HƯỚNG DẪN CÁCH TỐI ƯU AGENT CHUNKING TRONG QUÁ TRÌNH EMBEDDING
Trong kiến trúc Retrieval-Augmented Generation (RAG), chất lượng embedding không chỉ phụ thuộc vào mô hình ngôn ngữ mà còn nằm ở cách bạn xử lý dữ liệu đầu vào thông qua chunking. Gần đây, phương pháp Agent Chunking được xem như bước tiến mới, giúp tạo ra vector embedding có độ chính xác cao và bám sát ngữ cảnh của từng vai trò AI Agent. Bài viết này sẽ đi sâu vào cơ chế, chiến lược và cách tối ưu hóa Agent Chunking trong pipeline embedding dữ liệu.
Ảnh hưởng của kích thước chunk đến chất lượng embedding
Chunking là quá trình chia nhỏ tài liệu (văn bản, hội thoại, mã nguồn, tài liệu kỹ thuật,…) thành những phần có độ dài phù hợp trước khi đưa vào mô hình embedding. Nếu toàn bộ dữ liệu dài hàng nghìn token được embedding một lần, mô hình sẽ mất đi cấu trúc ngữ cảnh, vượt giới hạn token và giảm chất lượng vector.
| Kích thước chunk | Ưu điểm | Hạn chế |
|---|---|---|
| 100–200 token | Dễ xử lý, tốc độ nhanh | Mất ngữ cảnh, vector rời rạc |
| 800–1500 token | Giữ được mạch nội dung | Dễ “nhiễu”, trộn nhiều chủ đề |
| 300–600 token | Cân bằng ngữ nghĩa và hiệu suất | Cần tinh chỉnh theo loại dữ liệu |
Một chunk tối ưu phải giữ được ý nghĩa hoàn chỉnh của nội dung, nhưng không chứa quá nhiều chủ đề khiến embedding trở nên thiếu tập trung.
Agent Chunking là gì?
Agent Chunking là kỹ thuật phân chia dữ liệu theo vai trò hoặc nhiệm vụ (role/task) của từng Agent trong hệ thống. Thay vì cắt dữ liệu đơn thuần dựa trên token hay câu, Agent Chunking sử dụng logic nghiệp vụ và ngữ cảnh riêng của từng Agent để xác định ranh giới chunk.
Ví dụ:
- Agent Sales: chunk theo hành vi khách hàng (intent, objection, follow-up).
- Agent Support: chunk theo cặp hỏi–đáp hoặc category lỗi.
- Agent Developer: chunk theo logic code hoặc module kỹ thuật.
Kết quả là mỗi vector embedding được huấn luyện theo đúng ngữ cảnh vai trò, giúp hệ thống retrieval hoạt động chính xác và chuyên biệt hơn.
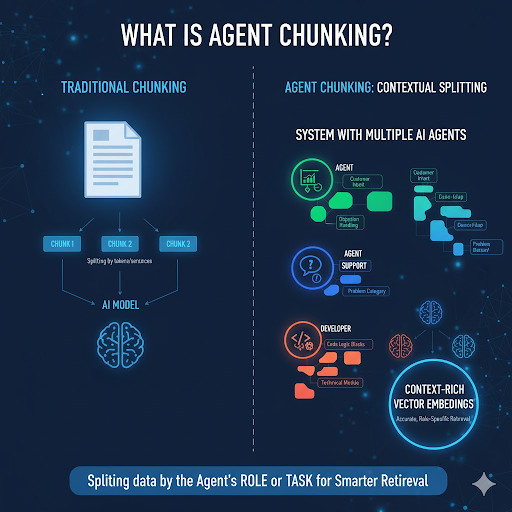
Cấu trúc hoạt động của Agent Chunking
Pipeline tổng quan:
Dữ liệu gốc
↓
Phân loại theo Agent
↓
Áp dụng chiến lược chunk riêng
↓
Sinh embedding bằng mô hình tương ứng
↓
Lưu vector vào Vector Database (namespace riêng)
Ví dụ Python / LangChain-style:
agents = {
"sales": {"strategy": "intent_chunking", "embedding_model": "text-embedding-3-large"},
"support": {"strategy": "qa_pair_chunking", "embedding_model": "text-embedding-3-small"},
"developer": {"strategy": "code_block_chunking", "embedding_model": "code-embedding-ada"}
}
for role, config in agents.items():
docs = load_docs_by_role(role)
chunks = agent_chunk(docs, strategy=config["strategy"])
vectors = embed(chunks, model=config["embedding_model"])
store_in_vector_db(vectors, namespace=role)
Việc phân vùng vector database theo namespace đảm bảo dữ liệu của từng Agent (Sales, Support, Dev) không bị trộn lẫn, giúp quá trình truy xuất diễn ra mạch lạc và chính xác hơn.
