How Does DALL·E 2 Work?
Bài đăng này đã không được cập nhật trong 3 năm
Vào ngày 6 tháng 4 năm 2022, OpenAI công bố mô hình mới nhất của họ là DALLE 2, đi kèm với bài báo có tên là Hierarchical Text-Conditional Image Generation with CLIP Latents. Mô hình có thể tạo ra những hình ảnh với độ phân giải cao với nhiều thuộc tính và phong cách khác nhau, dựa vào một đoạn text mô tả. Những hình ảnh mà DALLE 2 tạo ra vừa độc đáo vừa chân thực. Nó có thể phối kết hợp các thuộc tính, concept và các phong cách khác nhau. Tính hiện thực của ảnh, sự tạo ra được các biến thể khác nhau và khả năng tạo ra ảnh có mức độ tương quan cao với caption đã khiến DALLE 2 trở thành một trong những sự cải tiến đáng được quan tâm nhất hiện nay. Bài viết sau đây sẽ đi vào chi tiết cách mà DALLE-2 hoạt động.

1. Tổng quan về DALLE-2
Về tổng quan, ban đầu dữ liệu đầu vào của DALLE-2 là các cặp image-caption, sau đó sẽ có một text encoder sẽ lấy đoạn text mô tả (y) và sinh ra text embedding . Text embedding này sẽ làm đầu vào cho một model gọi là prior, từ đó sinh ra image embedding tương ứng. Cuối cùng, một image decoder sẽ biến đổi image embedding đó thành ảnh cuối cùng (i).
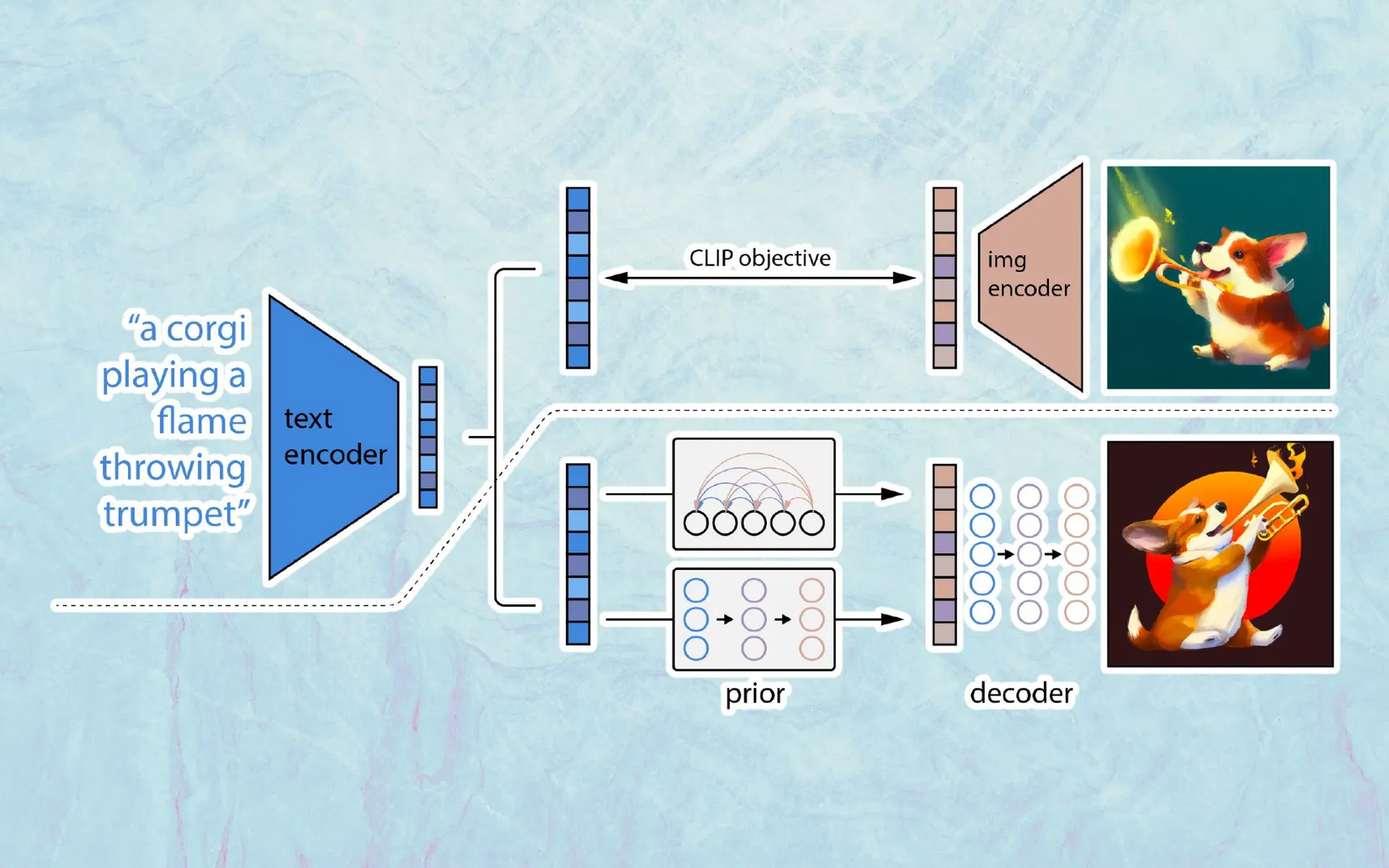
Ảnh bên trên mô tả 2 giai đoạn training của DALLE-2: Giai đoạn 1 là training CLIP model để lấy image embedding và text embedding (), sang giai đoạn 2, CLIP model được đóng băng và thực hiện quá trình sinh ảnh bởi prior và decoder
Về khái quát là như vậy, nhưng cụ thể thì sao? Trước tiên, text và image embedding mà DALLE-2 sử dụng sẽ do một model khác tạo ra, đó là CLIP. Chi tiết CLIP thế nào thì chúng ta hãy cùng tìm hiểu bên dưới.
2. CLIP (Contrastive Language–Image Pre-training)
CLIP là viết tắt của cụm từ Contrastive Language–Image Pre-training. Mục tiêu của CLIP là kết nối text – image; tức là text embedding và image embedding được tạo ra từ CLIP sẽ có một độ tương quan lẫn nhau nhất định và mang thông tin của nhau. Vậy cụ thể là làm như thế nào?
 Mô tả một cách đơn giản thì CLIP hoạt động như sau:
Mô tả một cách đơn giản thì CLIP hoạt động như sau:
Với đầu vào là các cặp image-caption:
Bước 1: Sinh image embedding và text embedding cho mỗi một cặp ảnh-caption từ text encoder và image encoder (model cho text encoder và image encoder có nhiều lựa chọn, chẳng hạn như image encoder thì dùng vision transformer hoặc CNN, text encoder thì có thể dùng transformers...
Bước 2: Tính toán cosine similarity cho từng cặp text-image embedding
Bước 3: Lặp lại quá trình maximize cosine similarity cho cặp ảnh-caption đúng và minimize cosine similarity cho các cặp ảnh-caption không khớp với nhau
Hàm loss: Với 2 ma trận có được là image embedding matrix và text embedding matrix, ta nhân dot product với nhau, ra ma trận mới tạm gọi là ma trận dot product. Ta cũng tính ma trận cosine similarity giữa các cặp ảnh và text để ra ma trận cosine similarity. Sau đó dùng hàm cross-entropy để minimize phân phối giữa hai ma trận này
Sau khi training xong, chúng ta sẽ đóng băng mô hình lại và chuyển sang giai đoạn tiếp theo: tìm ra image embedding phù hợp nhất cho caption đầu vào
3. PRIOR - Kết nối ngữ nghĩa văn bản và ngữ nghĩa hình ảnh
Mặc dù CLIP có thể tạo ra text embedding và image embedding, nhưng cuối cùng image embedding từ CLIP không được dùng để sinh ra ảnh ở giai đoạn decode. DALLE 2 sử dụng một model khác để tạo ra image embedding , đó là prior model, cụ thể là diffusion prior. Chúng ta hãy dừng lại để xem qua một chút về diffusion model nhé

Hãy tưởng tượng chúng ta có một ảnh sau đó dần dần thêm nhiễu vào ảnh đó (nhiễu lấy từ phân phối Gaussian) với số lượng timestep đủ lớn để bức ảnh toàn nhiễu và không thể nhận ra được có cái gì trong bức ảnh đấy nữa, rồi từ ảnh toàn nhiễu đó chúng ta lại khử nhiễu để có được bức ảnh hoàn chỉnh. Chính xác, đó là ý tưởng đằng sau diffusion model. Quá trình thêm nhiễu vào ảnh là quá trình thuận, quá trình khử nhiễu ảnh được gọi là quá trình nghịch. Toàn bộ quá trình được mô tả bằng chuỗi Markov, tức là xác suất chuyển từ một trạng thái chỉ phụ thuộc vào trạng thái trước đó mà không phụ thuộc vào bất kì trạng thái nào khác.
