How to calculate _score in Elasticsearch?
Bài đăng này đã không được cập nhật trong 8 năm
Chúng ta khi sử dụng Elasticsearch thường thấy _score field trả về sau mỗi kết quả nhưng đã bao giờ chúng ta tự đặt câu hỏi, nó là gì và có tác dụng gì? Hôm nay chúng ta sẽ thử đi qua xem nó là gì, những gì tác động lên nó và cách tính nó ra làm sao nhé.
I. Theory behind relevance scoring
Elasticsearch sử dụng Boolean Model để tìm kiếm các documents, và 1 công thức được gọi là practical scoring function để tính toán sự liên quan. Công thức này mượn các khái niệm term frequency/inverse document frequency và vector space model nhưng thêm các tính năng hiện đại hơn như yếu tố phối hợp, chuẩn hóa độ dài term và làm mạnh mệnh đề truy vấn.
II. Boolean Model
Boolean Model đơn giản dụng các điều kiện AND, OR và NOT được biểu thị trong truy vấn để tìm tất cả các tài liệu phù hợp. Một truy vấn cho
full AND text AND search AND (elasticsearch OR lucene)
sẽ chỉ bao gồm các tài liệu chứa tất cả các terms full, text và search, cũng như elasticsearch hoặc lucene.
Quá trình này rất đơn giản và nhanh chóng. Nó được sử dụng để loại trừ bất kỳ documents nào không có khả năng khớp với truy vấn.
III. Term Frequency/Inverse Document Frequency (TF/IDF)
Khi chúng ta tìm được danh sách các documents, chúng cần được đánh giá theo độ liên quan. Không phải tất cả các documents đều chứa tất cả các terms, và một số terms là quan trọng hơn các terms còn lại. Điểm liên quan của toàn bộ documents phụ thuộc (một phần) vào trọng số của mỗi cụm từ truy vấn xuất hiện trong tài liệu đó.
1. Term Frequency
How often does the term appear in this document? The more often, the higher the weight. Một trường có chứa năm đề cập của cùng một cụm từ có nhiều khả năng có liên quan hơn một trường chỉ chứa một đề cập. Term frequency được tính như sau:
tf(t in d) = √frequency (căn bậc 2 số lần terms xuất hiện trong documents)
Nếu không quan tâm số lần terms xuất hiện trong documents, bạn chỉ cần set: "index_options": "docs" khi đánh mapping:
{
"mappings": {
"doc": {
"properties": {
"text": {
"type": "string",
"index_options": "docs"
}
}
}
}
}
2. Inverse document frequency
How often does the term appear in all documents in the collection? The more often, the lower the weight. Trái ngược với bên trên bạn có thể nhận thấy, các terms phổ biến như and hoặc the đóng góp ít cho mức độ liên quan khi chúng xuất hiện trong hầu hết các tài liệu, trong khi các terms như elasticsearch hoặc hippopotamus giúp chúng ta zoom in trên hầu hết các tài liệu liên quan. inverse document frequency được tính như sau:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
=> Logarithm của số các documents trong index, chia cho số các document chứa term
3. Field-length norm
How long is the field? The shorter the field, the higher the weight. Nếu term xuất hiện trong một field ngắn, chẳng hạn như field title, có nhiều khả năng nội dung của field đó là về term hơn nếu cùng một term xuất hiện trong field body lớn hơn nhiều. field length norm được tính như sau:
norm(d) = 1 / √numTerms
=> Nghịch đảo của căn bậc 2 số lượng term trong 1 field.
Trong khi field length norm là quan trọng cho full-text search, nhưng rất nhiều fields khác lại không cần norms. Norms tiêu thụ xấp xỉ 1 byte trên string field trên document trong index. Có 2 cách để disable norms, 1 là index: not_analyzed và 2 là:
{
"mappings": {
"doc": {
"properties": {
"text": {
"type": "string",
"norms": { "enabled": false }
}
}
}
}
}
IV. Putting it together
3 nhân tố này: term frequency, inverse document frequency, and field-length norm được tính toán và lưu trữ tại index time. Cùng nhau, chúng được sử dụng để tính trọng số của một term trong một document cụ thể.
Note: Khi chúng ta đề cập đến các tài liệu trong các công thức trước, chúng ta đang thực sự nói về một field trong một document. Mỗi field có inverted index riêng và do đó, cho các mục đích TF / IDF, giá trị của field là giá trị của document.
