How browser rendering works — behind the scenes
Bài đăng này đã không được cập nhật trong 3 năm
Xin chào các bạn, lượn lờ trên medium tình cờ mình có đọc được 1 bài viết khá hay, nhân tiện dịch luôn làm bài report cuối tháng (lol).
Hi vọng bài viết sẽ giúp bạn giải thích một cách đơn giản, các bước mà trình duyệt của bạn cần để chuyển đổi HTML, CSS và JavaScript thành một trang web đang hoạt động mà bạn có thể tương tác.
Biết quá trình mà trình duyệt của bạn thực hiện để đưa trang web vào cuộc sống sẽ giúp cho bạn có thể tối ưu hóa các ứng dụng web của bạn để có tốc độ và performance nhanh hơn.
1. Giới thiệu
Câu hỏi được đặt ra: Các trình duyệt render các thẻ HTML như thế nào?
Mình sẽ sớm giải đáp quá trình này, nhưng trước tiên, tóm tắt lại một số khái niệm cơ bản trước đã nhé 
Một trình duyệt web tải tập tin từ một máy chủ từ xa (hoặc một local disk) và hiển thị chúng cho bạn - cho phép người dùng tương tác.
Chắc các bạn đều biết trình duyệt là gì  . Nhưng thực chất, trong trình duyệt còn tồn tại một phần mềm được gọi là công cụ trình duyệt: Các trình duyệt khác nhau nhưng đều sẽ có một phần của trình duyệt làm nhiệm vụ tìm ra những gì sẽ hiển thị cho bạn dựa trên các tệp mà nó nhận được, và nó được gọi là công cụ trình duyệt.
. Nhưng thực chất, trong trình duyệt còn tồn tại một phần mềm được gọi là công cụ trình duyệt: Các trình duyệt khác nhau nhưng đều sẽ có một phần của trình duyệt làm nhiệm vụ tìm ra những gì sẽ hiển thị cho bạn dựa trên các tệp mà nó nhận được, và nó được gọi là công cụ trình duyệt.
2. Gửi và nhận thông tin
Đây không phải là lớp mạng khoa học máy tính, nhưng các bạn có thể cần nhớ rằng dữ liệu được gửi qua internet dưới dạng "gói" có kích thước bằng byte.
 Điều mình đang muốn nói đến là khi bạn viết một số HTML, CSS và JS và cố gắng mở tệp HTML trong trình duyệt của mình, khi đó trình duyệt sẽ chỉ đọc các byte thô của HTML từ ổ đĩa (hoặc mạng) của bạn mà thôi.
Điều mình đang muốn nói đến là khi bạn viết một số HTML, CSS và JS và cố gắng mở tệp HTML trong trình duyệt của mình, khi đó trình duyệt sẽ chỉ đọc các byte thô của HTML từ ổ đĩa (hoặc mạng) của bạn mà thôi.
Tức là thực ra trình duyệt đọc byte dữ liệu raw và chứ không phải là những ký tự trong code bạn đã viết đâu .
Nhưng!!!!!
Khi đó, mặc dù trình duyệt đã nhận được các byte dữ liệu, và đọc được nó, tuy nhiên là trình duyệt chẳng thể làm bất cứ điều gì với các dữ liệu đó cả.
Vì vậy, ta cần phải chuyển đổi các byte dữ liệu raw thành một dạng mà nó có thể hiểu được.
Đây chính là bước đầu tiên.

3. Từ byte raw từ HTML sang DOM
DOM là viết tắt của Document Object Model
Vậy, đối tượng DOM được bắt nguồn như thế nào?