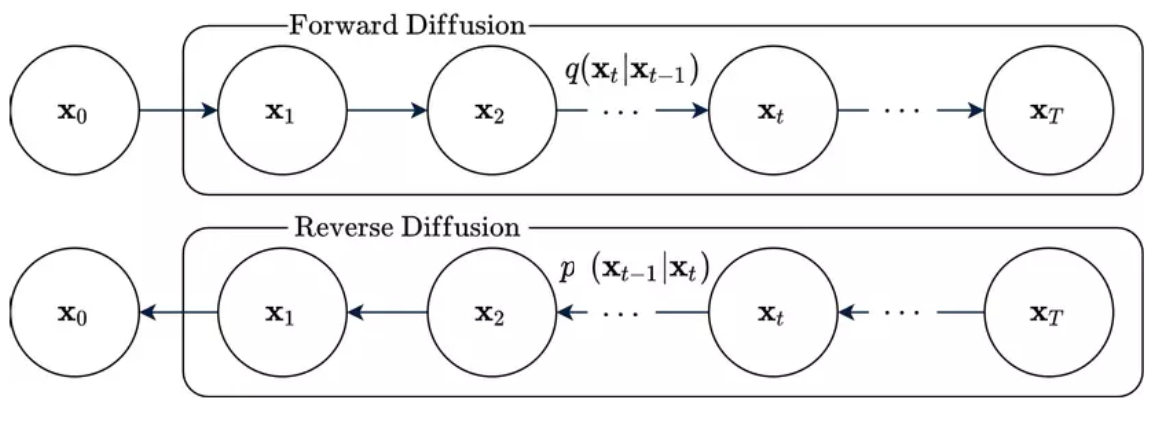
Chúng ta sẽ lấy ví dụ với một bức ảnh, và gọi nó là . Ở quá trình thuận, ta sẽ dần dần thêm nhiễu để có được một bức ảnh toàn nhiễu ở timestep thứ (). Xác suất chuyển từ timestep sang timestep được ký hiệu là . Từ tính chất Markov, xác suất liên hợp được phân tích thành:
Xác suất chuyển sẽ được xác định trước là một phân bố nào đó. Ở đây, xác suất chuyển được mô hình bởi . Trong đó, là phương sai tại timestep và là một hyperparameter; qua mỗi timestep nó sẽ được tăng lên nhưng vẫn giới hạn trong khoảng . Đến timestep , ta có , lúc này ta đã mất hết thông tin đã có trong ảnh lúc đầu và có được bức ảnh toàn nhiễu
Còn trong quá trình nghịch, khi ta đã có được phân bố , việc sinh dữ liệu sẽ bắt đầu từ phân bố này, sau đó biến đổi ngược trở về phân bố ban đầu. Xác suất liên hợp được phân tích thành:
Mục tiêu lúc này là tìm xác suất chuyển . Ta sẽ mô hình xác suất này bởi phân bố Gaussian, có dạng . Khi mô hình được quá trình nghịch rồi, ở bước sinh dữ liệu, dữ liệu từ phân bố của sẽ được biến đổi thêm dựa trên xác suất chuyển này.
Hàm loss được tính như sau:
Trong đó, là nhiễu ban đầu được thêm vào, là nhiễu được dự đoán. Mục tiêu của hàm loss trên là minimize khoảng cách giữa và . Ta sẽ sinh ra và tính được với Còn với . Và được học bởi mô hình Unet.
Phía trên là khái quát cách thức mà diffusion model hoạt động, vậy diffusion prior là như thế nào?