So sánh các chiến lược chunking
| Loại chunking | Cách hoạt động | Ưu điểm | Hạn chế |
|---|---|---|---|
| Token-based | Chia theo số lượng token cố định | Nhanh, dễ áp dụng | Cắt ngữ cảnh, thiếu liền mạch |
| Recursive chunking | Chia theo đoạn hoặc tiêu đề | Giữ mạch nội dung cơ bản | Khó áp dụng cho dữ liệu phi cấu trúc |
| Semantic chunking | Dựa trên độ tương đồng ngữ nghĩa | Giữ ý nghĩa sâu | Tốn tài nguyên tính toán |
| Agent chunking | Dựa trên vai trò, logic nghiệp vụ | Tối ưu cho multi-agent system | Cần rule hoặc model riêng từng Agent |
Agent Chunking có thể xem là phiên bản nâng cao của semantic chunking, nhưng định hướng rõ ràng hơn cho ngữ cảnh hành vi của từng Agent.
Ảnh hưởng của Agent Chunking đến chất lượng embedding
Một chiến lược Agent Chunking hợp lý giúp:
- Giảm nhiễu vector nhờ dữ liệu tập trung theo ngữ cảnh vai trò.
- Tăng semantic similarity, cải thiện độ khớp khi truy vấn ngắn.
- Tăng Recall@k và MRR, từ đó nâng hiệu suất RAG pipeline. So sánh minh họa: | Chiến lược | Recall@5 | MRR | Accuracy | | ----------------- | -------- | -------- | -------- | | Token-based | 0.68 | 0.54 | 78% | | Semantic Chunking | 0.75 | 0.63 | 84% | | Agent Chunking | 0.83 | 0.71 | 91% |
Ứng dụng thực tế
Trong hệ thống RAG:
Khi người dùng hỏi “Khách hàng từ chối nhận hàng thì xử lý thế nào?”, hệ thống sẽ tự động truy xuất vector từ namespace Sales, thay vì nhầm sang nội dung kỹ thuật.
Trong Multi-Agent System:
- Analyzer: chunk theo logic insight.
- Planner: chunk theo quy trình hành động.
- Executor: chunk theo action block cụ thể.
Trong BizChatAI: Có thể áp dụng Agent Chunking để xây dựng bộ nhớ hội thoại đa vai trò:
- Chatbot bán hàng → chunk theo intent.
- Chatbot CSKH → chunk theo quy định & category vấn đề.
- Chatbot kỹ thuật → chunk theo FAQ hoặc lỗi hệ thống.
Nhờ đó, AI hiểu rõ ngữ cảnh – vai trò – mục tiêu, giúp phản hồi đúng và tự nhiên hơn.
Đánh giá hiệu quả Agent Chunking
Các chỉ số đánh giá chính:
- Mean Cosine Similarity giữa query và chunk đúng.
- Recall@k, MRR, và Latency khi truy vấn.
Kết quả ví dụ:
| Trước Agent Chunking | Recall@5 = 0.71 | MRR = 0.62 | Latency = 380ms |
|---|---|---|---|
| Sau Agent Chunking | Recall@5 = 0.83 | MRR = 0.71 | Latency = 350ms |
→ Cho thấy tốc độ và độ chính xác retrieval tăng đáng kể khi chunking được tối ưu hóa theo vai trò.
Kết luận
Agent Chunking không chỉ là kỹ thuật xử lý dữ liệu, mà là chiến lược tư duy hệ thống trong việc xây dựng AI Agent có khả năng hiểu ngữ cảnh sâu.
Thay vì chỉ tối ưu mô hình embedding, hãy đầu tư vào việc thiết kế pipeline chunking theo vai trò và logic nghiệp vụ. Đây là nền tảng để tạo nên các hệ thống RAG, multi-agent và trợ lý AI có khả năng phản hồi tự nhiên, chính xác và hiệu quả hơn.
Trong tương lai, Agent Chunking có thể được kết hợp với Dynamic Memory Routing, cho phép AI tự học cách chọn chiến lược chunk tối ưu theo mục tiêu hội thoại hoặc nhiệm vụ thực thi.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-cach-toi-uu-agent-chunking-trong-qua-trinh-embedding.html
All rights reserved