Đơn giản lắm
Đầu tiên, các byte dữ liệu raw sẽ được chuyển đổi thành các ký tự:
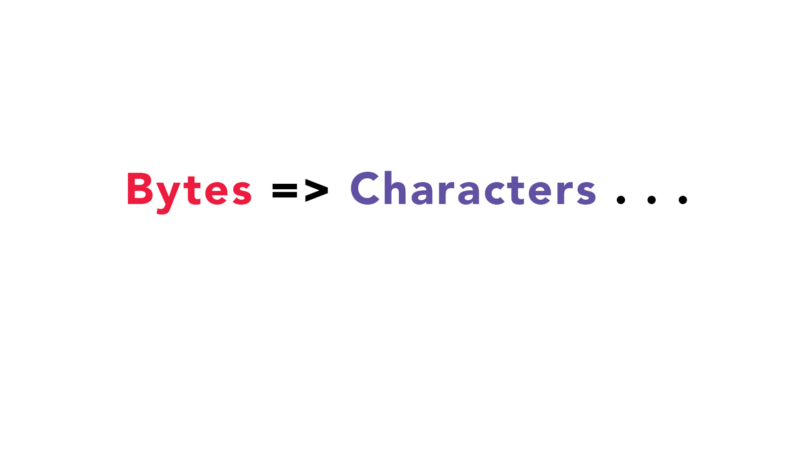
Lúc này, trình duyệt đã chuyển từ byte dữ liệu thô sang các ký tự thực trong tệp. Chuyển thành ký tự là có vẻ là 'ngon' rồi nhỉ? Nhưng chưa, đến đây vẫn chưa xong.
Các ký tự này tiếp đó sẽ được phân tích cú pháp thành một thứ gọi là tokens.

Vậy tokens là gì ?
Nếu không có quá trình tokenization này, đám chuỗi ký tự kia sẽ chỉ là 1 đống văn bản vô nghĩa - chứ chưa tạo thành website thực.
Khi bạn lưu tệp có đuôi .html, nghĩa là bạn đã báo hiệu cho công cụ trình duyệt là "hãy thông dịch file này dưới dạng tài liệu html". Cách trình duyệt “thông dịch” file này là phân tích cú pháp của nó trước tiên đã.
Trong quá trình phân tích cú pháp, và đặc biệt là trong quá trình tokenization, mọi thẻ html mở và đóng trong tệp sẽ đều được tính.
Trình phân tích cú pháp phân tích mỗi chuỗi trong các cặp thẻ <html>, ví dụ thẻ <p>, và hiểu rằng đó là tập hợp các quy tắc áp dụng cho mỗi chuỗi.
Bạn có thể thấy tokens như một loại cấu trúc dữ liệu chứa thông tin về một thẻ html nhất định. Về cơ bản, một file html được chia nhỏ thành các đơn vị phân tích cú pháp nhỏ được gọi là tokens. Đây là cách trình duyệt bắt đầu hiểu những gì bạn đã viết.
 Tokens thì cũng có vẻ 'ngon' hơn rồi đấy, nhưng chúng vẫn chưa phải là kết quả cuối cùng .
Tokens thì cũng có vẻ 'ngon' hơn rồi đấy, nhưng chúng vẫn chưa phải là kết quả cuối cùng .
Sau khi tokenization được thực hiện, các thẻ sau đó được chuyển đổi thành các node.
Bạn có thể nghĩ các nodes(nút) là các đối tượng riêng biệt với các thuộc tính cụ thể. Nhưng mà một cách dễ hiểu hơn là, hãy coi nodes như là một thực thể riêng biệt trong cây document object ấy.
Khi tạo các nút này, các nút sau đó được liên kết trong cấu trúc dữ liệu cây được gọi là DOM.
DOM sẽ thiết lập các mối quan hệ cha-con, các mối quan hệ anh chị em liền kề, v.v.
Mối quan hệ giữa mỗi nút được thiết lập trong đối tượng DOM này.
Dưới đây là một ví dụ mà chúng ta có thể tham khảo để tìm hiểu.
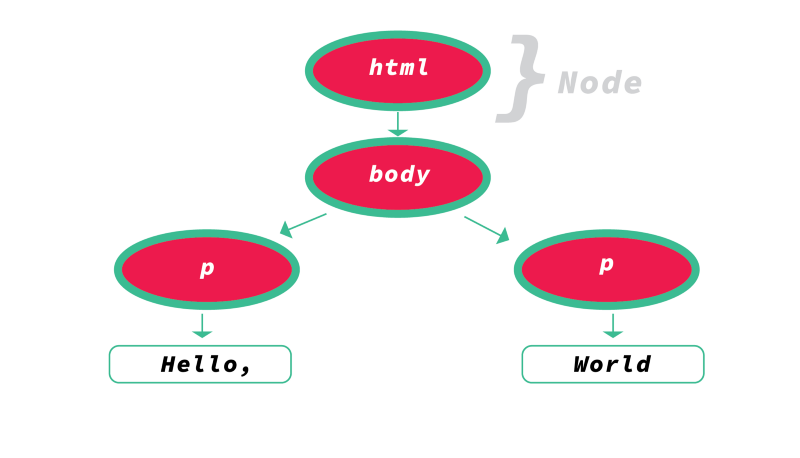
Như vậy chúng ta có thể kết luận:
Trình duyệt sẽ phải chuyển đổi các byte html dữ liệu raw thành DOM trước khi làm tiếp bất cứ điều gì khác.
