How Elasticsearch work? - Elasticsearch under the hood.
Bài đăng này đã không được cập nhật trong 8 năm
Introduction
Bạn đã bao giờ tự hỏi Elasticsearch hoạt động như thế nào? Bài viết này mình sẽ đề cập đến những điều cơ bản về Search Engine. Chúng ta sẽ nói về cái cách mà search engine tìm kiếm data cho những câu query chỉ trong vài miliseconds.
Vì vậy, hãy bắt đầu với các bước liên quan đến việc xây dựng các câu truy vấn nhanh:
1) Lexical analysis for indexing
2) Removing stop words
3) Stemming
4) Synonyms
5) Persistence
6) Ranking
Lexical Analysis :
Tại bước này, lượng text khổng lồ sẽ được convert thành các nhóm từ (tokens). Điều đó có nghĩa là văn bản của bạn sẽ được chuyển đổi thành một tập hợp con có chứa một tập các từ duy nhất dựa trên cơ sở tìm kiếm.
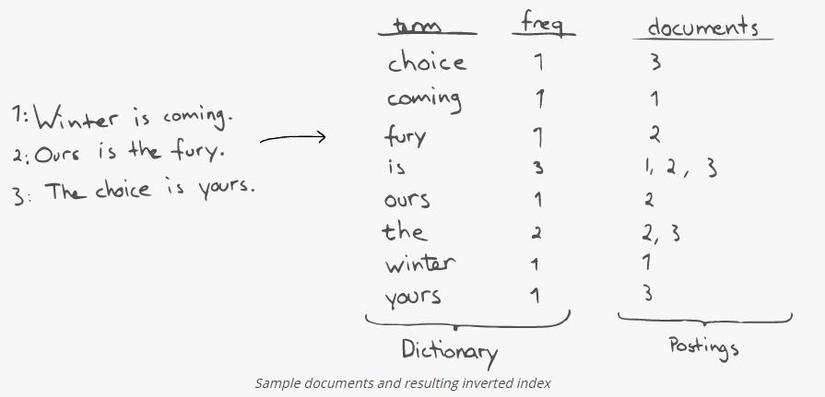
Bạn có nhớ các chỉ mục ở cuối cuốn sách mà bạn yêu thích? Hãy em hình ảnh bên dưới

Trong thế giới của search engine điều này được gọi là inverted index. Về cơ bản là bạn đã có một sự ánh xạ ngược của các từ với các trang để phục vụ cho việc tìm kiếm nhanh chóng hơn. Ví dụ như sau:
Giả sử bạn phải tìm kiếm số lượng của một từ cụ thể trong một số lượng lớn các tài liệu. Bạn sẽ làm điều đó như thế nào? Cách tiếp cận dễ nhất là đọc từng trang của mỗi tài liệu và tăng số lượng của bạn khi bạn tìm thấy từ đó. Sau khi đọc mọi tài liệu, bạn sẽ có câu trả lời.
Sau một thời gian bạn lại phải nhắc đến từ đó, nhưng đợi đã ... Bạn có muốn scan lại các tài liệu 1 lần nữa? Bạn có thể làm điều đó, nhưng điều đó là cực kì mất effort và time. Bạn không thể làm vậy mỗi lần bạn cần tìm kiếm 1 nội dung nào đó. Sau khi suy nghĩ một chút, bạn có ý tưởng ghi lại số trang cho những từ bạn gặp phải. Chẳng hạn cho truy vấn tiếp theo bạn chỉ cần tham khảo số trang và nhảy trực tiếp vào đó.
Khi bạn làm điều này cho tất cả các từ (mà bạn thực sự quan tâm), bạn sẽ có một tài liệu được gọi là Inverted Index.
Vì vậy, ý tưởng là gì - Tạo một chỉ mục của tất cả các từ quan trọng và lưu nó ở đâu đó.
Định nghĩa chung - Inverted index là một ánh xạ giữa terms(nội dung thực tế / words / tokens) và postings (các tài liệu mà từ đó xuất hiện). Ví dụ:
Removing stop words:

Nói chung trong văn bản lớn có rất nhiều từ không hữu ích cho các truy vấn tìm kiếm của bạn.Các từ này được biết đến như là stop words. Ví dụ a, an, is, the, to ... Các từ này thực sự không có quá nhiều giá trị để bạn đánh index, và nếu bạn làm điều đó bạn sẽ vô tình làm tăng kích thước index của bạn lên không cần thiết. Vì vậy, một danh sách stop words cần được xác định và sẽ không được lập index.
Stemming :

Stemming nói chung là tước bỏ các chữ cái từ words và mang chúng thành dạng root.Ví dụ như fishing, fisherman, fisher, fishy đều đến từ từ fish. Bước quan trọng này sẽ giúp loại bỏ sự dư thừa. Ý tưởng ở đây là chúng ta không thể và không nên lưu trữ tất cả các dạng ngữ pháp của một từ đơn. Người dùng tìm kiếm có thể có ý muốn tìm kiếm một dạng cấu trúc khác của từ thay vì phải nghĩ xem từ đó chính xác là gì. Ví dụ: “run” -> “running”,”runner” , “swim” -> “swimming”,”swims” etc.
Synonym Database (Lemmatization) :
Một synonym database có thể được xây dựng để tìm kiếm dựa trên các từ tương đương nhau về nghĩa. Việc thực hiện này giống như stemming, sự khác biệt duy nhất là từ khoá được ánh xạ tới các từ có ý nghĩa tương tự nhưng lại khác nhau hoàn toàn về ngữ pháp của các từ khóa. Ví dụ: car -> vehicle, Automobile -> vehicle , plane -> vehicle
Persistence:

Persistence indices cho phép truy xuất nhanh các thông tin được lập index trước đó. Tất cả các thông tin quan trọng trên một từ là pre-processed và được mô tả trong các bước trên và lưu trữ, làm cho việc thu thập thông tin nhanh hơn.
Relevance Ranking :
Các từ khoá được chỉ định một relevance ranking, đó là tính toán tần suất của từ khoá so với tổng số từ khóa trong tài liệu. Điều này đảm bảo rằng các kết quả tìm kiếm có liên quan nhiều hơn đến những gì người dùng cần. Relevance Ranking giúp end-users xác định được thông tin mong muốn bằng cách chỉ ra kết quả nào (đặc biệt là trong một tập hợp kết quả lớn) có nhiều khả năng mang lại thông tin thích hợp nhất.
In Conclusion
Tất cả các bước trên giúp Elasticsearch trở nên có khả năng giải quyết các truy vấn tìm kiếm với số lượng lớn dữ liệu với trải nghiệm người dùng được cải thiện.
Tại liệu tham khảo:
https://geeknarrator.com/2017/10/02/how-search-engine-works-elastic-search-part-1/
All rights reserved