Về cơ bản là người ta sẽ dùng một diffusion model, nhưng trong quá trình nghịch, thay vì dùng Unet ở bước học thì tác giả thay vào bằng phần decoder của Transformer. Đầu vào của decoder-only Transformer gồm 1 chuỗi các thành phần: encoded text (y), the CLIP text embedding , diffusion timestep và the CLIP image embedding được noise.
Sau các bước trên, ta sẽ có được unnoised image embedding
4. Decoder - gen ảnh từ image embedding ()
Sau khi có được image embedding (), việc tiếp theo sẽ là decode image embedding () ra ảnh. Tác giả chọn dùng model GLIDE để làm decoder. GLIDE là một diffusion model nhưng có chỉnh sửa một chút. Cụ thể ở đây là nó sẽ thêm thông tin về text để guide quá trình học của model. Bởi vì đối với một diffusion model đơn thuần, quá trình từ nhiễu trắng đến ảnh được gen ra sẽ không có bất kì sự chỉ dẫn cụ thể nào để gen ra một ảnh với một nội dung mong muốn cụ thể. Ví dụ, ta có một diffusion model được train trên tập dataset về chó sẽ gen ra ảnh một con chó giống như thật. Nhưng nếu chúng ta muốn gen ra ảnh một loại chó cụ thể thì sao?
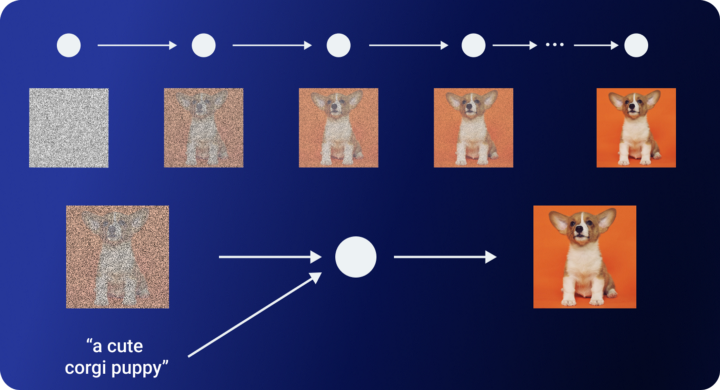
Ở quá trình ngược ở diffusion model, thông tin về text sẽ được thêm vào. Phần text này sẽ được encode qua mô hình Transformer. Sau khi có được embedding từ Transformer, ta sẽ lấy embedding đó để làm conditioning cho diffusion model . Tức là ở đây sẽ thành .
Vậy làm sao để tích hợp thêm embedding kia? Ở quá trình denoise, trong bước học tác giả có dùng mạng Unet để thực hiện điều này.
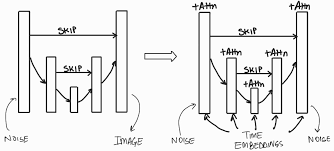
Embedding này sẽ được ánh xạ tới các lớp trung gian của UNet thông qua cơ chế cross-attention. Cụ thể:
Với là một đại diện trung gian của UNet khi thực hiện Denoising, tức là đây là giá trị output trước khi đi qua Max pool hay Up-conv trong Unet. là ma trận học được trong quá trình huấn luyện.
Lúc này hàm loss của chúng ta sẽ có dạng như sau:
Nhờ quá trình trên, ảnh cuối cùng được sinh ra đã mang nội dung mong muốn từ caption. Đây chính là ý nghĩa text-conditional image generation mà tác giả nhắc đến từ đầu.
Kết luận
Đến đây, chúng ta có thể xâu chuỗi lại toàn bộ quá trình như sau:
- Sử dụng CLIP model để tạo ra image embedding và text embedding
- Sau đó diffusion prior tạo ra image embedding từ CLIP text embedding và CLIP image embedding
- Dùng decoder (diffusion-base) để decode từ image embedding ra ảnh cuối cùng
Tham khảo
- Hierarchical Text-Conditional Image Generation with CLIP Latents (https://arxiv.org/pdf/2204.06125.pdf)
- Learning Transferable Visual Models From Natural Language Supervision (https://arxiv.org/pdf/2103.00020.pdf)
- GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (https://arxiv.org/pdf/2112.10741.pdf)
All rights reserved