 Quy trình sẽ là như thế này:
Quy trình sẽ là như thế này:

4. Vậy CSS thì sao ?
Css sẽ được khai báo trong file html theo cách dưới đây
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" type="text/css" media="screen" href="main.css" />
</head>
<body>
</body>
</html>
Trong khi trình duyệt nhận được byte dữ liệu raw và khởi chạy quá trình xây dựng DOM, trình duyệt cũng sẽ yêu cầu tìm nạp file main.css được khai báo bên trên.
Ngay khi trình duyệt bắt đầu phân tích cú pháp html, thì cũng đồng thời tìm tới link vào file css, và trình duyệt đồng thời đưa ra yêu cầu tìm nạp tệp đó.
Chắc các bạn cũng đoán được, trình duyệt cũng nhận được các byte raw của dữ liệu CSS, từ internet hoặc ổ đĩa của bạn (giống như bên trên thôi ).
Nhưng mà chính xác thì sẽ làm gì với đám byte dữ liệu CSS raw này thế?
5. Từ byte raw của CSS tới CSSOM
Bạn thấy đấy, một quá trình tương tự với byte raw của HTML cũng được bắt đầu khi trình duyệt nhận được byte raw của CSS.
Ý mình là, các byte dữ liệu raw sẽ được chuyển đổi thành các ký tự => sau đó cũng được mã hóa => tạo thành các node => rồi cuối cùng, một cấu trúc cây sẽ được hình thành.
Vậy cấu trúc cây là gì?
Vâng, chắc hầu hết mọi người đều đã nghe và biết có cái gì đó được gọi là DOM nhỉ? Tương tự vậy, cũng có một cấu trúc cây CSS được gọi là CSS Object Model, hay gọi là CSSOM cho ngắn.
Các bạn thấy đấy, trình duyệt không thể làm việc với các byte raw của HTML hoặc CSS. Vậy nên sẽ cần phải chuyển đổi thành một dạng mà nó có thể nhận diện được - thế là tương tự lại có cấu trúc cây này:
 CSS có 1 thứ gọi là Cascade. Cascade là cách trình duyệt xác định
CSS có 1 thứ gọi là Cascade. Cascade là cách trình duyệt xác định style nào được áp dụng cho một phần tử.
Do thực tế là các style ảnh hưởng đến một phần tử có thể đến từ một phần tử cha, tức là thông qua thừa kế, hoặc đã được thiết lập trên chính phần tử, nên cấu trúc cây CSSOM trở nên rất quan trọng.
Vì sao vậy?
Bởi vì trình duyệt cần phải đệ quy đi qua cấu trúc cây CSS thì mới có thể xác định được các style ảnh hưởng đến các phần tử cụ thể được. Giờ thì tốt rồi, đã có cấu trúc DOM và CSSOM, vậy trình duyệt đã có thể xuất ra vài thứ nào đó ra cho chúng ta chưa?
6.The render tree
Hiện tại chúng ta mới chỉ có 2 cấu trúc cây độc lập, mà hình như chả có vẻ gì là có đích chung cả @@.
 Cấu trúc cây DOM và CSSOM là hai cấu trúc độc lập: Cây DOM thì chứa tất cả thông tin về các mối quan hệ của phần tử HTML của trang, trong khi CSSOM chỉ chứa thông tin về cách các phần tử được
Cấu trúc cây DOM và CSSOM là hai cấu trúc độc lập: Cây DOM thì chứa tất cả thông tin về các mối quan hệ của phần tử HTML của trang, trong khi CSSOM chỉ chứa thông tin về cách các phần tử được style mà thôi.
OK, trình duyệt giờ sẽ phải kết hợp các cây DOM và CSSOM vào làm 1, gọi là render tree.

7. Layout
Giờ đã có Render Tree rồi, việc tiếp theo sẽ là tạo 'phần khung'.
