agent, hay Assistant doanh nghiệp.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-ket-hop-nhieu-nguon-context-trong-mot-truy-van-cho-ai.html
All rights reserved