Khi chúng ta chạy một truy vấn term đơn giản với explain được set bằng true, bạn sẽ thấy rằng các yếu tố duy nhất liên quan đến việc tính toán điểm số là những yếu tố được giải thích trong các phần trước:
PUT /my_index/doc/1
{ "text" : "quick brown fox" }
GET /my_index/doc/_search?explain
{
"query": {
"term": {
"text": "fox"
}
}
}
Giải thích:
weight(text:fox in 0) [PerFieldSimilarity]: 0.15342641
result of:
fieldWeight in 0 0.15342641 (1)
product of:
tf(freq=1.0), with freq of 1: 1.0 (2)
idf(docFreq=1, maxDocs=1): 0.30685282 (3)
fieldNorm(doc=0): 0.5 (4)
1 Score cuối cùng của term fox trong field text trong document
2 Term fox xuất hiện một lần trong field text trong document.
3 Chỉ số inverse document frequency của term fox trong text field trong toàn bộ document trong index
4 Chuẩn hóa field-length cho field này.
Tất nhiên, các truy vấn thường bao gồm nhiều hơn một term, vì vậy chúng ta cần một cách kết hợp trọng số của nhiều term. Đối với điều này, chúng ta chuyển sang vector space model.
V. Vector Space Model
vector space model cung cấp một cách so sánh truy vấn multiterm dựa trên document. Đầu ra là một score duy nhất thể hiện mức độ phù hợp của document với truy vấn. Để làm điều này, model biểu diễn cả tài liệu và truy vấn dưới dạng vectơ. Một vector thực sự chỉ là một mảng một chiều có chứa các số, ví dụ:
[1,2,5,22,3,8]
Trong vector space model, mỗi số trong vectơ là trọng số của term, như tính toán với term frequency/inverse document frequency.
Tưởng tượng rằng chúng ta có 1 câu query cho “happy hippopotamus.”. Giả sử rằng happy có trọng số là 2 và hippopotamus có trọng số 5. Chúng ta có thể đặt mảng 2 chiều [2, 5] như một dòng trên một đồ thị bắt đầu tại điểm (0,0) và kết thúc tại điểm (2,5) như sau:
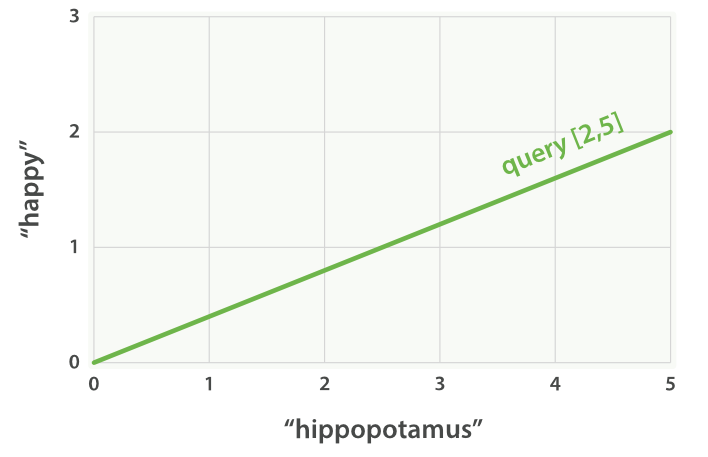
Bây giờ, hãy tưởng tượng rằng ta có 3 documents:
- I am happy in summer.
- After Christmas I’m a hippopotamus.
- The happy hippopotamus helped Harry.
Chúng ta sẽ tạo các vecto tương tự cho mỗi document, bao gồm trọng số của mỗi truy vấn term -- happy và hippopotamus
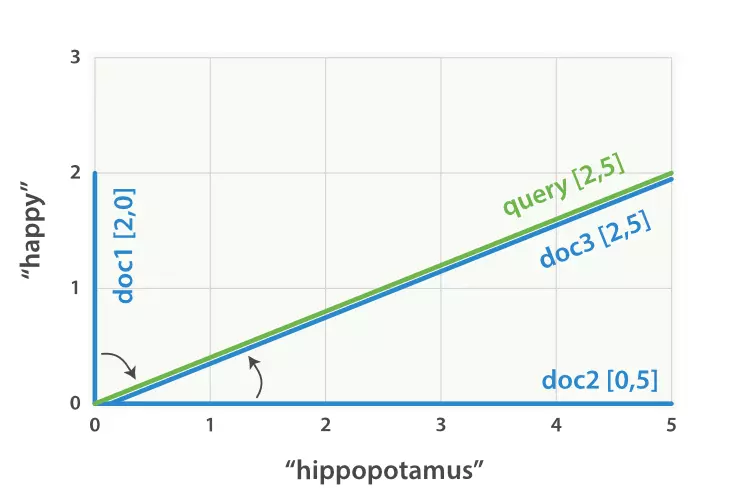
- Document 1: (happy,____________)—[2,0]
- Document 2: ( ___ ,hippopotamus)—[0,5]
- Document 3: (happy,hippopotamus)—[2,5]
Dựa vào đây chúng ta có thể so sánh được các vectơ bằng cách đo góc giữa vecto truy vấn và document vecto, và căn cứ vào đó để assign score relevance đến các document. Document 2 gần hơn với truy vấn, có nghĩa là nó có độ liên quan hơn và document 3 là một perfect match.
VI. Reference
https://www.elastic.co/guide/en/elasticsearch/guide/current/scoring-theory.html
All rights reserved