Hiện tại thì chúng ta có tất cả nội dung và thông tin style cho đám nội dung hiển thị đó, mỗi tội là vẫn chưa in ra gì lên màn hình
Việc đầu tiên là, trình duyệt cần phải tính toán kích thước và vị trí chính xác của từng đối tượng trên trang đã. Giống như kiểu đưa hết nội dung, thông tin định hình style của trang cho 1 nhà toán học, và nhà toán học đó sẽ tính toán để tìm ra vị trí và kích thước chính xác của mỗi phần tử tương ứng với khung mà chúng ta có.
Tuyệt vời, phải không?
Bước này xem xét nội dung và style nhận được từ DOM và CSSOM và thực hiện tất cả các tính toán bố cục cần thiết.
Có thể bạn cũng nghe nói đâu đó bước này được gọi là 'reflow'.
Và với các thông tin về vị trí chính xác của từng phần tử hiện đã được tính toán ở trên, việc còn lại chỉ là 'vẽ' các phần tử cho màn hình thôi, sau đó hiển thị những gì vẽ được đó cho người dùng nữa là hoàn thành
Đó! Chính xác những gì cần thiết để có thể làm hiển thị nội dung cho bạn "chỉ" như vậy thôi
Với thông tin về nội dung (DOM), style (CSSOM) và bố cục chính xác của các phần tử được tính toán, trình duyệt giờ đây sẽ "vẽ" từng node riêng lẻ ra màn hình.
Cuối cùng, các yếu tố sẽ hiện được hiển thị trên màn hình!
8. Javascript
Ờ... thế còn Javascript thì sao nhỉ? Một ứng dụng web hay ho thì chắc chắn sẽ sử dụng ít nhiều JavaScript. Nhưng mà "vấn đề" là JavaScript hoàn toàn có thể sửa đổi nội dung và style của trang, nhớ chứ?
Bằng cách nào đó, bạn có thể loại bỏ và thêm các phần tử từ cây DOM và bạn cũng có thể sửa đổi các thuộc tính CSSOM của một phần tử thông qua JavaScript.
Nghe hay thế! Xem thử ví dụ nhé:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Medium Article Demo</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<p id="header">How Browser Rendering Works</p>
<div><img src="https://i.imgur.com/jDq3k3r.jpg"></div>
</body>
</html>
File style.css khai báo như sau:
body {
background: #8cacea;
}
Kết quả là
 Một văn bản và hình ảnh đơn giản được hiển thị trên màn hình.
Một văn bản và hình ảnh đơn giản được hiển thị trên màn hình.
Như đã giải thích ở trên, trình duyệt đọc các byte raw của file html từ ổ đĩa (hoặc mạng) và biến đổi thành các ký tự, sau đó các ký tự được tiếp tục phân tích cú pháp thành các thẻ. Ngay khi trình phân tích cú pháp tiếp cận dòng <link rel="stylesheet" href="style.css">, yêu cầu được thực hiện để tìm nạp file CSS, style.css
Sau đó việc xây dựng DOM tiếp tục và ngay khi file CSS trả về với một số nội dung, quá trình xây dựng CSSOM bắt đầu.
Tuy nhiên là sẽ ra sao nếu chúng ta sử dụng thêm Javascript?
Vâng, sự thực là bất cứ khi nào trình duyệt gặp phải một thẻ script, việc xây dựng DOM bị tạm dừng! Nhớ nhé
Vậy là toàn bộ quá trình xây dựng DOM bị tạm dừng cho đến khi tập lệnh thực thi kết thúc.
 Điều này là do JavaScript có thể thay đổi cả DOM và CSSOM. Vì trình duyệt không chắc chắn Javascript này sẽ làm gì, cần phải đề phòng bằng cách tạm dừng toàn bộ quá trình xây dựng DOM.
Điều này là do JavaScript có thể thay đổi cả DOM và CSSOM. Vì trình duyệt không chắc chắn Javascript này sẽ làm gì, cần phải đề phòng bằng cách tạm dừng toàn bộ quá trình xây dựng DOM.
Xem thử ví dụ này nhé:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Medium Article Demo</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<p id="header">How Browser Rendering Works</p>
<div><img src="https://i.imgur.com/jDq3k3r.jpg"></div>
<script>
let header = document.getElementById("header");
console.log("header is: ", header);
</script>
</body>
</html>
Trong thẻ script ta đang truy cập DOM cho một nút có id là header và sau đó console.log nó.
