Hướng dẫn dùng Cross-Encoder để lọc nhiễu trong quá trình xây dựng context cho RAG
Khi triển khai hệ thống Retrieval-Augmented Generation (RAG) hoặc bất kỳ pipeline nào cần tạo context đầu vào cho mô hình ngôn ngữ lớn, bạn sẽ sớm nhận ra một vấn đề quen thuộc:
Các đoạn text lấy ra từ vector store nghe thì “na ná”, nhưng nhiều đoạn lại không thực sự liên quan đến truy vấn người dùng. Đó chính là nhiễu ngữ nghĩa (semantic noise), nguyên nhân khiến context trở nên dài, tốn token và làm giảm độ chính xác đầu ra.
Bài viết này hướng dẫn cách sử dụng Cross-Encoder như một bộ lọc tinh giúp loại bỏ nhiễu, giữ lại những đoạn thực sự phù hợp với câu hỏi của người dùng.
Vì sao cần lọc nhiễu trong quá trình xây context
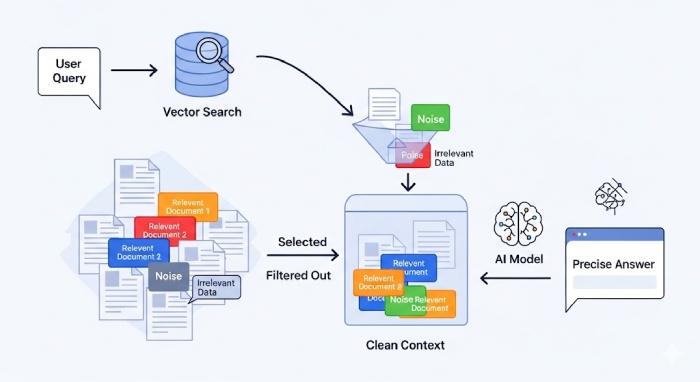
Trong một quy trình RAG tiêu chuẩn, dòng dữ liệu thường đi theo hướng sau:
User Query → Embedding → Vector Search → Retrieve Top-k → Build Context → Generate Answer
Tuy nhiên, vector search (dùng Bi-Encoder hoặc embedding model) chỉ đánh giá độ gần trong không gian vector, chứ không hiểu ngữ nghĩa sâu của truy vấn. Kết quả là, bạn có thể nhận được các đoạn text gần nghĩa về mặt từ vựng nhưng không trả lời trực tiếp cho câu hỏi.
Điều này dẫn đến nhiều vấn đề:
- Context phình to, dễ vượt quá giới hạn token.
- Mô hình LLM nhận thông tin “nhiễu”, trả lời lạc đề hoặc mất mạch.
- Chi phí xử lý tăng do context chứa nhiều đoạn dư thừa.
Cross-Encoder là gì và nó giải quyết vấn đề này như thế nào
Khác với Bi-Encoder, vốn mã hoá query và document riêng rẽ để so khớp bằng cosine similarity, Cross-Encoder nhận cả hai đầu vào cùng lúc rồi tính toán mức độ liên quan một cách trực tiếp.
Cách hoạt động này giống như một “người đọc hiểu” thật sự: xem cả câu hỏi và đoạn văn, rồi quyết định mức độ khớp ngữ nghĩa.
Trong thực tế, pipeline hiệu quả nhất thường kết hợp cả hai:
- Dùng Bi-Encoder để tìm nhanh top-N (ví dụ top-50) tài liệu từ vector store.
- Dùng Cross-Encoder để re-rank các kết quả này, chọn ra top-K (ví dụ top-5) liên quan nhất.
Cách làm này giúp giữ tốc độ (vì Bi-Encoder truy xuất nhanh) đồng thời nâng độ chính xác nhờ Cross-Encoder tinh chỉnh thứ hạng.
Cách tích hợp Cross-Encoder trong pipeline RAG
Pipeline chuẩn khi thêm bước Cross-Encoder sẽ gồm các bước sau:
- Embedding truy vấn và truy xuất dữ liệu: Dùng Bi-Encoder hoặc SentenceTransformer để tìm top-K đoạn văn gần nhất.
- Đánh giá lại bằng Cross-Encoder: Với mỗi cặp (query, document), mô hình Cross-Encoder sẽ gán điểm liên quan (relevance score).
- Sắp xếp lại (Re-ranking): Sắp xếp danh sách tài liệu theo điểm số và chỉ giữ lại những đoạn có độ liên quan cao nhất.
- Xây dựng context: Ghép các đoạn text được chọn vào prompt để gửi đến LLM.
Ví dụ Python code
from sentence_transformers import CrossEncoder
# Load pre-trained Cross-Encoder model
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# Giả sử đã có danh sách retrieved_docs từ vector DB
pairs = [(query, doc) for doc in retrieved_docs]
scores = model.predict(pairs)
# Re-rank theo điểm liên quan
ranked = sorted(zip(retrieved_docs, scores), key=lambda x: x[1], reverse=True)
final_context = [doc for doc, score in ranked[:5]]
Lợi ích khi thêm Cross-Encoder vào pipeline
- Tăng độ chính xác: Giữ lại các đoạn thực sự trả lời đúng câu hỏi.
- Context ngắn gọn hơn: Giảm số token không cần thiết, tiết kiệm chi phí xử lý.
- Cải thiện chất lượng đầu ra: Mô hình sinh phản hồi logic, bám sát ý định truy vấn.
- Tùy chỉnh linh hoạt: Có thể điều chỉnh số lượng top-K hoặc ngưỡng score để cân bằng giữa tốc độ và chất lượng.
Một vài lưu ý cho developer khi triển khai
- Cross-Encoder khá tốn tài nguyên, nên chỉ dùng để re-rank một tập nhỏ (ví dụ top-50 kết quả từ vector search).
- Nên triển khai thành service riêng (REST API hoặc microservice) để dễ scale và bảo trì.
- Cache kết quả re-ranking cho các truy vấn lặp lại nhằm tiết kiệm thời gian xử lý.
- Ghi log trước/sau khi lọc để dễ theo dõi chất lượng retrieval và debug.
Kết luận
Cross-Encoder đóng vai trò như bộ lọc ngữ nghĩa cấp cao giúp làm sạch dữ liệu trước khi đưa vào mô hình ngôn ngữ lớn. Khi kết hợp thông minh giữa Bi-Encoder (tốc độ) và Cross-Encoder (độ chính xác), bạn sẽ có được một RAG pipeline cân bằng — nhanh, gọn, và cho kết quả đáng tin cậy hơn.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-dung-cross-encoder-de-loai-bo-thong-tin-nhieu-khi-xay-context.html
All rights reserved
