Học thêm kiến thức về Hadoop
Bài đăng này đã không được cập nhật trong 6 năm
Hadoop là gì
Đây chắc hẳn không phải thuật ngữ gì quá xa lạ đối với các bạn làm Big data, có thể hiểu Hadoop là một tập hợp của các chương trình và quy trình nguồn mở, nó cho phép xử lý phân tán (distributed processing) các tập dữ liệu lớn trên các cụm máy tính (clusters of computers) thông qua mô hình lập trình đơn giản để đạt hiệu quả hơn cho việc vận hành Big data. Sau đây là một vài khái niệm và đặc tính cơ bản của Hadoop để giúp bạn có thể nhanh chóng hiểu được về thuật ngữ này một cách dễ dàng.
Phân tích Hadoop (HD)
HD tổng cộng có 4 module:
HDFS (Hadoop Distributed File System)
HDFS được hiểu là một hệ thống file có khả năng lưu trữ dữ liệu khủng khiếp và đồng thời giúp phân tán, ngoài ra còn có tính năng tối ưu hoá việc sử dụng băng thông giữa các node. Chính vì thế nó được sử dụng để chạy trên một cluster lớn với hàng chục ngàn node.
Bên cạnh đó, chúng ta có thể sử dụng HDFS như một ổ đĩa mà gần như không bị giới hạn về dung lượng. Nó cho phép truy xuất nhiều ổ đĩa như là 1 ổ đĩa, vì thể muốn tăng dung lượng chỉ cần thêm node vào hệ thống.
MapReduce (Hadoop MapReduce)
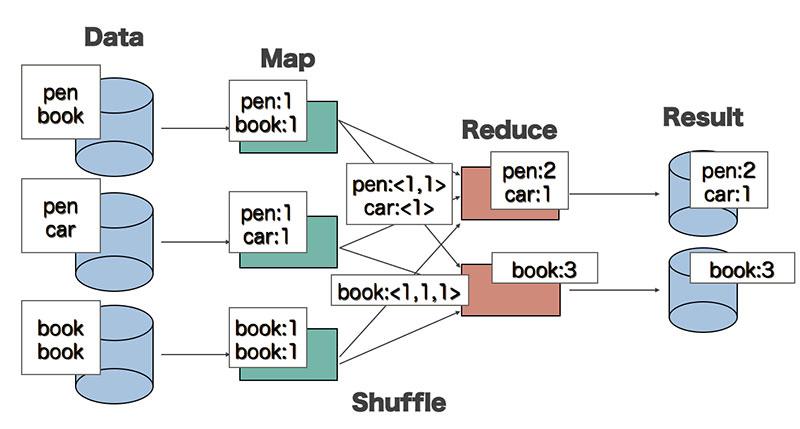
MapReduce là một framework giúp phát triển các ứng dụng phân tán theo mô hình MapReduce một cách dễ dàng và mạnh mẽ, hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn. Ngoài ra ứng dụng phân tán MapReduce có thể chạy trên một cluster lớn với nhiều node.
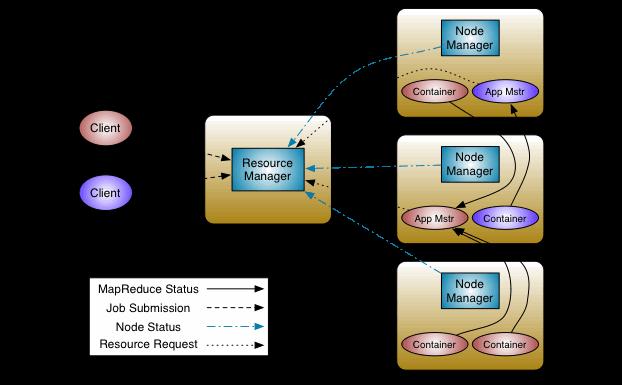
Hadoop YARN
Hadoop YARN có chức năng quản lý tài nguyên của các hệ thống lưu trữ dữ liệu và chạy phân tích. Chúng ta có thể mở rộng YARN ngoài một vài nghìn node thông qua tính năng YARN Federation. Tính năng này cho phép chúng ta buộc nhiều cụm YARN thành một cụm lớn. Điều này cho phép sử dụng các cụm độc lập, ghép lại với nhau.
Hadoop Common
Cuối cùng nhưng cũng quan trọng không kém, đây là thư viện và tiện ích cần thiết của Java để các module khác sử dụng. Những thư viện này cung cấp hệ thống file và lớp OS trừu tượng, đồng thời chứa các mã lệnh Java để khởi động Hadoop.
Ưu điểm của Hadoop
HD hỗ trợ người dùng viết và kiểm tra các hệ thống phân tán một cách nhanh chóng. Đây là cách hiệu quả cho phép phân phối dữ liệu và công việc xuyên suốt các máy trạm nhờ vào cơ chế xử lý song song của các lõi CPU.
Bên cạnh đó HD không bị phụ thuộc vào cơ chế chịu lỗi của phần cứng vì vậy bản thân Hadoop sở hữu các thư viện được thiết kế để phát hiện và xử lý các lỗi ở lớp ứng dụng.
Các server dù bị tháo gỡ nhiều lần thì vẫn hoạt động mà không bị ngắt quãng. Một lợi thế lớn của Hadoop ngoài mã nguồn mở đó là khả năng tương thích trên tất cả các nền tảng do được phát triển trên Java.
Tài liệu tham khảo
Tất cả các kiến thức trên đều được tổng hợp từ kiến thức và kinh nghiệm riêng của mình cùng với tham khảo 1 số nguồn trong và ngoài nước, để tìm hiểu nhiều hơn về HD mình để link bên dưới nhé!
hadoop.apache.org/docs/current/index.html
All rights reserved