Hiện tại thì nó vẫn hoạt động tốt, như hình dưới đây:
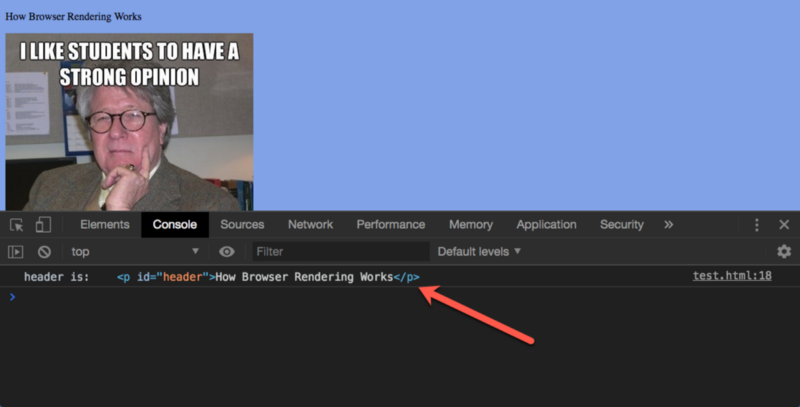
Tuy nhiên, lúc này thẻ script này đang được đặt ở cuối thẻ body thôi.
Giờ hãy đặt nó vào đầu và xem điều gì sẽ xảy ra:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Medium Article Demo</title>
<link rel="stylesheet" href="style.css">
<script>
let header = document.getElementById("header");
console.log("header is: ", header);
</script>
</head>
<body>
<p id="header">How Browser Rendering Works</p>
<div><img src="https://i.imgur.com/jDq3k3r.jpg"></div>
</body>
</html>
Bây giờ thì tạ lại nhận được null trả về???
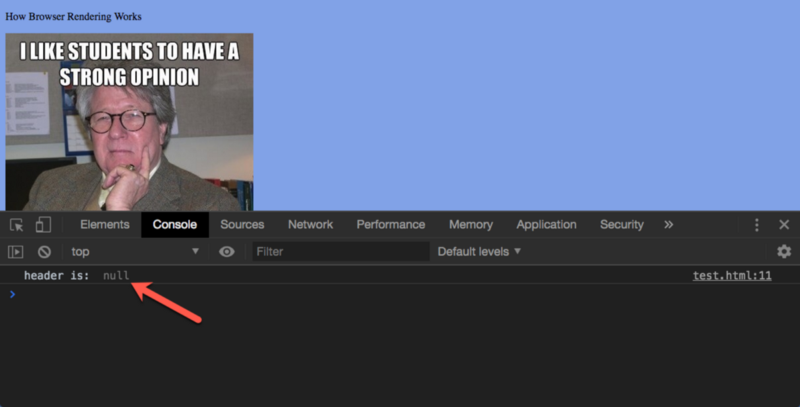
Tại sao?
Khá đơn giản.
Trong khi trình phân tích cú pháp HTML đang trong quá trình xây dựng DOM, một thẻ script đã được tìm thấy. Tại thời điểm này, thẻ body và tất cả nội dung của thẻ đã KHÔNG được phân tích cú pháp.
Việc xây dựng DOM bị tạm dừng cho đến khi quá trình thực thi của tập lệnh hoàn tất.
Vào thời điểm script cố gắng truy cập vào một nút DOM với một id là header, nó đã không tồn tại bởi vì DOM đã không hoàn thành phân tích các document!
Từ đó ta suy ra được 1 điều rất quan trọng:

9. Kết luận
Sau khi hiểu những điều cơ bản về cách thức trình duyệt của bạn được xây dựng HTML, CSS và JS, mình khuyên bạn hãy dành thời gian để khám phá làm thế nào để tận dụng kiến thức này trong việc tối ưu hóa trang web của bạn cho tốc độ hơn nhé. Cảm ơn mọi người đã đọc bài dịch của mình.
Đọc những bài viết khác của tác giả: Chillwithsu.com
Bài viết được dịch từ : https://blog.logrocket.com/how-browser-rendering-works-behind-the-scenes-6782b0e8fb10
All rights reserved
